GMP Scheduler Code Reading
2023-06-09 Golang 并发编程 Go 源码分析 读代码
概述
G: 表示
goroutineM: 表示 操作系统的
线程P: 表示
处理器,运行在线程上的本地调度器
内部实现
本文主要研究一下 GMP 调度器的内部实现,相关文件目录为 $GOROOT/src/runtime,笔者的 Go 版本为 go1.19 linux/amd64。
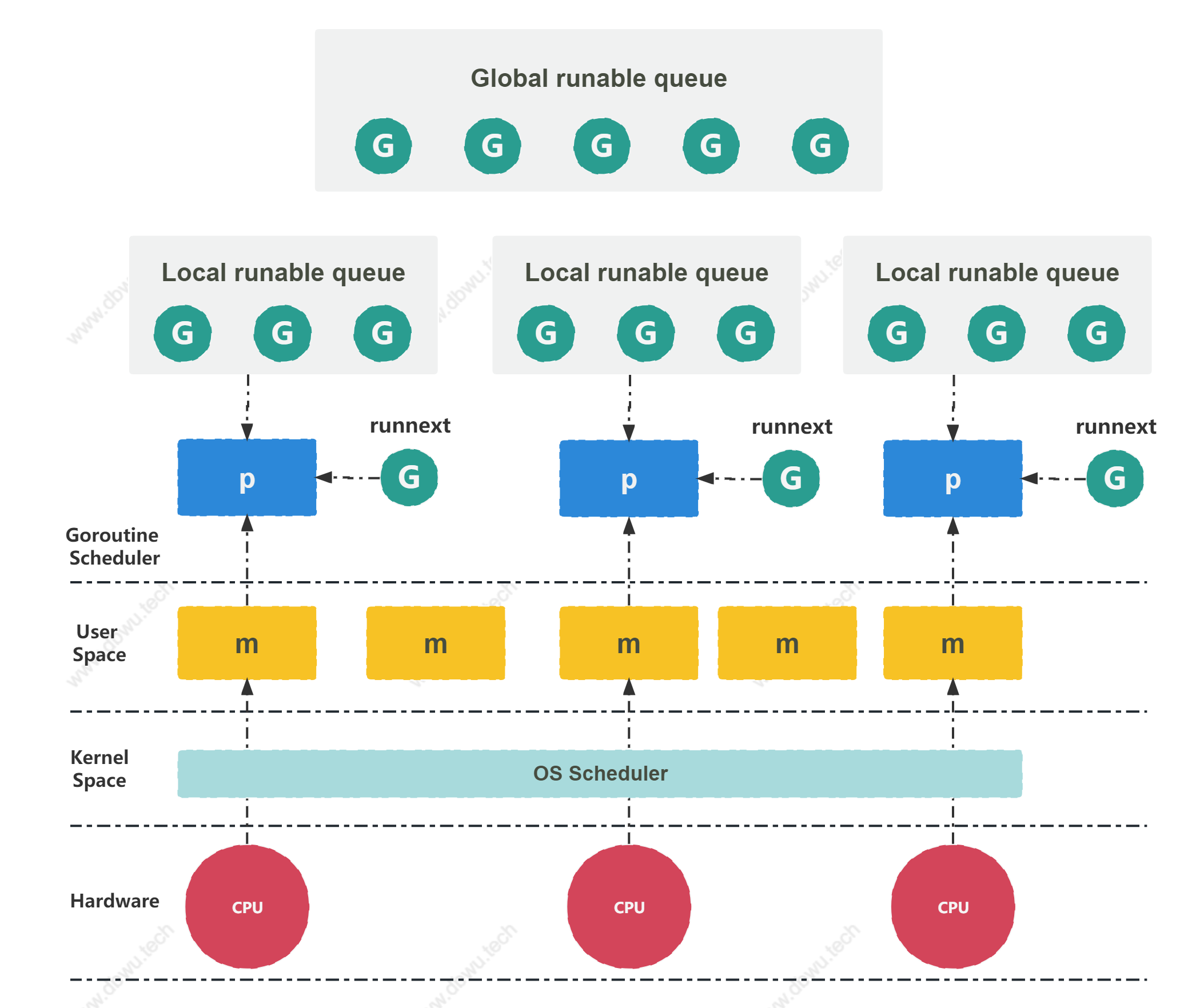
GMP 数据结构
G M P 相关的数据结构定义,全部定义在 $GOROOT/src/runtime/runtime2.go 文件中。
G
goroutine 只存在于 Go 语言的运行时,是 Go 语言在用户态提供的线程,但是内存占用和上下文切换开销更少,同时启动速度更快。 作为一种粒度更细的资源调度单元,能够在高并发的场景下更高效地利用机器的 CPU 资源。
stack 对象
stack 对象表示 goroutine 执行栈内存范围,栈的上下边界分别是 [lo, hi), 两侧没有隐式的数据结构 (有些运行时对象会有隐式数据结构)。
type stack struct {
lo uintptr
hi uintptr
}
g 对象
goroutine的运行时表示。
type g struct {
// stack 描述了栈的实际上下边界 [stack.lo, stack.hi)
// stackguard0 是在 Go 栈增长 prologue 中用来和 sp 寄存器做比较
// 正常情况下,stackguard0 = stack.lo+StackGuard, 但是可以用 StackPreempt 触发抢占
// stackguard1 是在 C 栈增长 prologue 中用来和 sp 寄存器做比较
// 在 g0 和 gsignal 栈上,stackguard1 = stack.lo+StackGuard
// 在其他栈上,stackguard1 = ~0 (按 0 取反), 触发 morestack 调用(并 crash)
stack stack
stackguard0 uintptr
stackguard1 uintptr
_panic *_panic // _panic 链表头节点
_defer *_defer // _defer 链表头节点
m *m // 当前关联的 m (线程)
sched gobuf // goroutine 调度相关数据
...
atomicstatus uint32 // goroutine 状态
stackLock uint32 // sigprof/scang lock
goid int64 // goroutine ID (对应用层不可见,但是可以通过其他方法获取到,详情见 #扩展阅读)
...
preempt bool // 抢占信号
preemptStop bool // 抢占时将状态修改成 _Gpreempted
preemptShrink bool // 在同步安全的临界区收缩栈
...
}
sudog 对象
sudog 对象表示等待队列里面的 goroutine 对象, 比如向 channel 发送/接收数据时。
sudog 对象主要作为一层中间抽象层,因为 goroutine 和同步对象之间是多对多关系,一个 goroutine 可能在多个等待队列中,可以有多个 sudog,
同时,多个 goroutine 也可能在等待同一个同步对象,一个对象可以有多个 sudog。
为了提升程序的运行时性能,sudog 对象从一个特殊的对象池中分配,调用 acquireSudog 函数分配,releaseSudog 函数归还。
type sudog struct {
g *g
next *sudog
prev *sudog
acquiretime int64
releasetime int64
ticket uint32
// isSelect 表示一个 g 是否正处于 select
isSelect bool
// 如果 goroutine 因为 channel c 传递值被唤醒,success 的值为 true
// 如果 goroutine 因为 channel c 关闭被唤醒,success 的值为 false
success bool
...
}
gobuf 对象
gobuf 对象表示 goroutine 的运行现场表示,该对象在调度器保存数据或者恢复上下文的时候用到,sp 和 pc 寄存器字段用来存储或者恢复寄存器中的值,改变程序即将执行的代码。
type gobuf struct {
sp uintptr // sp 寄存器
pc uintptr // pc 寄存器
g guintptr // goroutine 对象指针
ret uintptr // 系统调用返回值
lr uintptr // arm 上用的寄存器,amd64 忽略
}
状态列表
goroutine 的状态列表,最常见是 _Grunnable, _Grunning, _Gwaiting。
const (
// goroutine 刚被分配并且还没有被初始化
_Gidle = iota // 0
// goroutine 处于运行队列中,没有在执行代码,没有栈的所有权
_Grunnable // 1
// goroutine 可以执行代码并且拥有有栈的所有权,M 和 P 已经设置并且有效
_Grunning // 2
// goroutine 正在执行系统调用,没有在执行代码,拥有栈的所有权但是不在运行队列中,此外,M 已经设置
_Gsyscall // 3
// goroutine 处于阻塞中,没有在执行代码并且不在运行队列中,但是可能存在于 Channel 的等待队列上
_Gwaiting // 4
// 没有使用这个状态,但是被硬编码到了 gbd 脚本中
_Gmoribund_unused // 5
// goroutine 没有被使用 (可能已经退出或刚刚初始化),没有在执行代码,可能存在分配的栈
_Gdead // 6
// 没有使用这个状态
_Genqueue_unused // 7
// goroutine 的栈正在被移动,没有在执行代码并且不在运行队列中
_Gcopystack // 8
// goroutine 由于抢占而阻塞,等待唤醒
_Gpreempted // 9
// GC 正在扫描栈空间,没有在执行代码,可以与上述其他状态同时存在
_Gscan = 0x1000
// 下面几个是组合状态
_Gscanrunnable = _Gscan + _Grunnable // 0x1001
_Gscanrunning = _Gscan + _Grunning // 0x1002
_Gscansyscall = _Gscan + _Gsyscall // 0x1003
_Gscanwaiting = _Gscan + _Gwaiting // 0x1004
_Gscanpreempted = _Gscan + _Gpreempted // 0x1009
)
M
调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(例如陷入系统调用或 IO 调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行。 在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数,我们也可以在程序中使用 runtime.GOMAXPROCS 来改变最大的活跃线程数。
三种类型
- 主线程 m : 全局变量
runtime.m0表示 (全局只有一个实例) - sysmon m : 监控线程 (全局只有一个实例)
- 用户线程 m : 和处理器
p绑定,执行具体的goroutine逻辑代码
m 对象
线程的运行时表示。
type m struct {
g0 *g // 执行调度的 goroutine
...
curg *g // 当前运行的 goroutine
p puintptr // 正在运行代码的处理器 (如果为 nil, 说明当前没有代码运行)
nextp puintptr // 暂存的处理器
oldp puintptr // 执行系统调用之前使用线程的处理器
id int64 // ID
preemptoff string // 如果不为空,保持当前 goroutine 在这个 m 上运行
spinning bool // m 正在积极寻找活儿干
blocked bool // m 阻塞在 note
incgo bool // m 正在执行 cgo 调用
ncgocall uint64 // cgo 调用总次数
ncgo int32 // 当前正在运行的 cgo 调用次数
...
}
P
处理器是线程和 goroutine 的中间层,提供线程需要的上下文环境,负责调度线程上的等待队列,通过处理器 P 的调度, 每一个内核线程都能够执行多个 goroutine,它能在 goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的资源利用率。
p 对象
处理器(p)的运行时表示,线程(m)必须持有 (绑定)p才可以运行goroutine。
type p struct {
id int32 // ID
status uint32 // p 的状态
schedtick uint32 // 调度时自增
syscalltick uint32 // 系统调用时自增
sysmontick sysmontick // sysmon 最后观察到的 tick 时间
m muintptr // 关联的 m 的指针,如果 p 处于空闲状态,指针为 nil
...
deferpool []*_defer // 可用的 _defer 对象池
deferpoolbuf [32]*_defer // _defer 对象池
goidcache uint64 // 缓存 goroutine ID, 优化 runtime·sched.goidgen
// goroutine 运行队列,访问时无需加锁
runqhead uint32 // runnable 队列头索引
runqtail uint32 // runnable 队列尾索引
runq [256]guintptr // runnable 队列 (环形队列,数据结构为数组,元素数量最多为 256)
// runnext 如果不等于 nil, 表示下一个可运行的 goroutine
// 说明它已经被当前 goroutine 修改为 ready 状态,并且比队列中的其他 goroutine 拥有更高的优先级
// 如果运行 goroutine 对应的时间片中还有剩余的时间,那么直接运行这个 goroutine,而不是放入队列中
runnext guintptr
...
}
状态列表
const (
// 处理器没有在执行代码或者调度,处于空闲状态
_Pidle = iota // 0
// 处理器被线程 M 持有,并且正在执行代码或者调度
_Prunning // 1
// 处理器没有在执行代码,线程陷入系统调用
_Psyscall // 2
// 处理器被线程 M 持有,由于 GC 被停止
_Pgcstop // 3
// 处理器不再被使用
_Pdead // 4
)
GMP 数据结构关系图
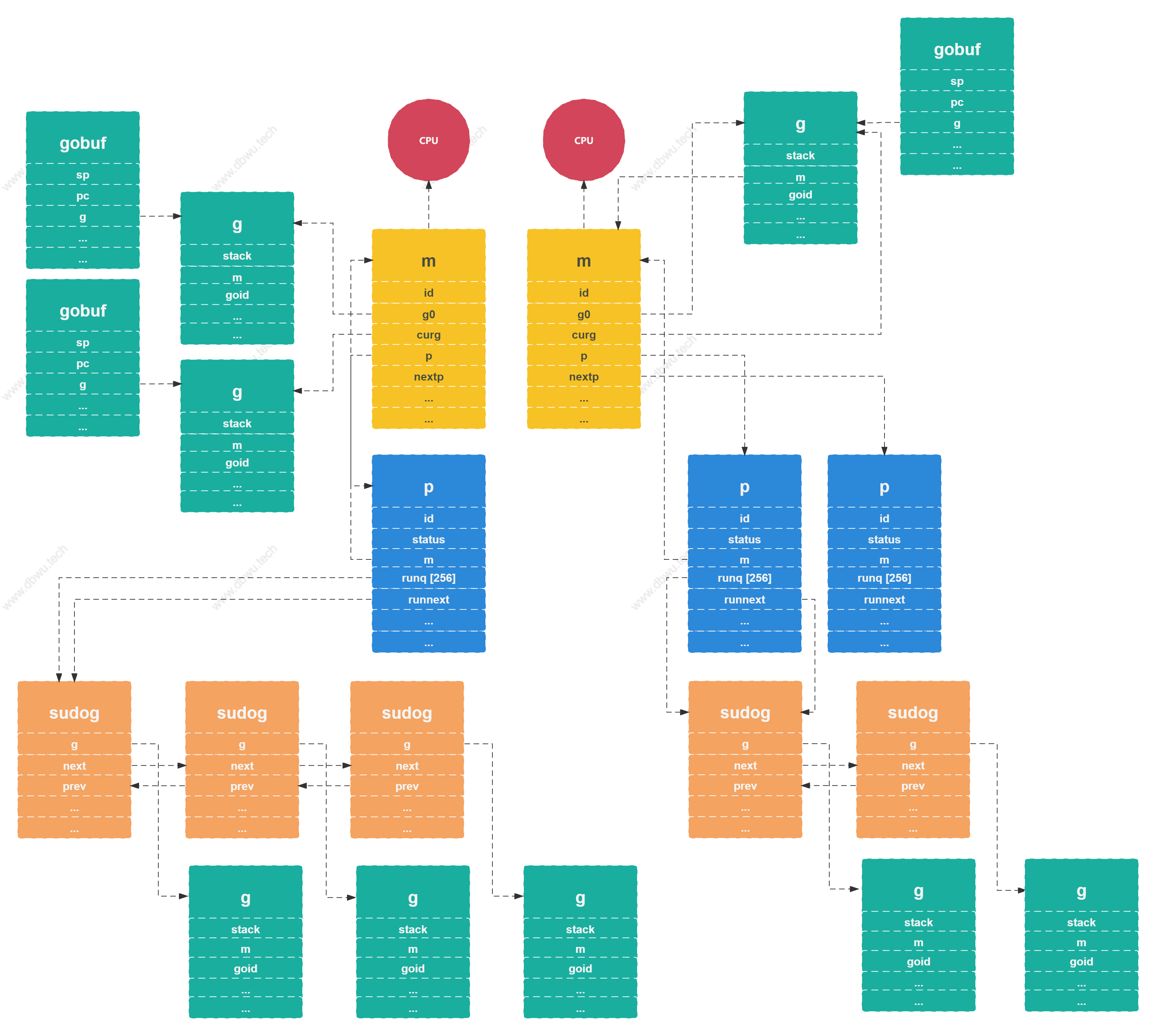
小结
上文主要对 GMP 调度中的数据结构部分做了简单的概述:
g对象表示goroutine, 是用来执行具体的任务的 (也就是干活的)m对象表示线程, 和真正的操作系统线程绑定之后,就可以执行具体的goroutine代码了p表示处理器,作为抽象中间层用来管理goroutine队列以及调度goroutine到具体的m上执行
除此之外:
sudog对象包装了一层g, 用来表示在队列中等待的goroutine对象gobuf对象包装了一层g, 用来表示goroutine的运行现场,在调度器保存数据或者恢复上下文的时候可以用到
最后,我们列出了 g 和 p 对象的不同状态值,这些值在程序整个生命周期内的调度过程中都会使用到。
调度器数据结构
schedt 对象
schedt 对象是全局调度器的运行时表示,全局只有一个 schedt 对象实例,定义在 $GOROOT/src/runtime/runtime2.go 文件中。
type schedt struct {
goidgen uint64 // 原子性访问,保持在 struct 顶部,确保 32 位系统上对齐
lastpoll uint64 // network poll 的最后时间,如果为 0, 说明正在 poll
pollUntil uint64 // 当前 poll 的休眠时间
lock mutex
// 增加 nmidle, nmidlelocked, nmsys, nmfreed 这几个值的时候, 确保调用 checkdead()
midle muintptr // 空闲的 m 队列
nmidle int32 // 空闲的 m 数量
nmidlelocked int32 // 空闲的被锁住的 m 数量
mnext int64 // 预创建的 m 数量,该数量会作为下一个创建的 m 的 ID
maxmcount int32 // 允许的 m 数量上限
nmsys int32 // 因为死锁未计算的系统 m 数量
nmfreed int64 // 累计释放的 m 数量
ngsys uint32 // 系统 goroutine 数量,原子性更新
pidle puintptr // 空闲的处理器队列
npidle uint32 // 空闲的处理器数量
runq gQueue // 全局可运行 goroutine 队列
runqsize int32 // 全局可运行 goroutine 数量
// dead 状态的 goroutine 的全局缓存
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// sudog 对象的集中缓存
sudoglock mutex
sudogcache *sudog
// 可用的 _defer 对象的集中缓存
deferlock mutex
deferpool *_defer
// 当 m 被设置了 m.exited 标记之后,会挂载到 freem 链表上面等待被释放
// 链表使用 m.freelink 字段链接
freem *m
...
}
schedt 对象字段非常多 (毕竟是全局调度器),这里我们重点关注 3 个字段:
midle表示空闲的线程 (m),数据结构是指针,具体的get + set操作是通过指针 + 位置偏移量实现的pidle表示空闲的处理器 (p),数据结构和midle类似runq表示可运行的goroutine (g)队列, 数据结构是链表
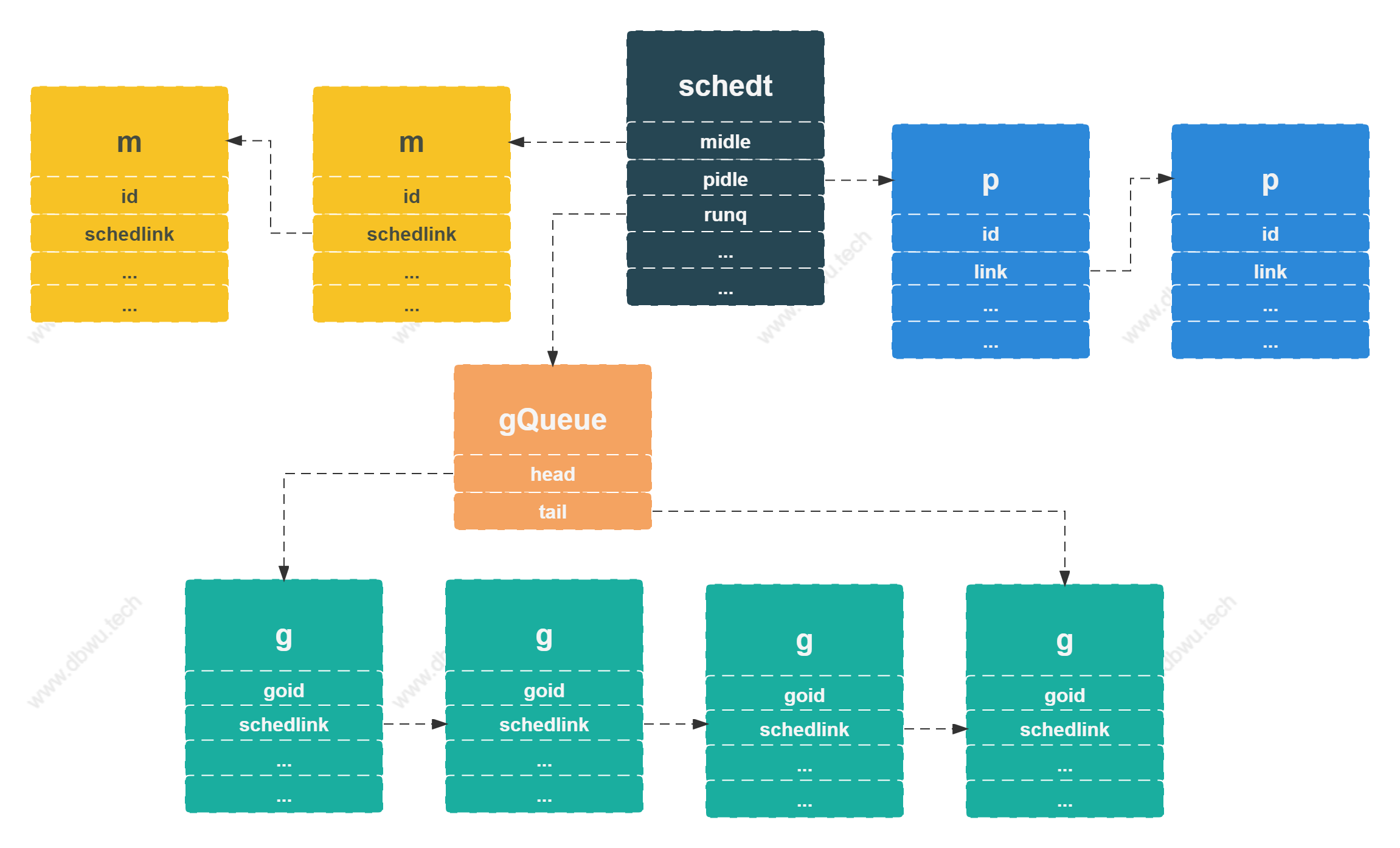
调度算法
现在我们已经对 GMP 和全局调度器的数据结构有了初步的了解,接下来通过分析调度算法代码,了解整个调度过程以及数据结构和状态的变化。调度相关的大部分方法定义在 $GOROOT/src/runtime/proc.go 文件中。
本文主要分析下面的几个核心部分:
- 调度器初始化
- 调度循环
- goroutine 创建与初始化
- goroutine 休眠与唤醒
- 系统调用
- 线程管理
- 主线程
- 监控线程
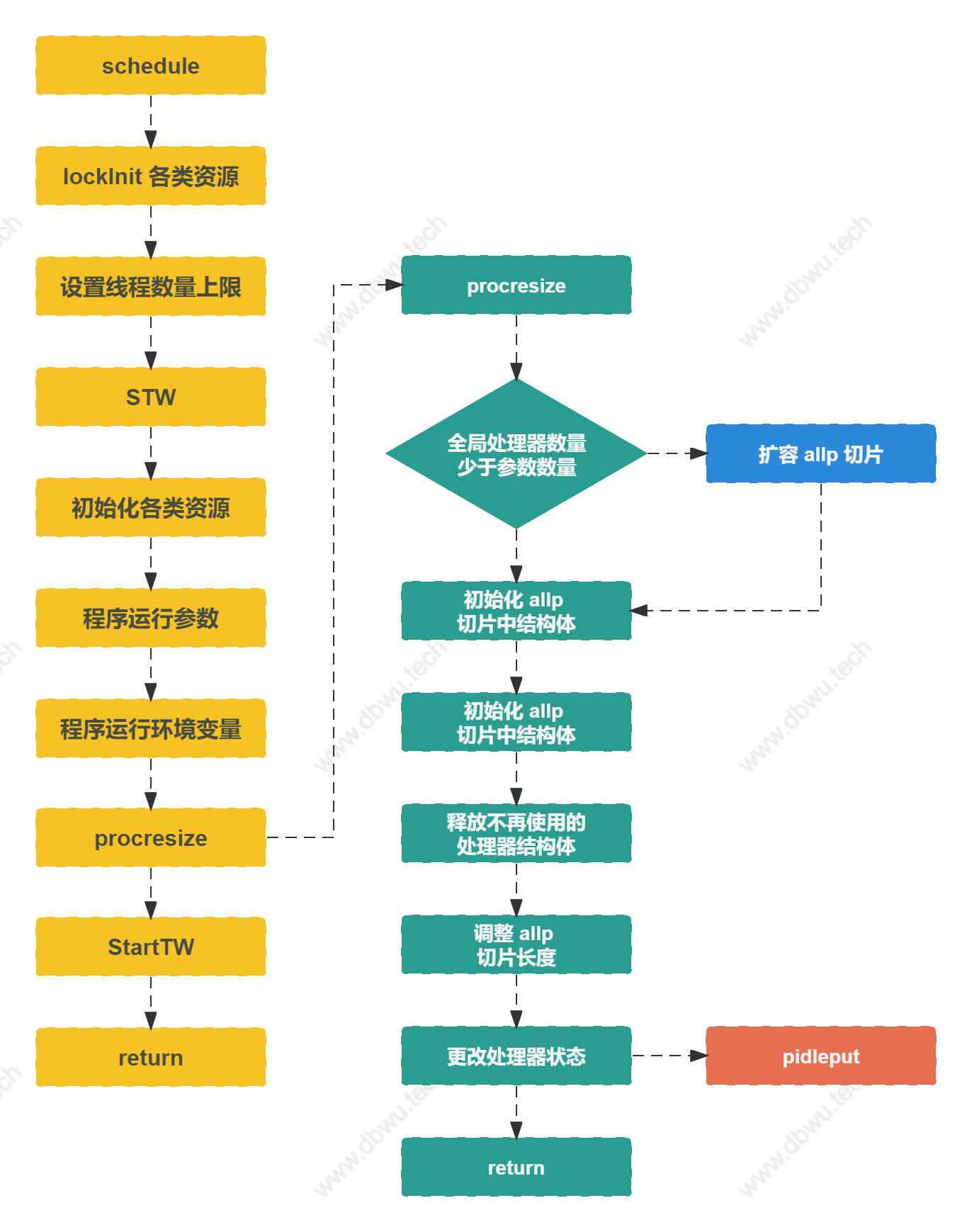
调度器初始化
schedinit 方法
schedinit 方法用来初始化调度器。
func schedinit() {
...
_g_ := getg()
// 设置线程数量上限
sched.maxmcount = 10000
// STW
worldStopped()
...
// 操作加锁
lock(&sched.lock)
sched.lastpoll = uint64(nanotime())
procs := ncpu
// 从环境变量获取线程数量
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
// 更新处理器数量
if procresize(procs) != nil {
// 调度器初始化时,不应该有运行的 goroutine
throw("unknown runnable goroutine during bootstrap")
}
// 操作释放锁
unlock(&sched.lock)
...
}
procresize 方法
allp 是一个 runtime 包内的全局变量,用来存放处理器 P。
var (
allp []*p
)
procresize 方法用于更新处理器 P 的数量,在操作期间,必须加锁并且执行 STW。
func procresize(nprocs int32) *p {
...
// 如果全局处理器数量少于期望处理器数量
// 先进行扩容
if nprocs > int32(len(allp)) {
...
}
// 初始化新增的处理器对象
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
}
...
// 释放不再使用的处理器对象
for i := nprocs; i < old; i++ {
p := allp[i]
p.destroy()
}
// 使全局处理器数量和期望处理器数量保持一致
if int32(len(allp)) != nprocs {
allp = allp[:nprocs]
}
// 除了当前处理器之外的所有处理器,设置为空闲状态
// 然后放入全局调度器的空闲队列
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
if _g_.m.p.ptr() == p {
continue
}
p.status = _Pidle
...
}
return runnablePs
}
pidleput 方法
pidleput 方法将处理器 P 放入全局调度器的空闲队列。
func pidleput(_p_ *p) {
...
// 将 P 放入队列头部
_p_.link = sched.pidle
sched.pidle.set(_p_)
// 队列元素数量 + 1
atomic.Xadd(&sched.npidle, 1)
}
调度器初始化流程图
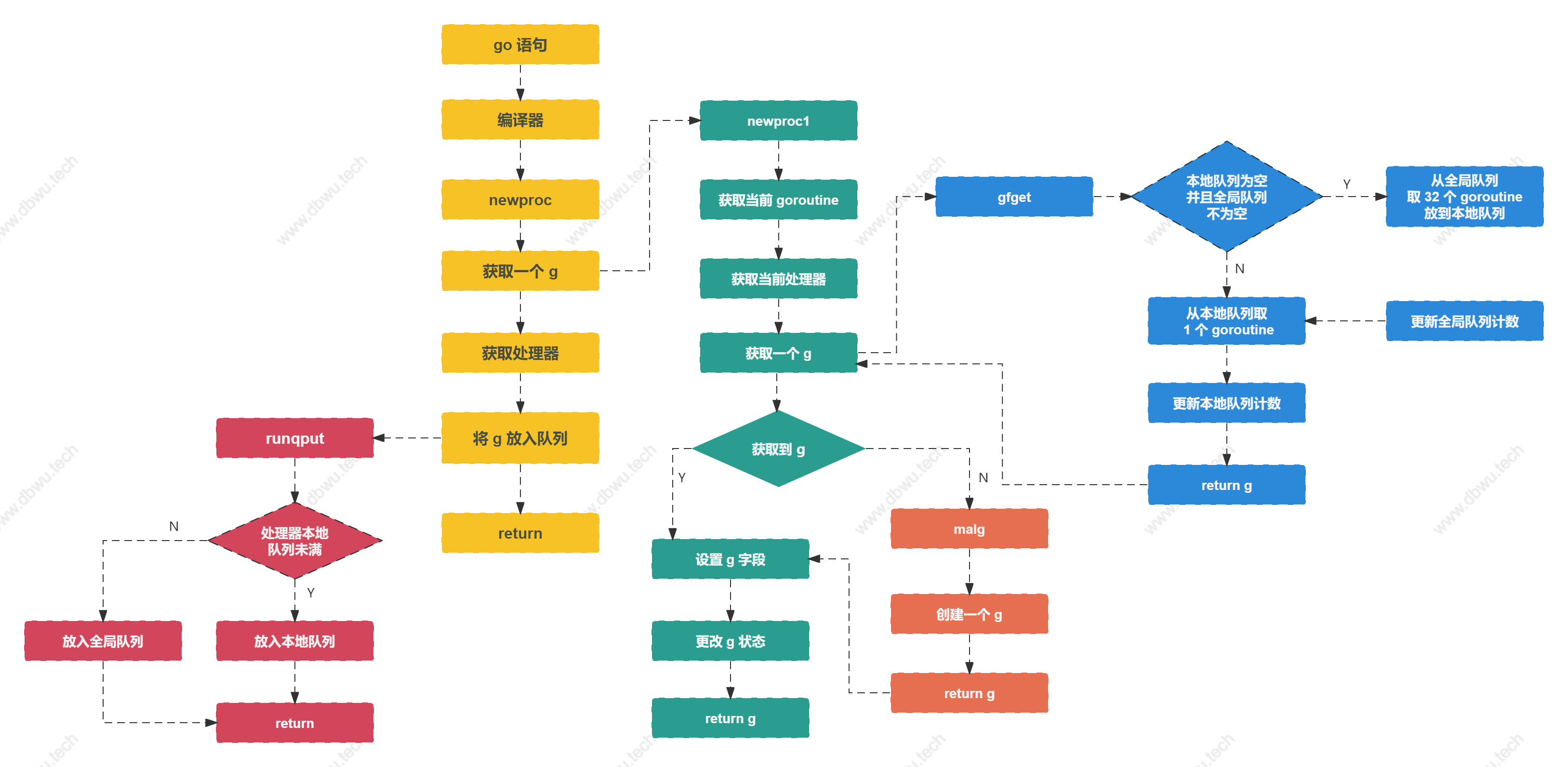
goroutine 创建与初始化
newproc 方法
newproc 方法用于创建一个新的 goroutine 来运行参数函数 fn, 新创建的 goroutine 会被放入处理器的队列等待运行,
编译器会将应用层的 go ... 代码语句 (例如 go func() {...}) 转换为 newproc 函数调用。
func newproc(fn *funcval) {
// 获取当前 G
gp := getg()
// 获取调用方的 sp 寄存器
pc := getcallerpc()
systemstack(func() {
// 获取新的 goroutine 对象
newg := newproc1(fn, gp, pc)
// 获取处理器
_p_ := getg().m.p.ptr()
// 将 goroutine 加入处理器的运行队列
runqput(_p_, newg, true)
if mainStarted {
wakep()
}
})
}
newproc1 方法
newproc1 方法用于创建一个状态为 _Grunnable (可运行) 的 goroutine 对象, 将参数赋值到 goroutine 对象对应的字段,调用方负责将新创建的 goroutine 添加到调度器。
具体的内部过程可以概述为:
- 优先从本地队列获取获取一个 goroutine 对象
- 如果本地队列为空,那么从全局队列窃取
- 如果本地队列和全局队列都没有获取到对象,就初始化一个新的 goroutine 对象
const (
// 最小栈空间: 2KB
_StackMin = 2048
)
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
_g_ := getg()
// 获取当前处理器 P
_p_ := _g_.m.p.ptr()
newg := gfget(_p_)
if newg == nil {
// 创建一个栈空间大小为 2KB 的 goroutine
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
}
...
// 设置 goroutine 对象字段
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
// goroutine 状态设置为 _Grunnable
casgstatus(newg, _Gdead, _Grunnable)
return newg
}
gfget 方法
gfget 方法用于从空闲队列中获取一个 goroutine 对象,优先从本地队列获取,如果本地队列为空,从调度器全局队列获取 32 个 goroutine, 放到本地队列中。
func gfget(_p_ *p) *g {
retry:
if _p_.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {
for _p_.gFree.n < 32 {
// 优先从栈队列中获取
gp := sched.gFree.stack.pop()
if gp == nil {
// 如果栈队列取不到,从非栈队列获取
gp = sched.gFree.noStack.pop()
if gp == nil {
break
}
}
// 全局队列元素数量减 1
sched.gFree.n--
// 将对象加入本地队列
_p_.gFree.push(gp)
// 本地队列元素数量加 1
_p_.gFree.n++
}
goto retry
}
// 从本地队列取一个 goroutine
gp := _p_.gFree.pop()
if gp == nil {
return nil
}
// 本地队列元素数量减 1
_p_.gFree.n--
return gp
}
malg 方法
malg 方法用于创建一个新的 goroutine 对象并返回。
func malg(stacksize int32) *g {
newg := new(g)
// 分配 goroutine 的栈空间
// 如果是调度器申请创建 goroutine,栈空间是 2KB
if stacksize >= 0 {
...
}
return newg
}
runqput 方法
runqput 方法用于将 goroutine 对象放入本地运行队列,根据参数 next 可以分为下面 3 种情况:
- 如果 next 为 false 且队列未满, 将 goroutine 放入本地运行队列
- 如果 next 为 false 且队列已满, 将 goroutine 放入全局运行队列
- 如果 next 为 true, 将 goroutine 设置为处理器下一个运行任务
func runqput(_p_ *p, gp *g, next bool) {
if next {
retryNext:
oldnext := _p_.runnext
// 将参数 goroutine 设置为处理器下一个运行任务
gp = oldnext.ptr()
}
retry:
...
if t-h < uint32(len(_p_.runq)) {
// 本地队列未满的情况下,放入完成后直接返回
atomic.StoreRel(&_p_.runqtail, t+1)
return
}
if runqputslow(_p_, gp, h, t) {
// 放入全局队列完成后,直接返回
return
}
goto retry
}
runqputslow 方法
runqputslow 方法用于将参数 goroutine 和本地运行队列中的一批 goroutine 全部放入全局队列。
具体的内部过程可以概述为:
- 从本地队列获取一半的 goroutine + 参数 goroutine 放入一个 临时队列
- 如果是随机调度的话,将临时队列元素顺序打乱
- 将临时队列中的 goroutine 放入全局队列
func runqputslow(_p_ *p, gp *g, h, t uint32) bool {
// 批量 goroutine 队列
var batch [len(_p_.runq)/2 + 1]*g
// 第一步,先从本地队列获取一半的 goroutine
n := t - h
n = n / 2
for i := uint32(0); i < n; i++ {
batch[i] = _p_.runq[(h+i)%uint32(len(_p_.runq))].ptr()
}
// 把参数 goroutine 加入到批量 goroutine 队列末尾
batch[n] = gp
// 第二步,如果是随机调度的话,将队列数组随机乱序
if randomizeScheduler {
for i := uint32(1); i <= n; i++ {
j := fastrandn(i + 1)
batch[i], batch[j] = batch[j], batch[i]
}
}
// 第三步,将队列数组中的 goroutine 构建为链表结构
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
var q gQueue
// 将队列头部元素放入链表头节点
q.head.set(batch[0])
// 将队列头部元素放入链表尾节点
q.tail.set(batch[n])
// 最后一步,将 goroutine 链表放入全局队列中
globrunqputbatch(&q, int32(n+1))
return true
}
goroutine 创建与初始化流程图
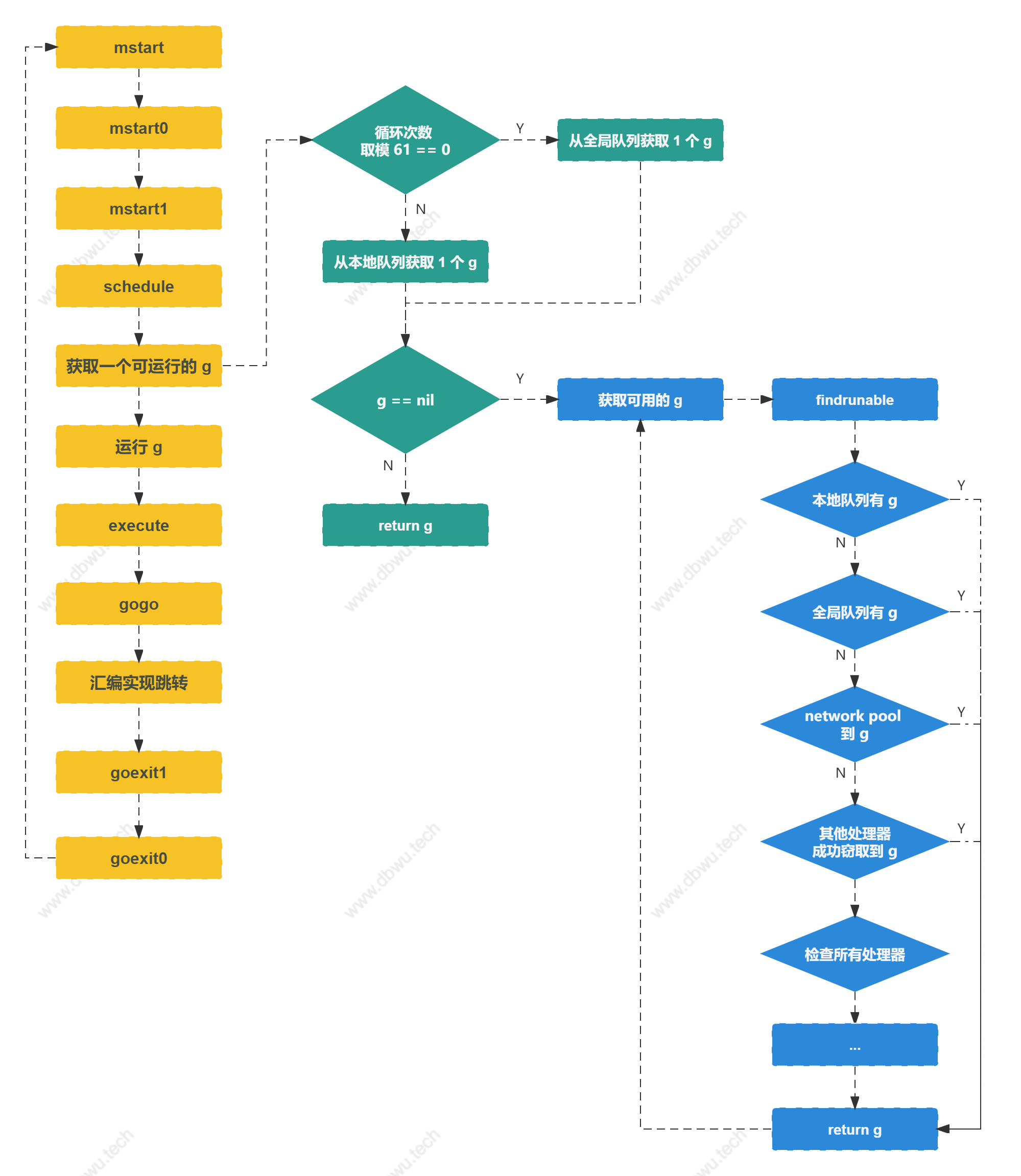
调度循环
调度器初始化完成之后,会进入调度主流程 (其实就是一个大循环)。
mstart 方法
mstart 方法由汇编语言实现,内部会调用 mstart1 方法,最后依次调用 schedule。
func mstart()
func mstart0() {
_g_ := getg()
mstart1()
}
func mstart1() {
_g_ := getg()
schedule()
}
schedule 方法
schedule 方法是调度过程的核心大循环,每次循环时找到一个可运行的 goroutine 执行。
为了尽可能保证调度的公平性,调度每循环 61 次,就会检查全局运行队列并取出一个 goroutine 运行,如果不这样做的话,可能产生的极端情况就是全局队列的里面的 goroutine 永远得不到执行。
至于为什么会选择质数 61,感兴趣的读者可以看看 这个链接 :-)。
func schedule() {
_g_ := getg()
...
top:
var gp *g
var inheritTime bool
...
// 调度每循环 61 次,执行一个全局队列中的 goroutine
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
gp = globrunqget(_g_.m.p.ptr(), 1)
}
// 从本地队列获取可运行的 goroutine
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
}
// 阻塞获取可运行的 goroutine
if gp == nil {
gp, inheritTime = findrunnable()
}
...
execute(gp, inheritTime)
}
findrunnable 方法
findrunnable 方法会阻塞执行,直至找到一个可运行的 goroutine, 该方法会依次尝试从下面几个地方获取 goroutine:
- 本地队列
- 全局队列
- 网络轮询器 (netpoll)
- 从其他处理器队列窃取
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
top:
_p_ := _g_.m.p.ptr()
...
// 尝试从本地运行队列获取
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// 尝试从全局运行队列获取
if sched.runqsize != 0 {
...
}
// 尝试从网络轮询器获取
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
...
}
// 尝试从其他处理器窃取 goroutine
// 如果自旋的 m 数量大于等于运行的 p 数量的一半,那么进入阻塞 (不会执行 if 分支内代码)
// 这样做是为了防止当线程过多并且程序的并行数很少时,造成不必要的 CPU 消耗
procs := uint32(gomaxprocs)
if _g_.m.spinning || 2*atomic.Load(&sched.nmspinning) < procs-atomic.Load(&sched.npidle) {
...
}
...
if _g_.m.spinning {
_g_.m.spinning = false
// 再次检查所有运行队列
_p_ = checkRunqsNoP(allpSnapshot, idlepMaskSnapshot)
if _p_ != nil {
goto top
}
// 再次检查 GC 是否有空闲可用的 goroutine
_p_, gp = checkIdleGCNoP()
if _p_ != nil {
return gp, false
}
...
}
// 再次尝试从网络轮询器获取
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
...
}
// 接着循环,直至获取到 goroutine 才能返回
goto top
}
execute 方法
execute 方法用于将参数 goroutine 调度到当前 M 运行,如果参数 inheritTime 等于 true, goroutine 可以直接继承当前时间片中的剩余时间,否则它会启动一个新的时间片。
func execute(gp *g, inheritTime bool) {
_g_ := getg()
// 首先建立 G 和 M 的关联绑定关系
// 将 M 的当前 G 字段指向 gp
// gp 的 m 字段 指向 m
_g_.m.curg = gp
gp.m = _g_.m
// 此时 goroutine 在状态变为运行之前就已经分配了 M
// 所以可以直接运行
// 更改 goroutine 状态
casgstatus(gp, _Grunnable, _Grunning)
...
// 汇编实现
// 执行参数 goroutine, 执行完之后跳转到 goexit1 方法
gogo(&gp.sched)
}
Goexit 方法
Goexit 方法用于终止调用方 goroutine 的运行, 不会影响到其他的 goroutine。
Goexit 在终止 goroutine 之前会运行所有 defer 函数,和 panic 不同的是,调用 recover 函数捕获不到 Goexit 的任何错误。
func Goexit() {
gp := getg()
// 运行所有 defer
for {
d := gp._defer
if d == nil {
break
}
...
}
goexit1()
}
goexit1 方法
goexit1 方法用于终止 goroutine 运行。
func goexit1() {
// 汇编实现
mcall(goexit0)
}
goexit0 方法
// 在 g0 上继续调度
// goexit continuation on g0.
func goexit0(gp *g) {
_g_ := getg()
_p_ := _g_.m.p.ptr()
// 继续调用 schedule
schedule()
}
调度循环流程图
小结
本文主要对 GMP 调度中的调度器初始化、goroutine 创建与初始化和调度循环三个部分做了详细的代码分析,下面的五个部分将放到下一篇文章中展开。
- goroutine 休眠与唤醒
- 系统调用
- 线程管理
- 主线程
- 监控线程
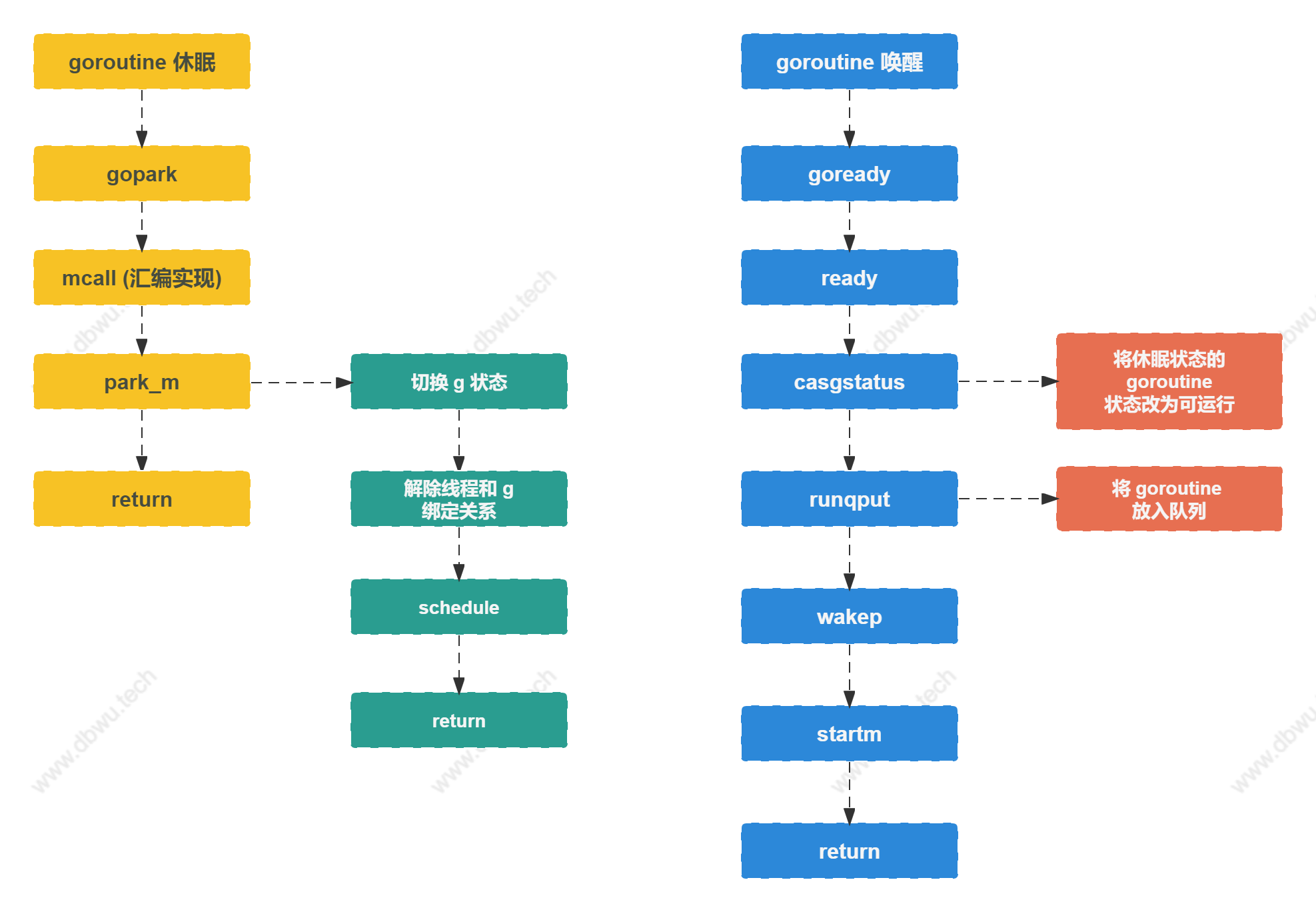
goroutine 休眠与唤醒
gopark 方法
gopark 方法用于将参数 goroutine 状态设置为等待 (休眠)。
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
...
// 汇编实现,跳转到 park_m 方法
mcall(park_m)
}
park_m 方法
park_m 方法用于切换参数 goroutine 状态以及解除和 M 的绑定关系,最后跳转到 schedule 方法再次进行调度。
func park_m(gp *g) {
...
// 切换 goroutine 状态
casgstatus(gp, _Grunning, _Gwaiting)
// 解除 M 和 goroutine 的绑定关系
dropg()
// 继续调度
schedule()
}
goready 方法
func goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
}
ready 方法
ready 方法用于将参数 goroutine 的状态切换至 _Grunnable 并将其放入队列等待被调度。
func ready(gp *g, traceskip int, next bool) {
...
// 将休眠状态的 goroutine 唤醒并放入运行队列
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(_g_.m.p.ptr(), gp, next)
wakep()
}
wakep 方法
wakep 方法尝试增加一个新的处理器 P 来执行 goroutine, 一般会在 goroutine 状态变可运行时调用 (例如 newproc 方法和 ready 方法)。
func wakep() {
...
startm(nil, true)
}
startm 方法
startm 方法调度一些 M 来运行处理器 P 队列中的 goroutine (如果有必要的情况下,会创建新的 M),如果参数 p 等于 nil,
尝试获取一个空闲的 P, 如果没有获取到, 就什么都不做。
func startm(_p_ *p, spinning bool) {
nmp := mget()
if nmp == nil {
// 没有空闲可用的 M, 创建一个新的
id := mReserveID()
newm(fn, _p_, id)
return
}
...
}
mget 方法
mget 方法尝试从空闲的 M 队列中获取一个 M。
func mget() *m {
mp := sched.midle.ptr()
if mp != nil {
sched.midle = mp.schedlink
sched.nmidle--
}
return mp
}
newm 方法
newm 方法用于创建一个新的 M,
//go:nowritebarrierrec
func newm(fn func(), _p_ *p, id int64) {
newm1(mp)
}
func newm1(mp *m) {
newosproc(mp)
}
newosproc 方法
newosproc 方法用于创建 操作系统线程,方法定义在 $GOROOT/src/runtime/os_linux.go 文件中。
func newosproc(mp *m) {
// 通过系统调用 clone 创建线程
ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(abi.FuncPCABI0(mstart)))
...
}
休眠与唤醒流程图
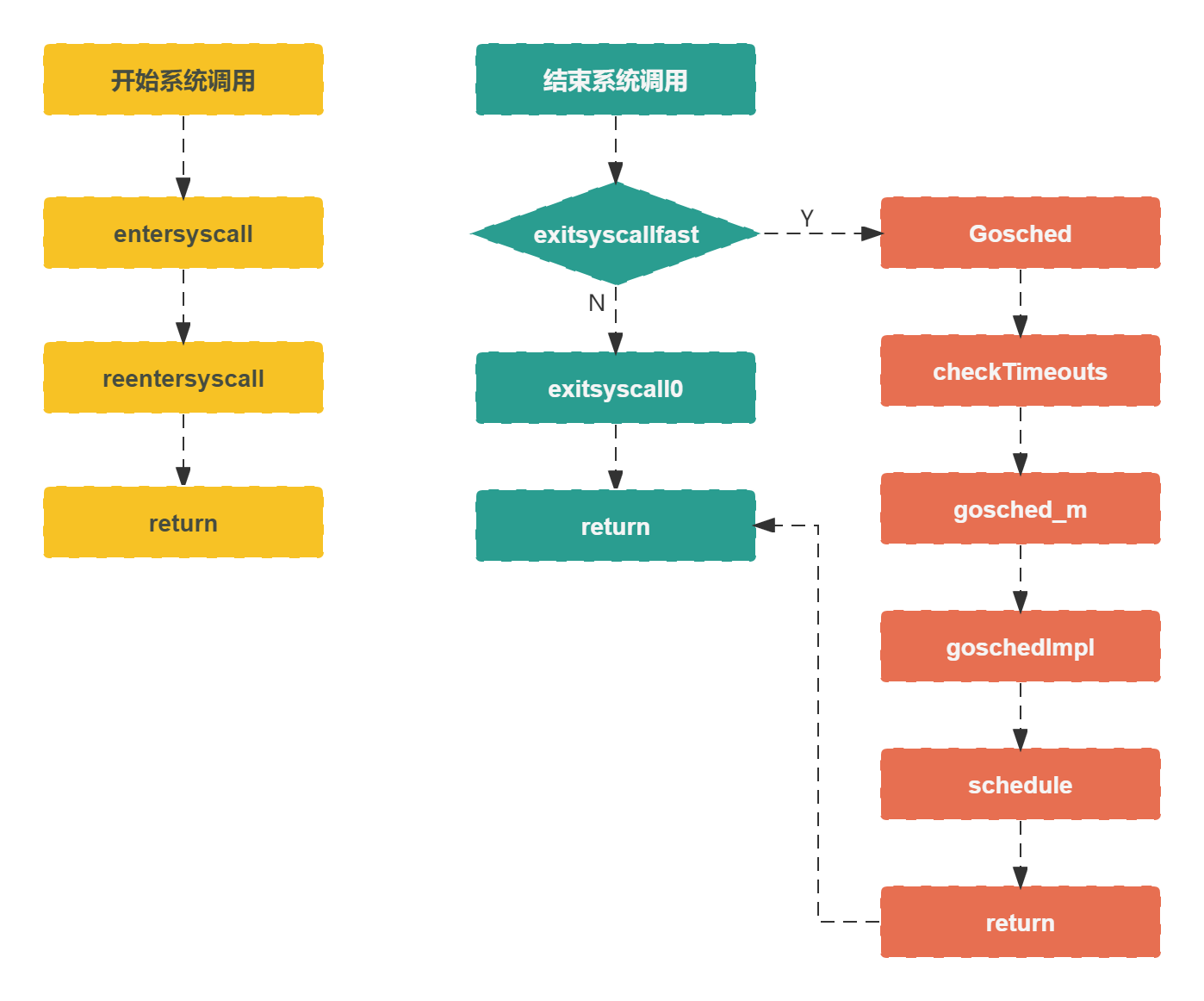
系统调用
entersyscall 方法
entersyscall 方法表示标准的系统调用方法,通过获取调用方的 sp 和 pc 寄存器,然后调用 reentersyscall。
func entersyscall() {
reentersyscall(getcallerpc(), getcallersp())
}
reentersyscall 方法
reentersyscall 方法根据参数 sp 和 pc 寄存器执行系统调用。
func reentersyscall(pc, sp uintptr) {
// 获取 goroutine
_g_ := getg()
// 禁止抢占,因为 goroutine 处于系统调用状态
_g_.m.locks++
// 保证没有调用其他函数触发的栈分裂/栈增长
_g_.stackguard0 = stackPreempt
_g_.throwsplit = true
// 保存 pc 和 sp 寄存器
save(pc, sp)
_g_.syscallsp = sp
_g_.syscallpc = pc
// 更新 goroutine 状态
casgstatus(_g_, _Grunning, _Gsyscall)
// 将 goroutine 的处理器和线程解除绑定
// (高性能 Tips: 陷入系统调用后,把线程让出来,给其他资源使用)
_g_.m.syscalltick = _g_.m.p.ptr().syscalltick
_g_.sysblocktraced = true
pp := _g_.m.p.ptr()
pp.m = 0
_g_.m.oldp.set(pp)
_g_.m.p = 0
// 更新处理器状态
atomic.Store(&pp.status, _Psyscall)
if sched.gcwaiting != 0 {
systemstack(entersyscall_gcwait)
save(pc, sp)
}
_g_.m.locks--
}
exitsyscall 方法
exitsyscall 方法表示系统调用结束,goroutine 重新进入调度流程。
func exitsyscall() {
if exitsyscallfast(oldp) {
// exitsyscallfast 返回 true
// 说明存在空闲的处理器可以运行 goroutine
if sched.disable.user && !schedEnabled(_g_) {
// 执行调度
Gosched()
}
return
}
// 执行调度
mcall(exitsyscall0)
...
}
Gosched 方法
Gosched 方法会主动让出处理器给其他 goroutine 运行,它不会挂起当前的 goroutine, 因此当前的 goroutine 可能会调度到其他处理器上运行。
func Gosched() {
// 汇编实现
// 最后依然会跳转到 schedule 方法
mcall(gosched_m)
}
gosched_m 方法
func gosched_m(gp *g) {
goschedImpl(gp)
}
goschedImpl 方法
func goschedImpl(gp *g) {
// 再次触发调度
schedule()
}
系统调用流程图
线程管理相关方法
LockOSThread 方法
LockOSThread 方法将 goroutine 绑定到当前操作系统线程,绑定之后,goroutine 将一直在该线程上运行 (这是一个相对底层的运行 API, 一般业务开发用不到)。
func LockOSThread() {
dolockOSThread()
}
dolockOSThread 方法
func dolockOSThread() {
...
}
UnlockOSThread 方法
UnlockOSThread 方法是 LockOSThread 方法的逆方法 (解除线程和 goroutine 绑定关系)。
func UnlockOSThread() {
dounlockOSThread()
}
dounlockOSThread 方法
func dounlockOSThread() {
...
}
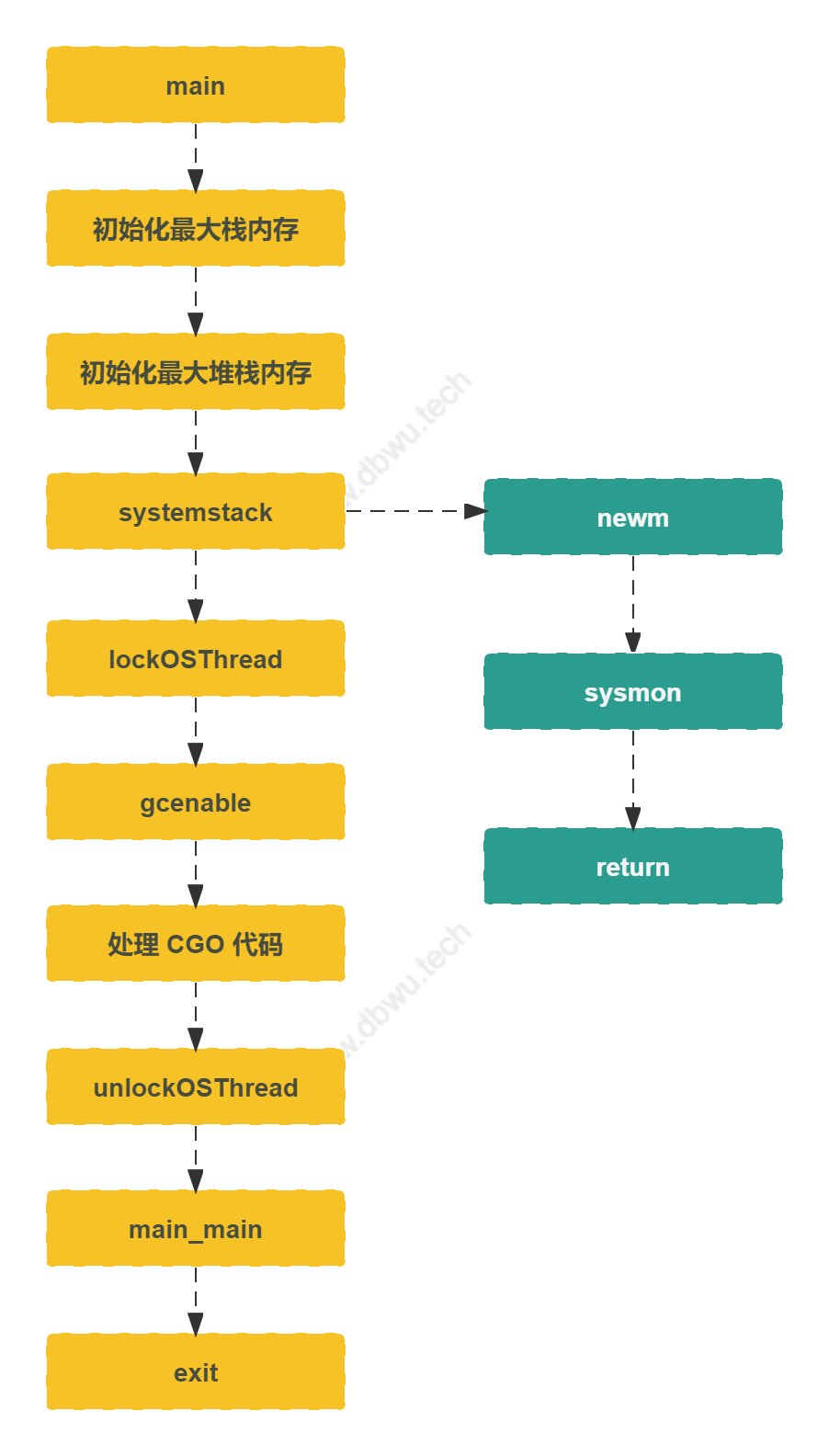
主线程
主线程只能在 runtime.m0 线程上面运行,全局只有一个实例。
main
func main() {
g := getg()
if goarch.PtrSize == 8 {
// 64 位最大栈内存 ≈ 1GB
maxstacksize = 1000000000
} else {
// 32 位最大栈内存 ≈ 250MB
maxstacksize = 250000000
}
// 最大堆栈内存
maxstackceiling = 2 * maxstacksize
// 允许 newproc 方法启动新的线程
mainStarted = true
if GOARCH != "wasm" {
// 启动监控线程
systemstack(func() {
newm(sysmon, nil, -1)
})
}
...
fn := main_main
fn()
...
exit(0)
}
主线程流程图
监控线程
监控线程 运行时不需要处理器 (因为其在独立的线程上运行, 和主线程 m0 一样,全局只有一个实例)。
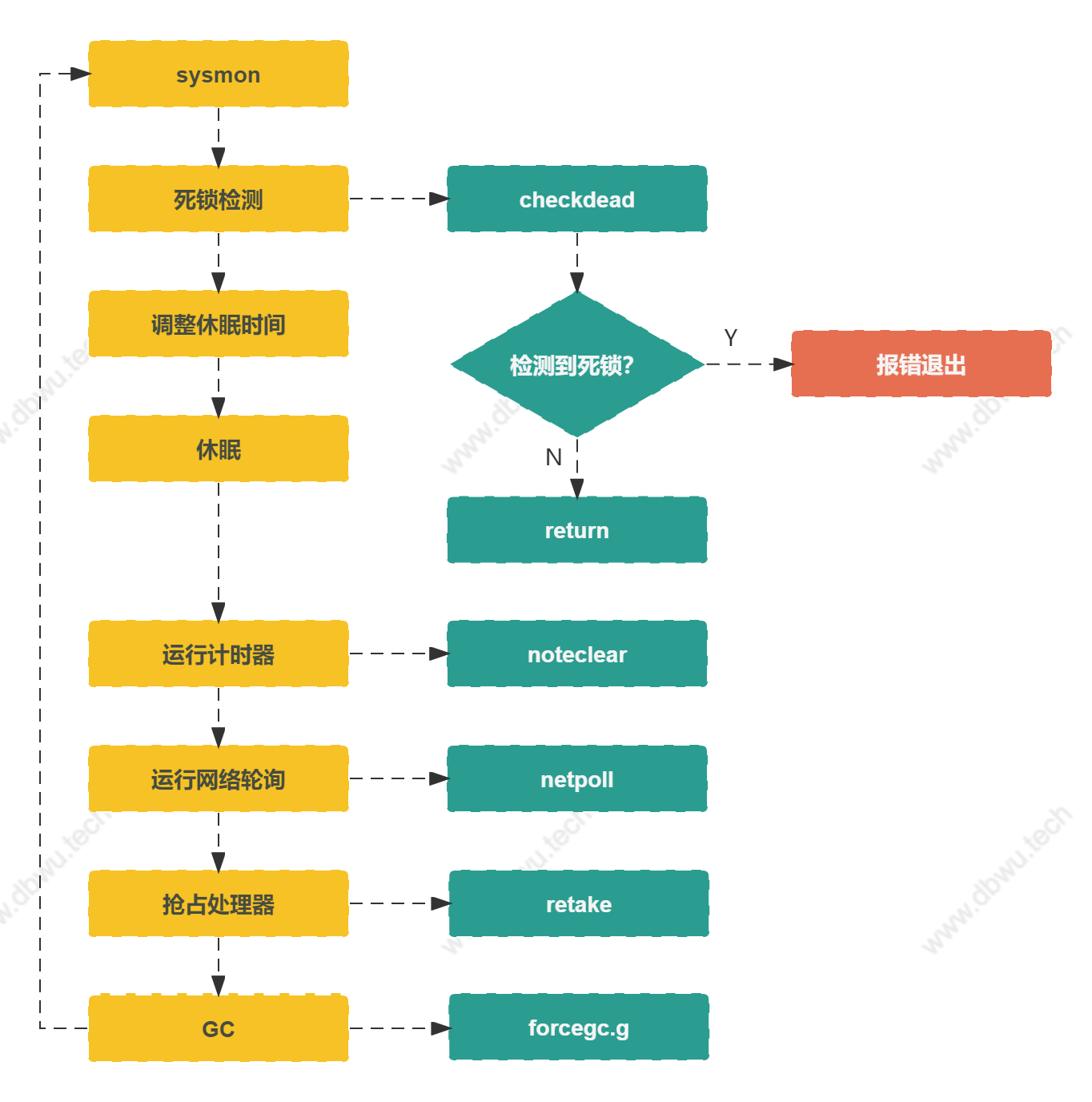
sysmon 方法
sysmon 方法的内部实现是一个无限循环,可以等价于一个后台守护进程,执行任务 -> 休眠 -> 执行任务 循环往复。
func sysmon() {
// 死锁检测
checkdead()
lasttrace := int64(0)
// 没有唤醒任意 goroutine 的连续周期
idle := 0
// 休眠时间
delay := uint32(0)
for {
if idle == 0 {
// 初始休眠时间 20us
delay = 20
} else if idle > 50 {
// 1ms 之后, 休眠时间翻倍 (循环执行了 50 次并且每次都没有唤醒的 goroutine)
// 说明基本没有可以运行的任务
delay *= 2
}
if delay > 10*1000 {
// 最大休眠时间 10ms
delay = 10 * 1000
}
// 调用 usleep 函数休眠
usleep(delay)
// 运行计时器
now := nanotime()
if debug.schedtrace <= 0 && (sched.gcwaiting != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs)) {
if atomic.Load(&sched.gcwaiting) != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs) {
syscallWake := false
next, _ := timeSleepUntil()
if next > now {
// 如果存在需要被唤醒的计时器
// 保证唤醒周期足够短,提高抽样正确率
...
}
if syscallWake {
// 被唤醒之后
// 更新唤醒连续周期和休眠时间
idle = 0
delay = 20
}
}
}
// 更新 now 变量时间
// 避免上面的 "计时器部分" 代码执行了过长时间,影响时间精度
now = nanotime()
// 如果距离最后一次网络轮询时间已超过 10ms, 执行一次网络循环操作
lastpoll := int64(atomic.Load64(&sched.lastpoll))
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
// 非阻塞模式 - 返回一个 goroutine 队列
list := netpoll(0)
if !list.empty() {
// 如果网络轮询返回的队列不为空,
// 说明存在需要处理的网络 IO 操作
// 将 goroutine 放入队列之前
// 需要减少空闲锁定的 M 数量 (模拟还有 1 个 M 在运行)
// 这样可以避免下述情况发生:
// injectglist() 方法获取了所有的处理器 P
// 但在它开始运行 M 之前
// 另一个 M 从系统调用返回,发现没有处于等待状态的 goroutine, 也没有其他 M 在运行,误报死锁...
incidlelocked(-1)
// 将 goroutine 放入队列
injectglist(&list)
incidlelocked(1)
}
}
// 接收阻塞在系统调用上面的 goroutine
// 抢占长时间运行的 goroutine
if retake(now) != 0 {
idle = 0
} else {
idle++
}
// 检测是否需要强制 GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
// 将执行 GC 操作的 goroutine 放入队列
injectglist(&list)
}
...
}
}
checkdead 方法
checkdead 方法用于死锁检测,检测方法基于正在运行的线程数量,如果为 0, 说明发生了死锁,该方法没有返回值,检测到死锁之后,直接报错。
运行线程数量 = 系统线程总数量 - 空闲线程数量 - 锁定线程数量 - 系统调用线程数量
func checkdead() {
var run0 int32
// 获取运行线程的数量
run := mcount() - sched.nmidle - sched.nmidlelocked - sched.nmsys
if run > run0 {
// 运行线程数量大于 0, 说明不存在死锁
return
}
if run < 0 {
// 运行线程数量 < 0, 报错
print(...)
throw(...)
}
// 运行线程数量等于 0 的情况下,继续检查
grunning := 0
forEachG(func(gp *g) {
if isSystemGoroutine(gp, false) {
// 如果是 main goroutine 调用, 直接返回
return
}
s := readgstatus(gp)
switch s &^ _Gscan {
// 运行线程数量等于 0
// 并且有 goroutine 状态处于 _Gwaiting 或 _Gpreempted 时
// grunning 计数器 + 1
case _Gwaiting,
_Gpreempted:
grunning++
// 运行线程数量等于 0
// 并且有 goroutine 状态处于 [_Grunnable, _Grunning, _Gsyscall] 集合
// 说明存在死锁,直接报错
case _Grunnable,
_Grunning,
_Gsyscall:
print(...)
throw(...)
}
})
// grunning 计数器等于 0
// 当所有的 goroutine 状态都处于 [_Grunnable, _Grunning, _Gsyscall] 集合
// 说明 main goroutine 调用了 runtime.Goexit() 方法
if grunning == 0 {
...
}
// grunning 计数器不等于 0
// 说明存在等待的 goroutine, 但是不存在运行的 goroutine
// 检查所有处理器 (全局变量 allgs) 的计时器
for _, _p_ := range allp {
if len(_p_.timers) > 0 {
// 如果任一处理器的计时器时间大于 0, 直接退出
return
}
}
// 如果所有处理器都没有等待的计时器,说明存在死锁,直接报错
throw("all goroutines are asleep - deadlock!")
}
mcount 方法
mcount 方法用于获取 操作系统线程 总数量。
func mcount() int32 {
return int32(sched.mnext - sched.nmfreed)
}
forEachG 方法
forEachG 方法对所有的 goroutine (全局变量 allgs) 执行回调方法。
func forEachG(fn func(gp *g)) {
for _, gp := range allgs {
fn(gp)
}
}
injectglist 方法
injectglist 方法将参数队列中的所有 goroutine 加入到队列中,具体的处理逻辑如下:
- 如果当前的
goroutine没有绑定处理器P(那么显然是主线程或监控线程),将参数队列中的所有goroutine加入到全局队列,并启动空闲的线程来运行goroutine - 否则,向全局队列添加
N个goroutine(N 等于空闲的处理器 P 数量),剩下的goroutine添加到当前处理器P的队列中
所以分配
goroutine到运行队列时,并不是 “雨露均沾”,而是优先将大多数分配到本地处理器 P, 通过数据局部性质 (data locality) 来提升性能。
func injectglist(glist *gList) {
// 将参数队列中的所有 goroutine 状态从等待改为可运行
head := glist.head.ptr()
for gp := head; gp != nil; gp = gp.schedlink.ptr() {
casgstatus(gp, _Gwaiting, _Grunnable)
}
// 将参数队列中的所有 goroutine 数据结构改为链表
var q gQueue
q.head.set(head)
q.tail.set(tail)
*glist = gList{}
// 启动空闲的线程来运行 goroutine
startIdle := func(n int) {
for ; n != 0 && sched.npidle != 0; n-- {
startm(nil, false)
}
}
pp := getg().m.p.ptr()
if pp == nil {
// 当前 goroutine 没有绑定处理器
// 将所有 goroutine 放入全局队列,然后返回
globrunqputbatch(&q, int32(qsize))
startIdle(qsize)
return
}
// 向全局队列添加 N 个 goroutine (N 等于空闲的处理器 P 数量)
npidle := int(atomic.Load(&sched.npidle))
var globq gQueue
var n int
for n = 0; n < npidle && !q.empty(); n++ {
g := q.pop()
globq.pushBack(g)
}
if n > 0 {
globrunqputbatch(&globq, int32(n))
}
// 将剩下的 goroutine 添加到当前处理器 P 的运行队列中
if !q.empty() {
runqputbatch(pp, &q, qsize)
}
}
retake 方法
retake 方法用于抢占处理器,主要有两种抢占方式:
- 当处理器处于
运行或系统调用状态时,如果当前时间距离最后一次调度时间超过10ms, 抢占当前处理器 - 当处理器处于
系统调用状态时,如果等待的过程中经历了一轮调度,抢占当前处理器 - 调用 runtime.Gosched()
方法的内部实现中有个细节需要注意: 不能使用 range 遍历 allp, 因为在整个遍历过程中,可能会有解锁再次加锁的情况 (也就意味着 allp 会发生变化),
所以在循环的 “条件判断表达式” 部分,每次需要重新获取 allp 的长度。这里涉及到一个基础知识点:
for 遍历和 for + range 遍历计算长度的方式不一样。
// 单个 goroutine 运行多长时间会被抢占
const forcePreemptNS = 10 * 1000 * 1000 // 10ms
func retake(now int64) uint32 {
n := 0
// 加锁全局处理器切片, 防止数据竞态产生的问题
lock(&allpLock)
// 使用 for 遍历 allp
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
if _p_ == nil {
// 如果 procresize 方法扩容了 allp 切片
// 但是没有创建新的 P, 则跳过
continue
}
s := _p_.status
// 抢占逻辑 - 1
if s == _Prunning || s == _Psyscall {
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
...
} else if pd.schedwhen+forcePreemptNS <= now {
// 如果距离最后一次调度超过 10ms, 抢占处理器
preemptone(_p_)
}
}
// 抢占逻辑 - 2
if s == _Psyscall {
t := int64(_p_.syscalltick)
// 等待的过程中经历了一轮调度
if !sysretake && int64(pd.syscalltick) != t {
...
}
if atomic.Cas(&_p_.status, s, _Pidle) {
handoffp(_p_)
}
}
}
return uint32(n)
}
监控线程流程图
FAQ
每个 P 可以存放多少个 goroutine ?
type p struct {
// goroutine 队列
runq [256]guintptr
// 拥有最高优先级的 goroutine
runnext guintptr
}
通过源码可以看到,每个 P 一共可以放 257 个 goroutine。
P 存在的好处是什么?
直观上看,有了 G 表示的 goroutine (具体的任务),M 表示的线程 (具体的执行单位),那么只需要让两者进行关联绑定,M 不断执行其队列中 G 即可,
为什么要加入一个中间层 P 呢?最核心的问题依然是性能。
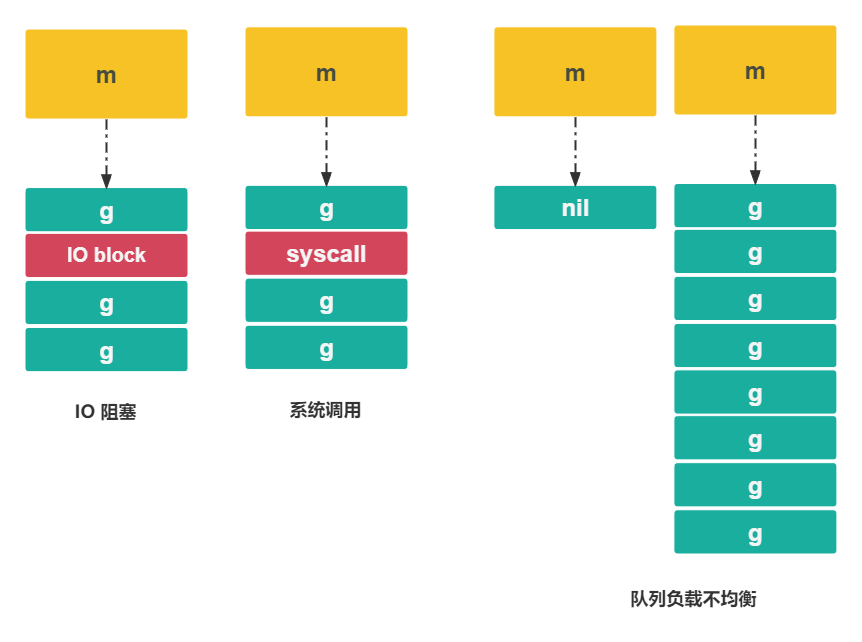
假设现在没有中间层 P, 将会遇到如下问题:
- IO 操作阻塞: 当
M陷入 IO 调用时 (如网络、文件、数据库等) 会阻塞等待,浪费 CPU 资源 - 系统调用操作阻塞: 当
M陷入系统调用时会阻塞等待,浪费 CPU 资源 - M 队列负载不均衡: 每个
M中G的数量以及执行时常可能出现很大的差异: 例如有的M中有很多G等待运行,有的M则完全没有G而处于空转状态,浪费 CPU 资源 - 数据局部性问题:
G被切换到其他M执行时,当前M缓存数据失效 - G 的关联问题: 每个
G在关联M时会引起锁争用,如果要在这一步实现均衡分配,会增加底层和应用层代码的复杂度 (例如根据 G 的任务类型或各个 M 中的 G 数量,选择合理的 M 进行关联) - 全局锁问题: 每个
G的相关操作和调度都需要加全局锁
有了中间层 P 之后,上面的几个问题可以得到有效解决:
- IO 操作阻塞: 挂起当前
M,取消关联的P,此时P可以重新选择一个M运行 - 系统调用操作阻塞: 挂起当前
M,取消关联的P,此时P可以重新选择一个M运行 - M 队列负载不均衡: 通过
全局队列 + 窃取机制解决 - 数据局部性问题: 使用
P来调度G并缓存G的数据,M只负责具体的执行工作 - G 的关联问题:
G优先放入绑定的本地P队列, 其次放入全局队列,最小化锁争用 - 全局锁问题:
G优先放入绑定的本地P队列, 其次放入全局队列,最小化锁争用
goroutine 调度时机
下面的场景可能会触发 Scheduler 重新调度。
| 场景 | 说明 |
|---|---|
| 使用关键字 go | go 创建一个新的 goroutine,Go scheduler 可能会调度 |
| GC | 由于执行 GC 工作的 goroutine 也需要在 M 上运行,因此肯定会发生调度 |
| syscall | 当 goroutine 进行系统调用时,会阻塞 M,所以它会被调度走,同时一个新的 goroutine 会被调度过来 |
| Gosched | 调用 runtime.Gosched() 方法 |
| 内部同步访问 | atomic,mutex,channel 操作等会使 goroutine 阻塞,因此会被调度走,等待条件满足后(例如其他 goroutine 解锁了)还会被调度过来继续运行 |
小结
本文主要对 GMP 调度中涉及到的五个部分做了代码分析:
- goroutine 休眠与唤醒
- 系统调用
- 线程管理
- 主线程
- 监控线程
写到这里,长达一万五千多字的 GMP 调度器代码分析就结束了。
我们分别从 数据结构、调度算法、线程 三个部分来分析 GMP 调度器的设计与实现,相对于整个 GMP 调度模型 来说,这还远远不够。
例如具体的底层调用机制、系统中断及上下文切换机制、具体功能的汇编实现等等,本文没有进行深入的分析,主要因为这是一个庞大的网状知识体系结构,
短短三篇文章难以全面覆盖,同时笔者也确实没有足够的时间把细节逐一完善。
希望这篇文章可以抛砖引玉,吸引感兴趣的读者进行更深入的探索,做出更高质量的成果分享。
