fastcache 高性能设计与实现
2023-07-06 Golang 并发编程 Go 源码分析 读代码
概述
fastcache 是一个线程安全并且支持大量数据存储的高性能缓存组件库。
这是官方 Github 主页上的项目介绍,和 fasthttp 名字一样以 fast 打头,作者对项目代码的自信程度可见一斑。此外该库的核心代码非常轻量,
笔者本着学习的目的分析下内部的代码实现。
基准测试
官方给出了 fastcache, bigcache, 标准库 map, sync.Map 的基准测试比较结果。
GOMAXPROCS=4 go test github.com/VictoriaMetrics/fastcache -bench='Set|Get' -benchtime=10s
goos: linux
goarch: amd64
pkg: github.com/VictoriaMetrics/fastcache
BenchmarkBigCacheSet-4 2000 10566656 ns/op 6.20 MB/s 4660369 B/op 6 allocs/op
BenchmarkBigCacheGet-4 2000 6902694 ns/op 9.49 MB/s 684169 B/op 131076 allocs/op
BenchmarkBigCacheSetGet-4 1000 17579118 ns/op 7.46 MB/s 5046744 B/op 131083 allocs/op
BenchmarkCacheSet-4 5000 3808874 ns/op 17.21 MB/s 1142 B/op 2 allocs/op
BenchmarkCacheGet-4 5000 3293849 ns/op 19.90 MB/s 1140 B/op 2 allocs/op
BenchmarkCacheSetGet-4 2000 8456061 ns/op 15.50 MB/s 2857 B/op 5 allocs/op
BenchmarkStdMapSet-4 2000 10559382 ns/op 6.21 MB/s 268413 B/op 65537 allocs/op
BenchmarkStdMapGet-4 5000 2687404 ns/op 24.39 MB/s 2558 B/op 13 allocs/op
BenchmarkStdMapSetGet-4 100 154641257 ns/op 0.85 MB/s 387405 B/op 65558 allocs/op
BenchmarkSyncMapSet-4 500 24703219 ns/op 2.65 MB/s 3426543 B/op 262411 allocs/op
BenchmarkSyncMapGet-4 5000 2265892 ns/op 28.92 MB/s 2545 B/op 79 allocs/op
BenchmarkSyncMapSetGet-4 1000 14595535 ns/op 8.98 MB/s 3417190 B/op 262277 allocs/op
从测试的结果中可以看到:
fastcache在所有操作上都要比bigcache快fastcache在只写 + 读写混合操作比标准库的map, sync.Map要快,只读操作比后者要慢
组件特性
- 高性能
- 线程安全
- 设计为存储大量数据 (没有 GC 开销)
- 自动删除比较旧数据
- 使用简单
- 源代码简单且非常轻量
- 缓存数据可以保存到文件,也可以从文件中加载
示例
package main
import (
"fmt"
"github.com/VictoriaMetrics/fastcache"
)
func main() {
// 初始化一个大小为 32MB 的缓存
cache := fastcache.New(32 * 1024 * 1024)
key := []byte(`hello`)
val := []byte(`world`)
cache.Set(key, val) // 设置 K-V
fmt.Println(cache.Has(key)) // true
fmt.Println(cache.Has([]byte(`hello2`))) // false
fmt.Printf("hello = %s\n", cache.Get(nil, key)) // hello= world
cache.Del(key)
fmt.Println(cache.Has(key)) // fasle
}
从示例代码可以看到,除了初始化时需要指定缓存的大小,组件提供的 API 就是常规的 “键值对” 语义操作,例如 Get, Set, Del 等。
源码分析
笔者选择的 fastcache 版本为 v1.12.1。
哈希算法
fastcache 库内部采用的哈希算法为 XXH64。
XXH64 算法是一种非常快速的哈希算法,它能够利用 RAM 的速度限制工作,采用 64 位计算进行处理,能够生成 64 位哈希值。 XXH64 算法的优点在于高度可移植性,可以在不同平台上生成相同的哈希值,适用于高性能的哈希表、数据结构和验证测试等场景。
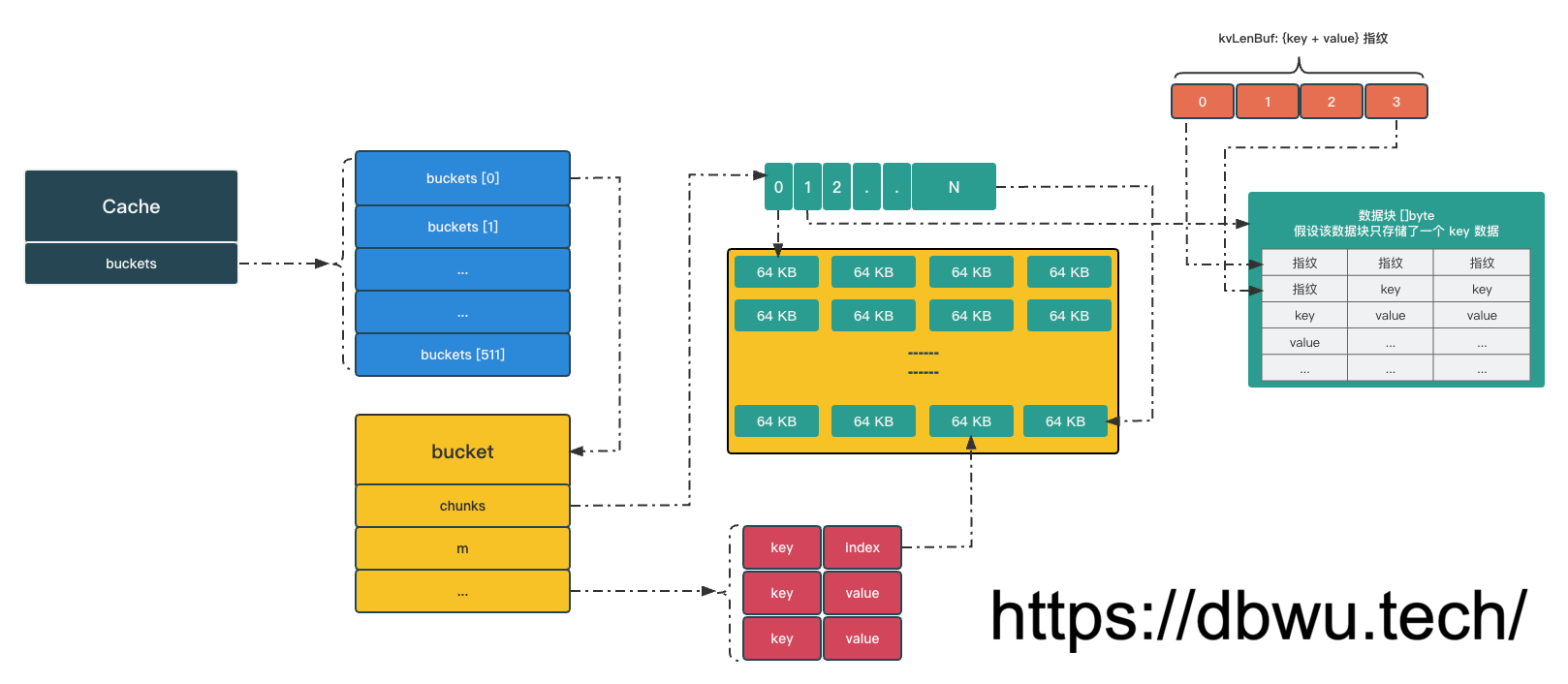
数据结构
常量
因为 桶的大小 和 桶的数据存储重写次数 两个字段存储在一个变量中 (可以并发原子操作),所以这里使用两个常量来区分这两个字段各自的字节数。
// 每个缓存中的桶数量
const bucketsCount = 512
// 每个桶中的单个数据块大小 64KB
const chunkSize = 64 * 1024
// 桶的大小 (用变量的前 40 位表示)
const bucketSizeBits = 40
// 桶的数据存储环形缓冲区的重写次数 (用变量的后 24 位表示)
const genSizeBits = 64 - bucketSizeBits
// 桶的数据存储最大重写次数
const maxGen = 1<<genSizeBits - 1
// 单个桶的大小上限
const maxBucketSize uint64 = 1 << bucketSizeBits
Cache 对象
Cache 用来表示 缓存对象,包含了 2 个字段:
- 用于存储数据的 bucket 桶,数据结构是数组,固定长度 512
- 用于表示
GetBig/SetBig(针对大数据读写) 方法调用的统计信息
type Cache struct {
buckets [bucketsCount]bucket
bigStats BigStats
}
bucket 桶
bucket 桶负责具体数据的获取和存储,每个桶的数据存放量是根据 缓存的数据总量 平均计算得出的 (例如总量为 2GB, 那么每个桶的数据就是 4MB)。
type bucket struct {
// 读写锁,涉及到并发操作时使用
mu sync.RWMutex
// 存放数据的二维数组,是一个环形缓冲区 (也可以理解为一个环形链表)
// 由 65536 个数据块组成
chunks [][]byte
// 数据哈希索引
// 用于快速为指定 key 找到对应的存储位置
m map[uint64]uint64
// 数据索引计数器
idx uint64
// 表示二维数组被重写的次数
// 用于校验环形缓冲区的数据有效性
gen uint64
// Get 操作次数
getCalls uint64
// Set 操作次数
setCalls uint64
// 未命中次数
misses uint64
// 哈希碰撞次数
collisions uint64
// 数据异常次数
corruptions uint64
}
数据结构图
方法
创建缓存对象
New 根据容量参数创建一个缓存对象并返回。
// maxBytes 最小为 32 MB, 最大不能超过可用内存大小
func New(maxBytes int) *Cache {
...
var c Cache
// 根据容量大小和桶的数量 (固定为 512) 计算单个桶的容量
// (maxBytes + bucketsCount - 1) 等于容量不能整除 512 的部分
maxBucketBytes := uint64((maxBytes + bucketsCount - 1) / bucketsCount)
for i := range c.buckets[:] {
// 逐个初始化桶
c.buckets[i].Init(maxBucketBytes)
}
return &c
}
桶初始化
func (b *bucket) Init(maxBytes uint64) {
...
// 根据桶容量大小和数据块数量 (固定为 64KB) 计算单个数据块大小
maxChunks := (maxBytes + chunkSize - 1) / chunkSize
// 初始化数据块二维数组
b.chunks = make([][]byte, maxChunks)
// 初始化哈希索引
b.m = make(map[uint64]uint64)
// 桶重置
b.Reset()
}
桶重置
func (b *bucket) Reset() {
b.mu.Lock()
chunks := b.chunks
for i := range chunks {
// 归还数据块到全局空闲区 (空闲区持有该数据块指针)
putChunk(chunks[i])
// 重置数据块中的数据 (避免后面被复用时产生垃圾数据问题)
chunks[i] = nil
}
// 重新初始化哈希索引 (可以重建 map 底层数据结构,提升性能)
b.m = make(map[uint64]uint64)
// 重置其他字段
b.idx = 0
b.gen = 1
atomic.StoreUint64(&b.getCalls, 0)
atomic.StoreUint64(&b.setCalls, 0)
atomic.StoreUint64(&b.misses, 0)
atomic.StoreUint64(&b.collisions, 0)
atomic.StoreUint64(&b.corruptions, 0)
b.mu.Unlock()
}
Set 操作
Set 操作分成两部分完成,首先计算出指定 key 所在的桶,然后将 value 存入对应的桶中。
func (c *Cache) Set(k, v []byte) {
// 计算哈希值
h := xxhash.Sum64(k)
// 计算桶的索引
idx := h % bucketsCount
// 将 value 存入对应的桶中
c.buckets[idx].Set(k, v, h)
}
func (b *bucket) Set(k, v []byte, h uint64) {
// Set 操作次数 + 1
atomic.AddUint64(&b.setCalls, 1)
if len(k) >= (1<<16) || len(v) >= (1<<16) {
// key 或 value 的长度超过 65536
// 此时已经调用 SetBig 方法
// 直接返回
return
}
// 计算 key + value 存储所需空间大小
// kvLenBuf 表示 {key + value} 的指纹
var kvLenBuf [4]byte
kvLenBuf[0] = byte(uint16(len(k)) >> 8)
kvLenBuf[1] = byte(len(k))
kvLenBuf[2] = byte(uint16(len(v)) >> 8)
kvLenBuf[3] = byte(len(v))
kvLen := uint64(len(kvLenBuf) + len(k) + len(v))
if kvLen >= chunkSize {
// key + value 的空间大小超过单个数据块限制 (64K)
return
}
// 桶的数据块
chunks := b.chunks
// 哈希索引是否需要重建标志位 (取决于环形缓冲区是否重写了)
needClean := false
// 操作加锁,注意这里是互斥锁
b.mu.Lock()
// 当前索引计数器
idx := b.idx
// 更新计数器
idxNew := idx + kvLen
// 当前计数器 / 单个数据块大小 = 当前数据块的索引
chunkIdx := idx / chunkSize
// 更新后的计数器 / 单个数据块大小 = 下一个数据块的索引
chunkIdxNew := idxNew / chunkSize
if chunkIdxNew > chunkIdx {
// 如果下一个数据块的索引 大于 当前数据块的索引
// 说明存储的 key 和 value 的数据跨了两个数据块
if chunkIdxNew >= uint64(len(chunks)) {
// 如果下一个数据块的索引 大于 数据块的数量
// 说明所有数据块已全部使用
// 此时采用环形缓冲区的方式: 从头开始存储数据
// 重置索引计数器
idx = 0
// 更新计数器
idxNew = kvLen
// 从第一个数据块开始
chunkIdx = 0
// 重写的次数 + 1
b.gen++
if b.gen&((1<<genSizeBits)-1) == 0 {
// 重写次数达到上限
b.gen++
}
// 更新哈希索引重建标志位
needClean = true
} else {
// 如果数据块还有剩余空间可供使用
// 当前索引计数器
idx = chunkIdxNew * chunkSize
// 更新索引计数器
idxNew = idx + kvLen
// 更新数据块索引
chunkIdx = chunkIdxNew
}
// 重置数据块里的数据
chunks[chunkIdx] = chunks[chunkIdx][:0]
}
chunk := chunks[chunkIdx]
if chunk == nil {
// 从全局空闲区获取一个数据块
chunk = getChunk()
// 重置数据块里的数据
chunk = chunk[:0]
}
// 指纹写入数据块
chunk = append(chunk, kvLenBuf[:]...)
// key 写入数据块
chunk = append(chunk, k...)
// value 写入数据块
chunk = append(chunk, v...)
// 更新数据块信息
chunks[chunkIdx] = chunk
// 更新数据哈希索引
b.m[h] = idx | (b.gen << bucketSizeBits)
// 更新索引计数器
b.idx = idxNew
if needClean {
// 如果缓冲区重写了,重新解析和构建数据哈希索引
b.cleanLocked()
}
// 操作解锁
b.mu.Unlock()
}
Get 操作
Get 操作分成两部分完成,首先计算出指定 key 所在的桶,然后从桶中获取对应的 value, 作为可选性,调用方可以将接收 value 的变量作为第一个参数传入 (复用 []byte, 节省内存)。
// 如果 dst 参数为 nil, 返回的结果变量为新创建的 []byte
// 如果 dst 参数不为 nil, 返回的结果直接写入 dst 参数变量
func (c *Cache) Get(dst, k []byte) []byte {
// 计算哈希值
h := xxhash.Sum64(k)
// 计算桶的索引
idx := h % bucketsCount
// 从对应的桶中获取 value
dst, _ = c.buckets[idx].Get(dst, k, h, true)
return dst
}
func (b *bucket) Get(dst, k []byte, h uint64, returnDst bool) ([]byte, bool) {
// Get 操作次数 + 1
atomic.AddUint64(&b.getCalls, 1)
// 是否获取 key 对应的 value
found := false
// 桶的数据块
chunks := b.chunks
// 操作加锁,注意这里是读写锁
b.mu.RLock()
// 获取指定数据的哈希索引
v := b.m[h]
// 获取环形缓冲区重写次数
bGen := b.gen & ((1 << genSizeBits) - 1)
// 如果 v 小于等于 0,说明没有对应的 key
// 直接跳转到 end label 返回即可
if v > 0 {
// 获取索引写入后,环形缓冲区重写次数
gen := v >> bucketSizeBits
// 获取数据位置的哈希索引
idx := v & ((1 << bucketSizeBits) - 1)
// 分别说下这 3 个判断条件:
// gen == bGen && idx < b.idx
// 说明该索引写入后,缓冲区没有发生过重写,并且哈希索引没有越界
// gen+1 == bGen && idx >= b.idx
// 说明该索引写入后,虽然缓冲区被重写过 1 次,但是当前数据还没有被重写
// gen == maxGen && bGen == 1 && idx >= b.idx
// 说明该索引写入后,虽然缓冲区已达到重写次数上限并且进行了重建,但是当前数据还没有被重写
// 符合上述 3 个条件之一,说明对应的数据没有受到影响,可以正常使用
if gen == bGen && idx < b.idx || gen+1 == bGen && idx >= b.idx || gen == maxGen && bGen == 1 && idx >= b.idx {
// 计算数据块索引
chunkIdx := idx / chunkSize
if chunkIdx >= uint64(len(chunks)) {
// 如果数据块索引 大于 数据块数量 (发生了越界,说明指纹信息错误)
// 数据异常次数 + 1
// 直接返回
atomic.AddUint64(&b.corruptions, 1)
goto end
}
chunk := chunks[chunkIdx]
idx %= chunkSize
if idx+4 >= chunkSize {
// 如果数据索引 大于 数据块长度 (发生了越界,说明指纹信息错误)
// 数据异常次数 + 1
// 直接返回
atomic.AddUint64(&b.corruptions, 1)
goto end
}
// 根据指纹分别计算 key 和 value 对应的位置
kvLenBuf := chunk[idx : idx+4]
keyLen := (uint64(kvLenBuf[0]) << 8) | uint64(kvLenBuf[1])
valLen := (uint64(kvLenBuf[2]) << 8) | uint64(kvLenBuf[3])
// 更新索引值,开始获取 {key + value} 数据
idx += 4
if idx+keyLen+valLen >= chunkSize {
// 如果 {key + value} 数据长度 大于 单个数据块长度 (发生了越界,说明指纹信息错误)
// 数据异常次数 + 1
// 直接返回
atomic.AddUint64(&b.corruptions, 1)
goto end
}
// 如果参数 key 和指纹中存储的 key 相同
// 说明参数 key 对应的 value 找到了,否则就是产生了哈希碰撞
if string(k) == string(chunk[idx:idx+keyLen]) {
idx += keyLen
if returnDst {
dst = append(dst, chunk[idx:idx+valLen]...)
}
found = true
} else {
// 哈希碰撞次数 + 1
atomic.AddUint64(&b.collisions, 1)
}
}
}
end:
// 操作解锁
b.mu.RUnlock()
if !found {
// 未命中次数 + 1
atomic.AddUint64(&b.misses, 1)
}
return dst, found
}
桶的哈希缓存重建
func (b *bucket) cleanLocked() {
// 获取环形缓冲区重写次数
bGen := b.gen & ((1 << genSizeBits) - 1)
// 获取索引计数器
bIdx := b.idx
// 获取数据哈希索引
bm := b.m
for k, v := range bm {
// 获取索引写入后,环形缓冲区重写次数
gen := v >> bucketSizeBits
// 获取数据位置的哈希索引
idx := v & ((1 << bucketSizeBits) - 1)
// 如果对应数据没有受到缓冲区重写的影响,就跳过
// 否则就将数据的哈希索引删除
if (gen+1 == bGen || gen == maxGen && bGen == 1) && idx >= bIdx || gen == bGen && idx < bIdx {
continue
}
delete(bm, k)
}
}
调用关系图
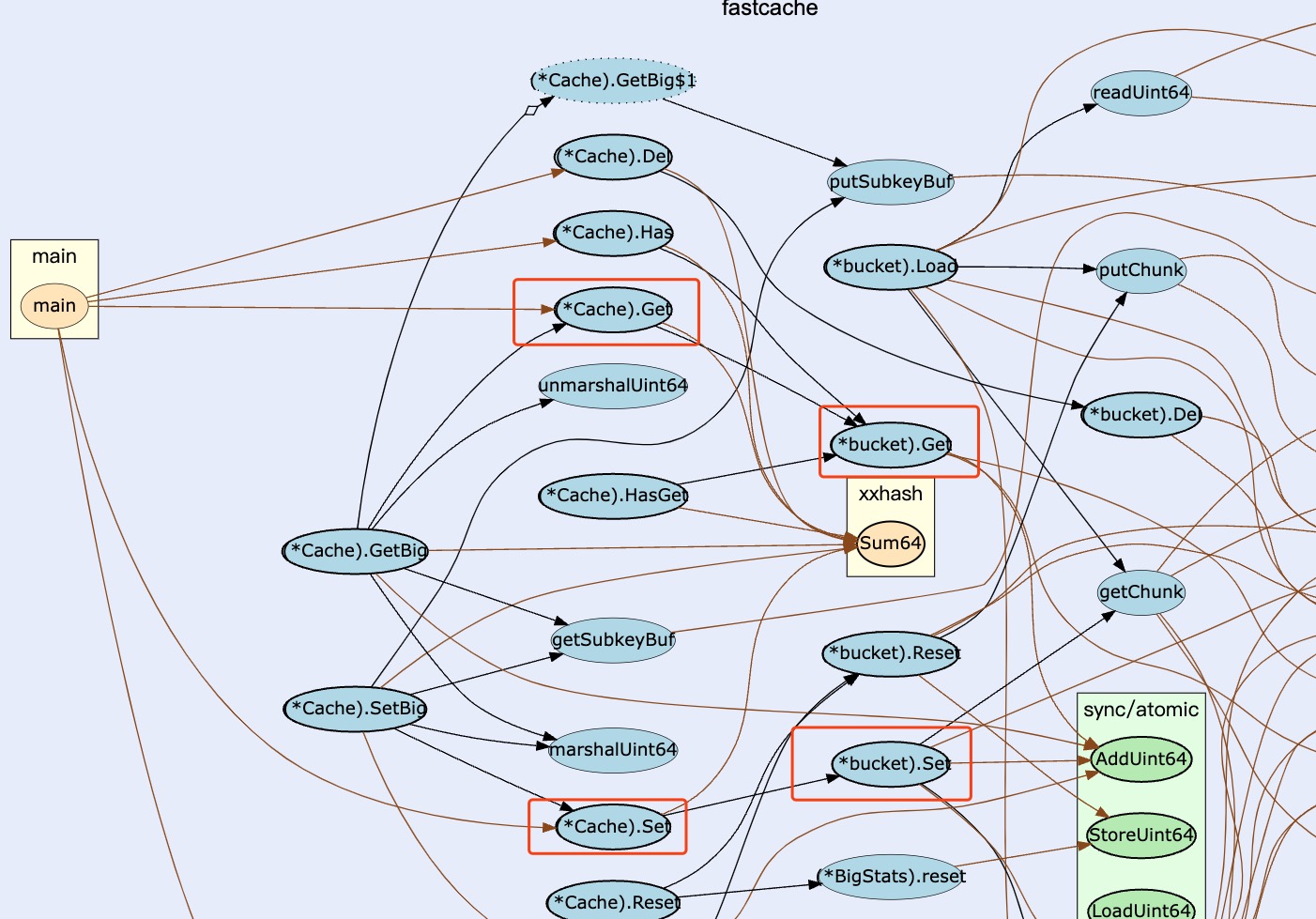
高性能设计细节
fastcache 采用类似 bigcache 的设计思路:
缓存由许多桶组成,每个桶都持有一个锁 (分段锁),这样可以提高多核 CPU 的性能,因为多个 CPU 可以同时访问不同的桶- 每个桶由一个哈希索引 (数据块的位置) 和 65536 个数据块组成,每个桶的指针数量最多为
桶的存储容量 / 64KB(这里指 bucket.chunks 字段)。 例如,64GB 缓存将包含大约 1M 指针,而类似大小的 map[string][]byte 将包含大约 1B 指针,这将导致巨大的 GC 开销
从设计上来说,和每个桶持有一个大的数据块相比,fastcache 采用的 64KB 的数据块减少了内存碎片和总内存使用量。
此外当从 全局数据块空闲区 获取数据块时,会直接调用 Mmap 分配到堆外内存,减少了总内存使用量,因为 GC 会更频繁地收集未使用的内存,无需调整 GOGC。
使用约束和限制
fastcache 组件库的使用有 4 个约束条件,在技术选型的时候比较重要,不过从下面的 4 点要求来看,实际应用中可以通过设计合理的数据类型来规避这些约束条件。
- 缓存数据的
key和value数据类型必须是[]byte, 如果是其他类型,必须在存储前转换为[]byte - 缓存数据大小超过
64K, 必须调用SetBig方法存储 - 缓存数据没有过期时间,只有当缓存数据的数量溢出时,才会删除比较旧的数据,通用的实践是将过期时间存入数据中
- 缓存数据采用
环形缓冲区存储,这意味着数据量过大的情况下,新的数据会重写并覆盖掉旧的数据
此外值得注意的是,Set 方法并没有返回值来表示操作的执行结果,这种设计丢失了方法语义,并且在某些极端情况下造成难以排查的 Bug。
小结
本文主要分析了 fastcache 组件的缓存设计与实现,我们可以从中学习到 3 个非常重要的设计技巧: 采用分段锁降低锁的粒度, 采用指纹 + 哈希索引快速定位数据位置, map 使用 [uint64]uint32 作为非指针优化从而避免 GC,
在组件的基础上,也许我们可以进一步优化 (例如将桶的锁粒度细化到数据块)?感兴趣的读者可以通过修改源代码进行测试 (毕竟 fastcache 的源代码非常轻量)。
此外需要注意的是,fastcache 提供的 Get, Set 方法参数类型都是 []byte, 这意味着在调用方法前,必须现将具体的数据类型或对象转换为 []byte, 这会带来额外的 CPU 消耗。
最后,fastcache 提供的 缓存数据 <=> 文件 写入和加载功能以及 全局数据块空闲区,由于时间关系,本文不再分析其具体代码实现。
