Go 线程安全 map 方案选型
2023-06-25 Golang 并发编程 Go 源码分析 读代码
概述
Go 语言标准库中的 map 数据类型并不是线程安全的,多个 goroutine 可以并发读取同一个 map, 但是不能并发写入同一个 map, 否则会引发 panic。
为了解决这个问题,实际开发中通常会使用下面的三种方案中的一个或多个:
- 通过 map 数据类型 + 锁 (互斥锁, 读写锁)
- 标准库内置的
sync.Map对象 (支持并发读写) - 分段锁
作为补充,本文会顺带对比一下自旋锁和标准库中的互斥锁的性能差异,对于 map 数据类型及其操作原语来说,两者实现的功能保证是一致的, 而且自旋锁更多的应用场景在无锁编程,所以文章末尾的基准测试不包含自旋锁 (当然,感兴趣的读者可以在本文基础上进行修改,自行对比测试结果)。
💡 本文代码较多,对测试过程不感兴趣的读者可以直接跳转到文章末尾看结论。
读写锁和互斥锁
标准库中的读写锁和互斥锁的性能差异及使用场景,在之前的 这篇文章中 已经有基础的说明,本文不再赘述。
自旋锁
基础概念在 死锁、活锁、饥饿、自旋锁 一文中 已经介绍过,这里不再赘述,其中自旋锁操作获取锁的核心代码如下:
// 获取自旋锁
func (sl *spinLock) lock() {
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
// 获取到自旋锁
}
}
上面的代码直观上很符合自旋锁的语义,只要没有获取到锁,就一直空转 CPU 尝试获取锁,但是这会带来一个问题: CPU 空转带来了很大的资源浪费, 是否可以降低甚至避免这种资源浪费吗?
一个显而易见的方法是在每两次获取锁的操作之间休眠一下,但是这样做会带来两个新的问题:
- 延迟增加,本来也许下次获取锁就可以成功,但是现在必须等休眠结束才能继续获取锁
- 引起上下文切换,因为当前 goroutine 休眠,根据 GMP 调取器的管理规则,处理器 P 会切换到其他可以运行的 goroutine, 如果当前 P 的 goroutine 队列已经是空的, 那么会给当前 M 关联一个新的处理器,不管是哪种情况发生,都会引起上下文切换
优化版
看起来似乎没有完美的解决方案,笔者前两两天在阅读 ants 的源代码时,看到作者是这样处理自旋锁的:
const maxBackoff = 16
func (sl *spinLock) Lock() {
backoff := 1
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
for i := 0; i < backoff; i++ {
runtime.Gosched()
}
if backoff < maxBackoff {
backoff <<= 1
}
}
}
作者借鉴了 TCP 流量控制中的指数退避理念,每两次获取锁的间隔时间呈指数级别增长,并且在间隔时间内执行 N 次 GMP 调取,当然这是根据该组件的场景特性决定的 (goroutine pool), 在实际项目中实现和使用自旋锁时,也可以根据具体的业务场景来自定义间隔时间内的操作,比如可以执行一个 CPU 密集型的任务,最终的目的只有一个: 尽可能榨干 CPU 资源。
基准测试
首先来对标准库中的互斥锁、普通自旋锁、优化版自旋锁做一个简单的基准测试。
// 普通自旋锁实现 --------------------------------------------
type originSpinLock uint32
func (sl *originSpinLock) Lock() {
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
runtime.Gosched()
}
}
func (sl *originSpinLock) Unlock() {
atomic.StoreUint32((*uint32)(sl), 0)
}
func NewOriginSpinLock() sync.Locker {
return new(originSpinLock)
}
// 优化自旋锁实现 --------------------------------------------
type spinLock uint32
const maxBackoff = 16
func (sl *spinLock) Lock() {
backoff := 1
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
for i := 0; i < backoff; i++ {
runtime.Gosched()
}
if backoff < maxBackoff {
backoff <<= 1
}
}
}
func (sl *spinLock) Unlock() {
atomic.StoreUint32((*uint32)(sl), 0)
}
func NewSpinLock() sync.Locker {
return new(spinLock)
}
// 标准库的互斥锁
func BenchmarkMutex(b *testing.B) {
m := sync.Mutex{}
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
m.Lock()
m.Unlock()
}
})
}
// 普通自旋锁
func BenchmarkSpinLock(b *testing.B) {
spin := NewOriginSpinLock()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
spin.Lock()
spin.Unlock()
}
})
}
// 优化版自旋锁
func BenchmarkBackOffSpinLock(b *testing.B) {
spin := NewSpinLock()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
spin.Lock()
spin.Unlock()
}
})
}
从测试结果可以看到,优化后的自旋锁相比普通自旋锁和互斥锁,性能有了很大的提高。
// goos: linux
// goarch: amd64
// cpu: Intel(R) Core(TM) i5-8300H CPU @ 2.30GHz
// BenchmarkMutex
// BenchmarkMutex-8 21886387 55.83 ns/op
// BenchmarkSpinLock
// BenchmarkSpinLock-8 46848830 25.81 ns/op
// BenchmarkBackOffSpinLock
// BenchmarkBackOffSpinLock-8 55894545 21.16 ns/op
分段锁
分段锁 (Segmented Locking) 是一种并发控制的技术,它将共享资源划分成多个不重叠的片段,并对每个片段进行独立的加锁,通过这种方法可以减小锁的粒度,提高系统的并发性能。
使用分段锁时,每个线程只需要获取 key 所在的范围片段的锁,而不必像互斥锁那样锁住并独占整个共享资源,有效避免了多个线程因为竞争全局锁而导致的等待和延迟,提高系统的并发性能。
虽然分段锁可以提高系统的并发性能,但同时也会增加锁冲突的概率,并且需要付出额外的开销来维护锁的状态 (互斥锁只需要一把全局锁即可,分段锁每个区间范围都需要一把锁)。
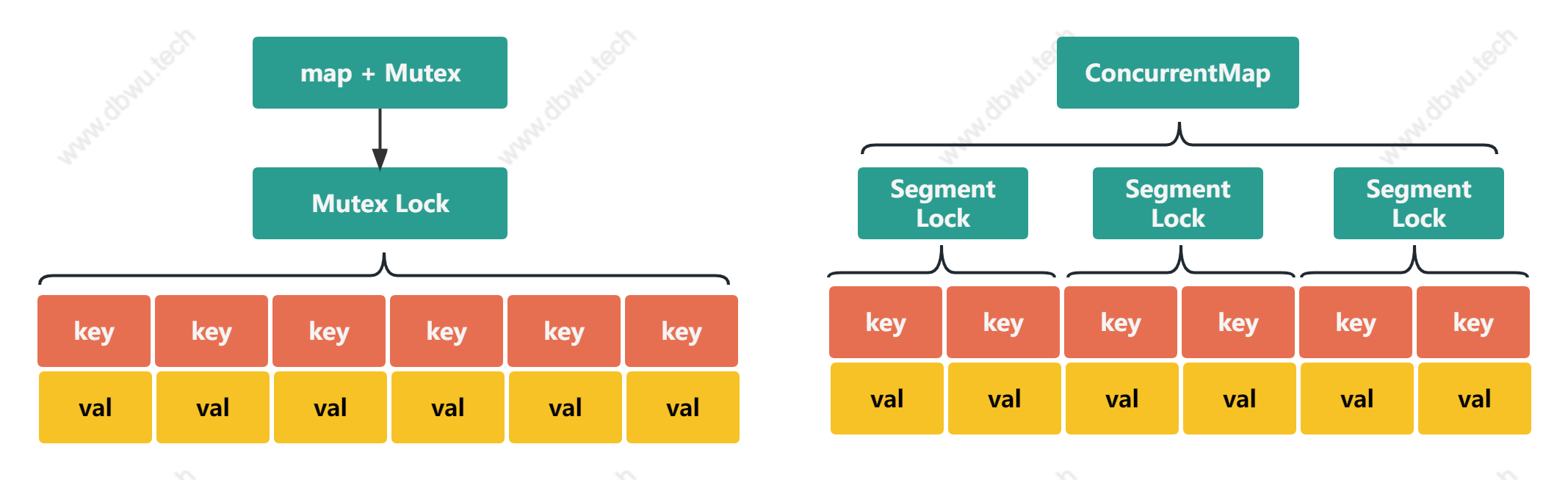
代码实现
笔者在项目中用到的分段锁组件是开源的 concurrent-map, 下面就以该组件的源代码为基础,来分析如何实现一个分段锁,本文选用实现了泛型的 v2 版本。
Map 对象
ConcurrentMap 对象表示实现了分段锁的 Map 对象,内部有两个字段:
- 表示区域元素对象的 shares 字段
- 表示哈希函数的 sharding 字段
type ConcurrentMap[K comparable, V any] struct {
shards []*ConcurrentMapShared[K, V]
sharding func(key K) uint32
}
GetShard 方法用于计算给定的参数 key 对应的区间元素集合对象并返回。
func (m ConcurrentMap[K, V]) GetShard(key K) *ConcurrentMapShared[K, V] {
// 优化版: m % n = m & ( n - 1 )
return m.shards[uint(m.sharding(key))%uint(SHARD_COUNT)]
}
区间元素集合对象
ConcurrentMapShared 对象表示 Map 中某个区间元素集合对象,内部有两个字段:
- 用于存储具体元素的 map, 数据结构就是标准库中的 map 类型
- 内嵌一个读写锁,用于管理对 map 结构的读写并发控制
type ConcurrentMapShared[K comparable, V any] struct {
items map[K]V
sync.RWMutex
}
操作原语
下面来看一下常用的几个操作原语的代码实现。
1. SET
方法的内部执行分为 4 步:
- 通过 key 获取区间元素集合对象
- 获取写锁
- 写入 key 对应的数据
- 释放写锁
func (m ConcurrentMap[K, V]) Set(key K, value V) {
shard := m.GetShard(key)
shard.Lock()
shard.items[key] = value
shard.Unlock()
}
2. GET
方法的内部执行分为 4 步:
- 通过 key 获取区间元素集合对象
- 获取读锁
- 写入 key 对应的数据
- 释放读锁
func (m ConcurrentMap[K, V]) Get(key K) (V, bool) {
shard := m.GetShard(key)
shard.RLock()
val, ok := shard.items[key]
shard.RUnlock()
return val, ok
}
3. Has
出了返回值之外,内部实现和 GET 方法实现一致,这里不在赘述。
func (m ConcurrentMap[K, V]) Has(key K) bool {
shard := m.GetShard(key)
shard.RLock()
_, ok := shard.items[key]
shard.RUnlock()
return ok
}
4. Remove
方法的内部执行分为 4 步:
- 通过 key 获取区间元素集合对象
- 获取写锁
- 写入 key 对应的数据
- 释放写锁
func (m ConcurrentMap[K, V]) Remove(key K) {
shard := m.GetShard(key)
shard.Lock()
delete(shard.items, key)
shard.Unlock()
}
哈希算法
FNV32 是一种快速哈希函数,采用 32 位哈希值,算法实现非常简单并且具有很高的性能和较低的哈希碰撞率。
值得注意的是,concurrent-map 并没有使用标准库的 "hash/fnv" 方法作为求内部哈希函数实现,而是在组件内部重新实现了一个 fnv32 函数,
但是算法用到的算子常数 FNV_PRIME 和 FNV_OFFSET_BASIS, concurrent-map 和标准库是保持一致的,感兴趣的读者可以对比一下实现差异。
func strfnv32[K fmt.Stringer](key K) uint32 {
return fnv32(key.String())
}
func fnv32(key string) uint32 {
...
}
除此之外,也可以通过 NewWithCustomShardingFunction 函数在创建 Map 时来指定哈希函数:
func NewWithCustomShardingFunction[K comparable, V any](sharding func(key K) uint32) ConcurrentMap[K, V] {
return create[K, V](sharding)
}
sync.Map
标准库中的 sync.Map 的底层实现和应用场景在之前的 这篇文章中 已经有基础的说明,本文不再赘述。
基准测试
最后,我们对文章开头提到的三种方案进行基准测试,根据测试结果来总结不同方案的各自适用场景。
下面的测试代码分别对 读多写少、读少写多、读写均等这三种常见的负载场景,进行了性能基准测试:
package maps
import (
"strconv"
"sync"
"testing"
cmap "github.com/orcaman/concurrent-map/v2"
)
// 线程安全 Map 接口
type ThreadSafeMap interface {
Get(key string) any
Set(key string, val any)
}
// -------------------------------------------------------------------
// map 数据类型 + 读写锁实现线程安全的 map
type MutexMap struct {
sync.RWMutex
m map[string]any
}
func (m *MutexMap) Get(key string) any {
m.RLock()
v, ok := m.m[key]
m.RUnlock()
if ok {
return v
}
return nil
}
func (m *MutexMap) Set(key string, val any) {
m.Lock()
m.m[key] = val
m.Unlock()
}
// -------------------------------------------------------------------
// sync.Map 实现线程安全的 map
type SyncMap struct {
m sync.Map
}
func (s *SyncMap) Get(key string) any {
v, _ := s.m.Load(key)
return v
}
func (s *SyncMap) Set(key string, val any) {
s.m.Store(key, val)
}
// -------------------------------------------------------------------
// 分段锁实现线程安全的 map
type ConcurMap struct {
m cmap.ConcurrentMap[string, any]
}
func (c *ConcurMap) Get(key string) any {
v, _ := c.m.Get(key)
return v
}
func (c *ConcurMap) Set(key string, val any) {
c.m.Set(key, val)
}
// 基准测试
func benchmark(b *testing.B, m ThreadSafeMap, read, write int) {
for i := 0; i < b.N; i++ {
var wg sync.WaitGroup
// 注意: 这里的读写操作有一部分 key 是重合的
// 读操作
for k := 0; k < read*100; k++ {
wg.Add(1)
go func(key int) {
m.Get(strconv.Itoa(i * key))
wg.Done()
}(k)
}
// 写操作
for k := 0; k < write*100; k++ {
wg.Add(1)
go func(key int) {
m.Set(strconv.Itoa(i*key), key)
wg.Done()
}(k)
}
wg.Wait()
}
}
// 读写比例 9:1
func BenchmarkReadMoreRWMutex(b *testing.B) { benchmark(b, &MutexMap{m: make(map[string]any)}, 9, 1) }
func BenchmarkReadMoreSyncMap(b *testing.B) { benchmark(b, &SyncMap{m: sync.Map{}}, 9, 1) }
func BenchmarkReadMoreConcurMap(b *testing.B) { benchmark(b, &ConcurMap{m: cmap.New[any]()}, 9, 1) }
// 读写比例 1:9
func BenchmarkWriteMoreRWMutex(b *testing.B) { benchmark(b, &MutexMap{m: make(map[string]any)}, 1, 9) }
func BenchmarkWriteMoreSyncMap(b *testing.B) { benchmark(b, &SyncMap{m: sync.Map{}}, 1, 9) }
func BenchmarkWriteMoreConcurMap(b *testing.B) { benchmark(b, &ConcurMap{m: cmap.New[any]()}, 1, 9) }
// 读写比例 5:5
func BenchmarkEqualRWMutex(b *testing.B) { benchmark(b, &MutexMap{m: make(map[string]any)}, 5, 5) }
func BenchmarkEqualSyncMap(b *testing.B) { benchmark(b, &SyncMap{m: sync.Map{}}, 5, 5) }
func BenchmarkEqualConcurMap(b *testing.B) { benchmark(b, &ConcurMap{m: cmap.New[any]()}, 5, 5) }
运行基准测试:
$ go test -count=1 -run='^$' -bench=. -benchtime=3s -benchmem
输出结果如下:
goos: linux
goarch: amd64
cpu: Intel(R) Core(TM) i5-8300H CPU @ 2.30GHz
BenchmarkReadMoreRWMutex-8 9107 362827 ns/op 84094 B/op 3001 allocs/op
BenchmarkReadMoreSyncMap-8 7740 765258 ns/op 128974 B/op 3284 allocs/op
BenchmarkReadMoreConcurMap-8 10000 345271 ns/op 83985 B/op 3000 allocs/op
BenchmarkWriteMoreRWMutex-8 6212 825778 ns/op 137330 B/op 3656 allocs/op
BenchmarkWriteMoreSyncMap-8 3352 1155236 ns/op 157766 B/op 6041 allocs/op
BenchmarkWriteMoreConcurMap-8 9480 370214 ns/op 119970 B/op 3653 allocs/op
BenchmarkEqualRWMutex-8 7108 529450 ns/op 104626 B/op 3249 allocs/op
BenchmarkEqualSyncMap-8 5360 735393 ns/op 133008 B/op 4601 allocs/op
BenchmarkEqualConcurMap-8 9548 347809 ns/op 104303 B/op 3250 allocs/op
PASS
从基准测试的输出结果来看,不论是哪种应用场景,结合运行速度还是内存分配,三者的排序都是一致的: 分段锁优于读写锁 + map, 后者优于 sync.Map 。 笔者没有遇到过 100% 的只读或只写操作的应用场景,所以没有做对应的基准测试,不过这里可以猜测一下:
- 100% 只读场景下 sync.Map 的性能最好 (不过既然都 100% 只读了, 直接使用 map 类型即可,因为无需加锁,所以性能肯定最高)
- 100% 只写场景下 分段锁 的性能最好
感兴趣的读者可以通过调整基准测试代码的百分比参数来验证一下,这里是 concurrent-map 官方的基准测试代码。
小结
本文主要介绍了在 Go 语言中如何实现线程安全的 map 的三种方法,并通过三种常见的业务场景对方法进行了性能基准测试,最后,我们来简单总结下三种方法的特点。
| 方案 | 优点 | 不足 |
|---|---|---|
| 读写锁 + map | 自定义性最强,性能适中 | 需要开发实现 |
| sync.Map | 标准库自带,开箱即用,方便省心 | 性能较低, API 参数类型是 any,需要数据类型转换 |
| 分段锁 | 性能最好 | 标准库未提供,需要引入第三方组件 |
