为什么 defer 的执行顺序和注册顺序不同?
概述
defer 语句的执行顺序是 后进先出,和数据结构中的 Stack (栈) 一样。
package main
func main() {
defer func () {
println(1)
}()
defer func () {
println(2)
}()
defer func () {
println(3)
}()
}
defer 函数的注册顺序为 1, 2, 3。
$ go run main.go
# 输出结果如下
3
2
1
defer 函数的执行顺序为 3, 2, 1。
内部实现
为什么最后的执行顺序和最初的注册顺序不一样呢?我们从源代码的角度来探究一下,defer 的实现相关文件目录为 $GOROOT/src/runtime,笔者的 Go 版本为 go1.19 linux/amd64。
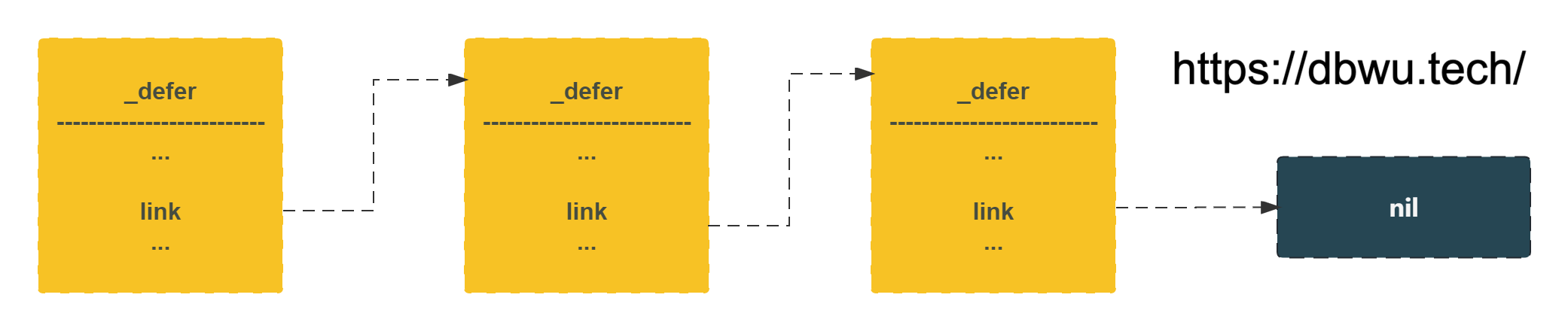
_defer 对象
_defer 对象表示 defer 语句 的运行时。
type _defer struct {
started bool // defer 语句是否已经执行
heap bool // defer 区分对象是在堆上分配还是栈上分配
sp uintptr // 调用方(调用 defer 函数)的 sp (栈底) 寄存器
pc uintptr // 调用方(调用 defer 函数)的 pc (程序计数器) 寄存器,下一条汇编指令的地址
fn func() // 传入 defer 的函数,包括函数地址及参数
_panic *_panic // 正在执行 defer 的 panic 对象
link *_defer // next defer, 链表指针,可以指向栈或者堆
}
_defer 对象链表如下所示:
deferproc 方法
deferproc 方法用于创建新的 defer 调用,编译器将 defer 语句转换为调用 deferproc 函数,生成对应函数及其参数对应的 _defer 对象,然后将其挂载到当前 G (goroutine) 的 _defer 链表上。
func deferproc(fn func()) {
// 获取当前 G
gp := getg()
d := newdefer()
if d._panic != nil {
// 新分配的 _defer 不应该产生 panic, 属于异常情况
throw("deferproc: d.panic != nil after newdefer")
}
// 新分配的 _defer 放在链表头部,达到 "后进先出" 的执行顺序
d.link = gp._defer
gp._defer = d
// 将函数赋值到 _defer 的 fn 字段
d.fn = fn
// 调用方(调用 defer 函数)的 pc (程序计数器) 寄存器,下一条汇编指令的地址
d.pc = getcallerpc()
// 不能在调用 getcallersp 函数和将返回值存储到 d.sp 期间被抢占
// 因为 getcallersp 函数的返回值是一个 uintptr 栈指针
d.sp = getcallersp()
// return0 函数由汇编实现
// 正常情况下返回 0
// 如果有捕获 panic 的 defer 函数, 返回 1
// 编译器生成的代码总是检查返回值
// 如果 deferproc 返回值不等于 0 (说明 panic 被捕获到了)
// 如果 deferproc 返回值等于 0 (说明 panic 没有被捕获)
return0()
}
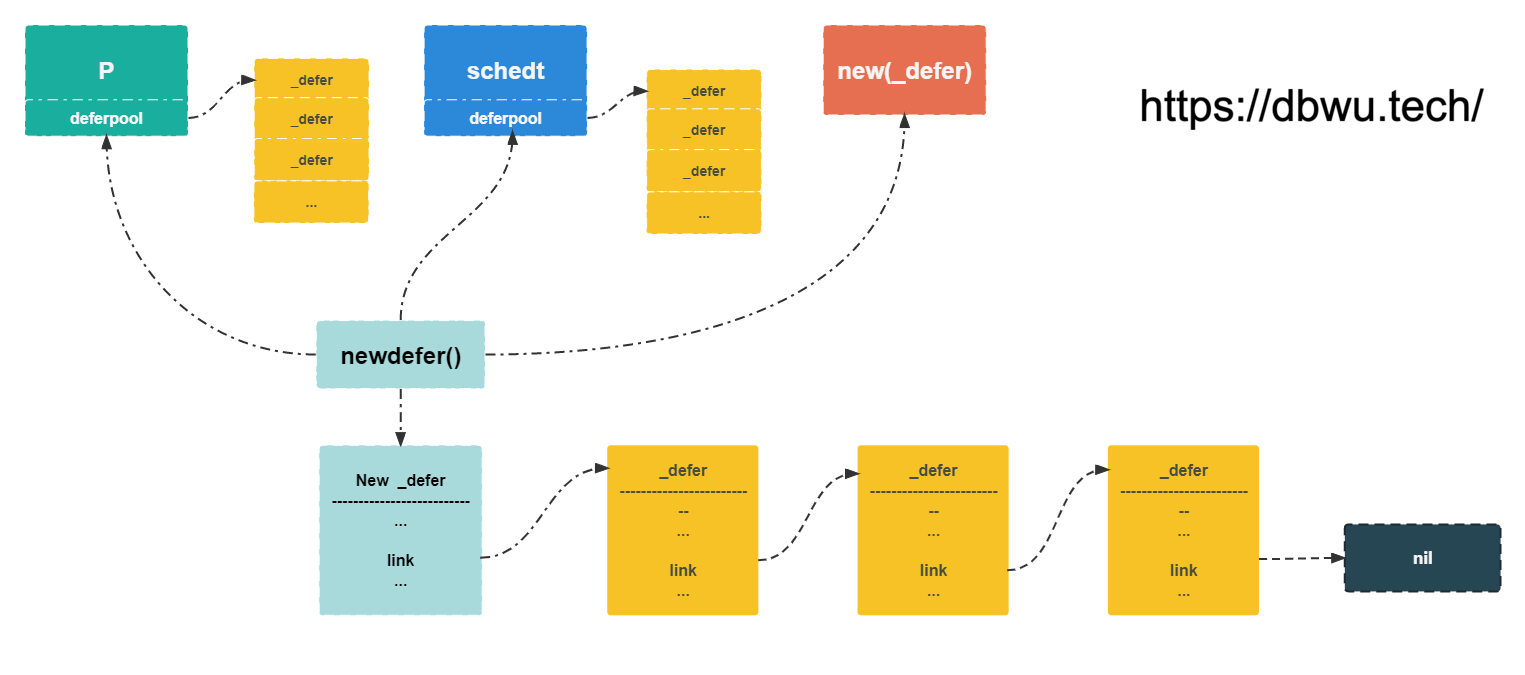
newdefer 方法
newdefer 方法用于创建一个新的 _defer 对象,并返回指向该对象的指针。
newdefer 会尽可能复用已有的 _defer 对象,优先从当前处理器 P 的 defer pool 对象池中获取,其次是调度器的 defer pool 对象池,
如果这两个地方都没有获取到,就创建一个新的 _defer 对象。
func newdefer() *_defer {
var d *_defer
// 获取当前 M
mp := acquirem()
// 获取当前 P
pp := mp.p.ptr()
// 如果 P 的对象池为空,并且调度器的对象池不为空
// 从调度器取 N 个 对象放入 P 的对象池,完成数据局部性缓存
// (其中 N 等于 P 的对象池容量的一半)
if len(pp.deferpool) == 0 && sched.deferpool != nil {
lock(&sched.deferlock)
// 将调度器对象池中一半的对象放入 P 的对象池
for len(pp.deferpool) < cap(pp.deferpool)/2 && sched.deferpool != nil {
d := sched.deferpool
sched.deferpool = d.link
d.link = nil
pp.deferpool = append(pp.deferpool, d)
}
unlock(&sched.deferlock)
}
// 如果 P 的对象池中有元素,那么取出池中最后一个元素
if n := len(pp.deferpool); n > 0 {
d = pp.deferpool[n-1]
pp.deferpool[n-1] = nil
pp.deferpool = pp.deferpool[:n-1]
}
// 消除当前 M 和 P 的引用 (优化 GC)
mp, pp = nil, nil
// 如果 P 的对象池和调度器的对象池都没有获取到对象
// 那就创建一个新的
if d == nil {
d = new(_defer)
}
// 标记对象分配到了堆上
// 和 deferprocStack 函数正好相反
d.heap = true
return d
}
deferprocStack 方法
deferprocStack 方法用于将栈上的 _defer 对象挂载到当前 G 的 _defer 链表上,参数必须初始化它的 fn 字段,其他字段都可以不设置。
由于栈上的指针未初始化, 所以进入函数之前,就已经在栈上分配好了内存结构 (编译器分配的,rsp 往下伸展即可)。
//go:nosplit
func deferprocStack(d *_defer) {
// 获取当前 G
gp := getg()
// fn 字段已经初始化
// 其他字段刚开始是未初始化的,现在进行初始化
d.started = false
// 分配到了栈上, 和 newdefer 函数正好相反
d.heap = false
// 获取到调用方函数的 rsp 寄存器值,并赋值到 _defer 结构的 sp 字段中
d.sp = getcallersp()
// 获取到调用方函数的 pc 寄存器值,并赋值到 _defer 结构的 pc 字段中
d.pc = getcallerpc()
// 下面的代码可以翻译为:
// d.panic = nil
// d.fd = nil
// d.link = gp._defer
// gp._defer = d
// 将参数 _defer 对象挂载到当前 G 的 _defer 链表上
*(*uintptr)(unsafe.Pointer(&d._panic)) = 0
*(*uintptr)(unsafe.Pointer(&d.fd)) = 0
*(*uintptr)(unsafe.Pointer(&d.link)) = uintptr(unsafe.Pointer(gp._defer))
*(*uintptr)(unsafe.Pointer(&gp._defer)) = uintptr(unsafe.Pointer(d))
return0()
}
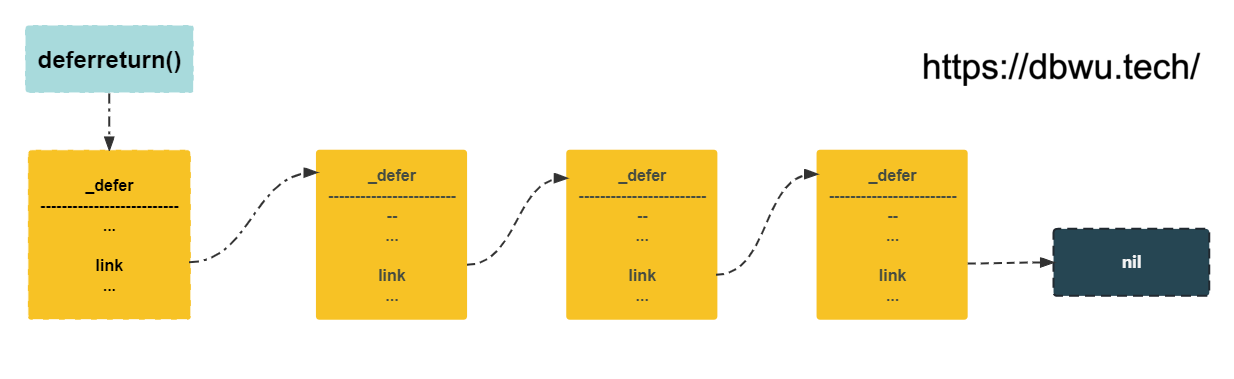
deferreturn 方法
deferreturn 方法用于运行 defer 语句函数,编译器在调用 defer 语句的函数末尾插入调用 deferreturn 函数代码。
func deferreturn() {
// 获取当前 G
gp := getg()
for {
// 获取链表头节点
d := gp._defer
// 链表已没有元素,直接返回
if d == nil {
return
}
// 获取到调用方函数的 rsp 寄存器值
sp := getcallersp()
// 如果调用方函数的 sp 和 _defer 对象的 sp 字段不同
// 说明 _defer 对象不是在调用方函数注册的 (一般是由于跨 goroutine 造成的)
if d.sp != sp {
return
}
// 获取 _defer 对象的 fn 函数地址
fn := d.fn
// 释放 _defer 对象的 fn 字段
d.fn = nil
// 从链表中删除当前节点
gp._defer = d.link
// 释放 _defer 对象内存 (归还到 P 的对象池或者调度器的对象池)
freedefer(d)
// 执行 defer 语句函数
fn()
}
}
小结
两个小问题:
- 为什么
defer的执行顺序和注册顺序不同? - 为什么
defer无法跨goroutine捕获panic?
defer 的实现由编译器和运行时共同完成,通过对内部实现源代码的学习,我们现在可以回答上面的两个小问题了。
- 新分配的
_defer结构体对象会挂载到链表头部,达到后进先出的执行顺序。 _defer结构体对象会挂载到当前的G (goroutine)上面,形成关联绑定,所以无法跨越goroutine的作用域去捕获panic。
