sync.Once Code Reading
2023-04-23 Golang 并发编程 Go 源码分析 读代码
概述
sync.Once 可以保证某段程序在运行期间的只执行一次,典型的使用场景有初始化配置, 数据库连接等。
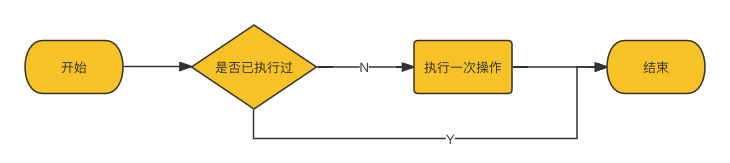
与 init 函数差异
init函数是当所在的 package 首次被加载时执行,若迟迟未被使用,则既浪费了内存,又延长了程序加载时间sync.Once方法可以在代码的任意位置初始化和调用,并发场景下是线程安全的,因此可以延迟到使用时再调用 (懒加载)
示例
通过一个小例子展示 sync.Once 的使用方法。
package main
import (
"fmt"
"sync"
)
type Config struct {
Server string
Port int
}
var (
once sync.Once
config *Config
)
func InitConfig() *Config {
once.Do(func() {
fmt.Println("mock init ...") // 模拟初始化代码
})
return config
}
func main() {
// 连续调用 5 次初始化方法
for i := 0; i < 5; i++ {
_ = InitConfig()
}
}
$ go run main.go
# 输出如下
mock init ...
从输出的结果中可以看到,虽然我们调用了 5 次初始化配置方法,但是真正的初始化方法只执行了 1 次,实现了设计模式中 单例模式 的效果。

内部实现
接下来,我们来探究一下 sync.Once 的内部实现,文件路径为 $GOROOT/src/sync/once.go,笔者的 Go 版本为 go1.19 linux/amd64。
Once 结构体
package sync
import (
"sync/atomic"
)
// Once 是一个只执行一次操作的对象
// Once 一旦使用后,便不能再复制
//
// 在 Go 内存模型术语中,once.Do(f) 中函数 f 的返回值会在 once.Do() 函数返回前完成同步
type Once struct {
done uint32
m Mutex
}
sync.Once 的结构体有 2 个字段,m 表示持有一个互斥锁,这是并发调用场景下 只执行一次 的保证,
done 字段表示调用是否已完成,使用的字段类型是 uint32, 这样就可以使用标准库中 atomic 包里面 *Uint32 系列方法了,
为什么没有使用 bool 类型呢? 因为标准库中 atomic 包并未提供针对 bool 类型的相关方法,如果适用 bool 类型,操作时就需要转换为 指针 类型,
然后使用 atomic.*Pointer 系列方法操作,这样会造成内存占用过多 (bool 占用 1 个字节,指针 占用 8 个字节) 和性能损耗 (参数类型转换)。
done 字段
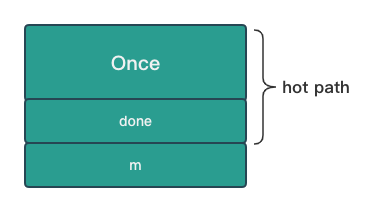
done 作为结构体的第一个字段,能够减少 CPU 指令,也就是能够提升性能,具体来说:
热路径 hot path 是程序非常频繁执行的一系列指令,sync.Once 绝大部分场景都会访问 done 字段,所以 done 字段是处于 hot path 上的,这样一来 hot path 编译后的机器码指令更少,性能更高。
为什么放在第一个字段就能够减少指令呢?因为结构体第一个字段的地址和结构体的指针是相同的,如果是第一个字段,直接对结构体的指针解引用即可。
如果是其他的字段,除了结构体指针外,还需要计算与第一个值的 偏移量。在机器码中,偏移量是随指令传递的附加值,CPU 需要做一次偏移值与指针的加法运算,
才能获取要访问的值的地址,因此访问第一个字段的机器码更紧凑,速度更快。
Do 方法
// 当且仅当第一次调用实例 Once 的 Do 方法时,Do 去调用函数 f
// 换句话说,调用 once.Do(f) 多次时,只有第一次调用会调用函数 f,即使 f 函数在每次调用中有不同的参数值
// 并发调用 Do 函数时,需要等到其中的一个函数 f 执行之后才会返回
// 所以函数 f 中不能调用同一个 once 实例的 Do 函数 (递归调用),否则会发生死锁
// 如果函数 f 内部 panic, Do 函数同样认为其已经返回,将来再次调用 Do 函数时,将不再执行函数 f
// 所以这就要求我们写出健壮的 f 函数
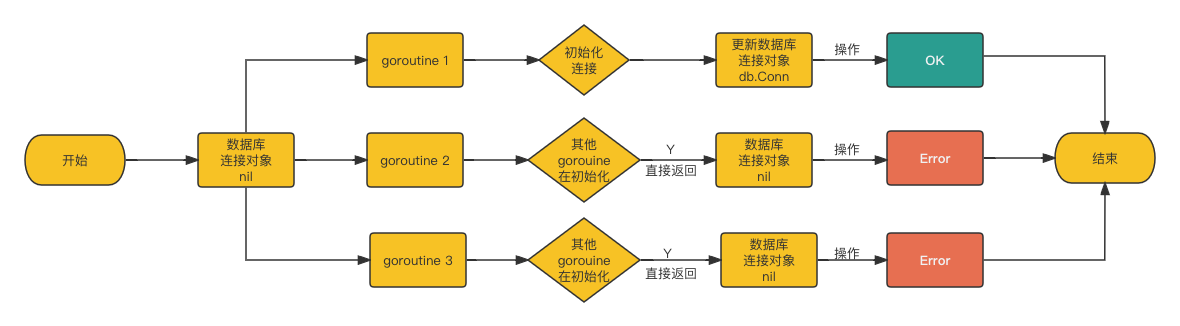
func (o *Once) Do(f func()) {
// 下面是一个错误的实现
// if atomic.CompareAndSwapUint32(&o.done, 0, 1) {
// f()
// }
// 错误原因分析:
// 这里以数据库连接场景为例,在并发调用情况下,假设其中 1 个 goroutine 正在执行函数 f (初始化连接),
// 此时其他的 goroutine 将不会等待这个 goroutine 执行完成,而是会直接返回,
// 如果连接发生了一些延迟,导致函数 f 还未执行完成,那么此时连接其实还未建立,
// 但是其他的 goroutine 认为函数 f 已经执行完成,连接已建立,可以开始使用了
// 最后当其他 goroutine 使用未建立的连接操作时,产生报错
// 要解决上面的问题, 就需要确保当前函数返回时, 函数 f 已经执行完成,
// 这就是 slow path 退回到互斥锁的原因,以及为什么 atomic.StoreUint32 需要延迟到函数 f 返回之后
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f) // slow-path 允许内联
}
}
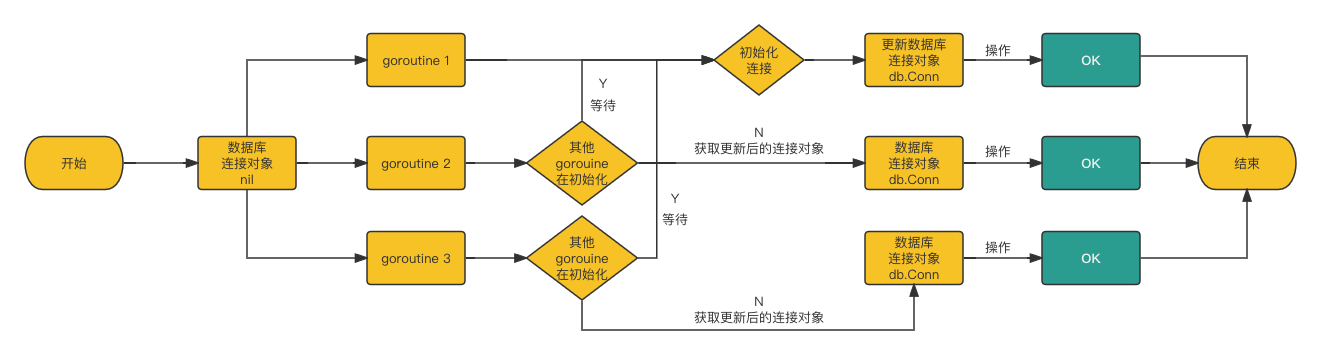
doSlow 方法
func (o *Once) doSlow(f func()) {
// 并发场景下,可能会有多个 goroutine 执行到这里
o.m.Lock() // 但是只有 1 个 goroutine 能获取到互斥锁
defer o.m.Unlock()
// 注意下面临界区内的判断和修改
// 在 atomic.LoadUint32 时为 0 ,不等于获取到锁之后也是 0,所以需要二次检测
// 因为已经获取到互斥锁,根据 Go 的同步原语约束,对于字段 done 的修改需要在获取到互斥锁之前同步
// 所以这里直接访问字段即可,不需要调用 atomic.LoadUint32 方法
// 如果有其他 goroutine 已经修改了字段 done,那么就不会进入条件分支,没有任何影响
if o.done == 0 {
// 只要函数 f 成功执行过一次,就将 o.done 修改为 1
// 这样其他 goroutine 就不会再执行了,从而保证了函数 f() 只会执行一次,
// 这里必须使用 atomic.StoreUint32 方法来满足 Go 的同步原语约束
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
小结
sync.Once 的源代码只有短短十几行,看似简单的条件分支背后充斥着 并发执行, 原子操作, 同步原语 等基础原理,
深入理解这些原理之后,可以帮助我们更好地构建并发系统,解决并发编程中遇到的问题。
