zap 高性能设计与实现
概述
zap 是 Uber 开源的 Go 高性能日志库,性能远超于标准库和其他开源日志库。zap 使用简单,支持多种格式结构化日志、可以设置不同的日志级别,并且能够在堆栈跟踪中记录调用者信息。
为什么要使用 zap
| 功能/库 | 标准库 log | zap |
|---|---|---|
| 日志级别 | 只有 Print 在生产可用,因为 Fatal 级别会终止进程,Panic 级别会抛出 panic | 支持多种日志级别 |
| 日志结构化 | 仅支持简单本文 | 支持 JSON, 并且支持自定义结构 |
| 日志切割 | ❌ | ✅ |
基准测试
官方给出了 3 种数据复杂度类型的基准测试结果,从测试结果表格中可以看到,除了 zerolog 库之外,zap 的性能远超其他开源库。
为什么我们不直接分析 zerolog 库的实现呢?根本的原因在于 zerolog 是专门为 JSON 日志格式设计 (也就是只支持 JSON 日志格式),
在某些需要其他格式日志信息的场景下,无法兼容或者需要二次开发,相比之下,zap 在功能易用性和性能方面有更强的优势。
1 条消息和 10 个字段
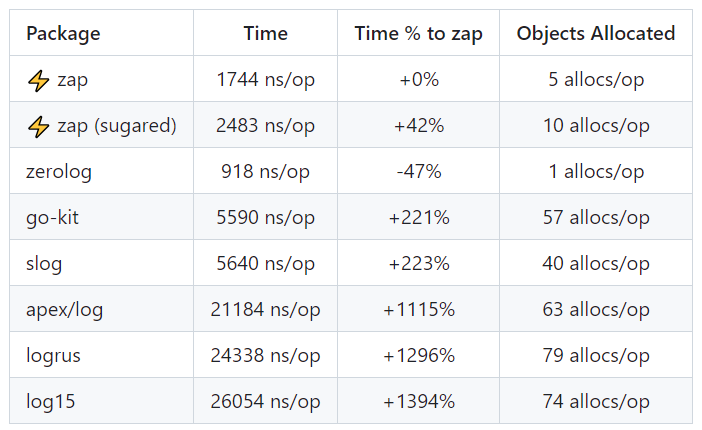
包含 10 个字段的消息
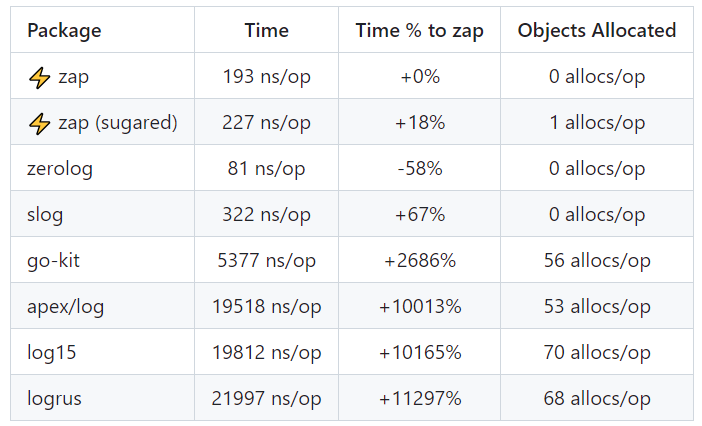
只记录 1 条消息
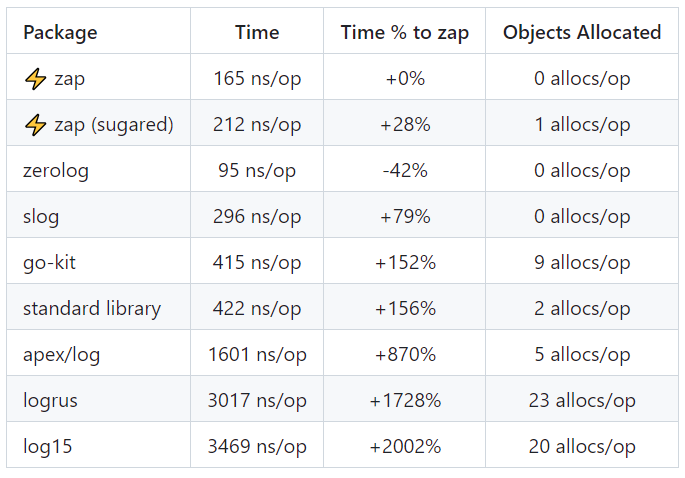
示例
SugaredLogger
当性能不是第一考虑要素时,可以使用 SugaredLogger, 支持键值对形式的日志信息,需要注意的是,这里说的 键值对形式 并不是指类似 map[any]any 这种数据结构,
而是可以根据业务场景,直接将自定义的多个参数以 键,值 的形式传入 SugaredLogger 的相关日志方法,这极大提高了 API 的灵活性,比如同一类型的日志消息,
我们可以使用固定的 键,但是使用不同数据结构中的 值,这样形成两两组合,达到 不同的业务场景通过相同的结构最后写入不同的日志数据 (多态性)。
| 键 - 值 (的数据结构) | struct | map | string | any |
|---|---|---|---|---|
| url | ✅ | ✅ | ✅ | ✅ |
| attempt | ✅ | ✅ | ✅ | ✅ |
| backoff | ✅ | ✅ | ✅ | ✅ |
package main
import (
"go.uber.org/zap"
"time"
)
func main() {
logger, _ := zap.NewProduction()
defer logger.Sync() // 刷回缓冲区
sugar := logger.Sugar()
url := "https://www.example.com"
sugar.Infow("failed to fetch URL",
"url", url,
"attempt", 3,
"backoff", time.Second,
)
sugar.Infof("Failed to fetch URL: %s", url)
}
$ go run main.go
# 输出如下
{"level":"info","ts":1680601481.089163,"caller":"go-high-performance/main.go:14","msg":"failed to fetch URL","url":"https://www.example.com","attempt":3,"backoff":1}
{"level":"info","ts":1680601481.0892165,"caller":"go-high-performance/main.go:20","msg":"Failed to fetch URL: https://www.example.com"}
将输出 JSON 字符串格式化:
{
"level": "info",
"ts": 1680601481.089163,
"caller": "go-high-performance/main.go:14",
"msg": "failed to fetch URL",
"url": "https://www.example.com",
"attempt": 3,
"backoff": 1
}
{
"level": "info",
"ts": 1680601481.0892165,
"caller": "go-high-performance/main.go:20",
"msg": "Failed to fetch URL: https://www.example.com"
}
默认情况下, SugaredLogger 的日志信息结构除了开发者定义的键值外,还会附带 3 个键值对,分别是:
| 键 | 值 |
|---|---|
| level | 日志级别 |
| ts | 时间戳 |
| caller | 调用方 |
Logger
当性能是第一考虑要素时,请使用 Logger, 它比 SugaredLogger 性能更高且内分配更少,作为性能代价,Logger 只支持结构化日志记录。
package main
import (
"go.uber.org/zap"
"time"
)
func main() {
logger, _ := zap.NewProduction()
defer logger.Sync()
url := "https://www.example.com"
logger.Info("failed to fetch URL",
zap.String("url", url),
zap.Int("attempt", 3),
zap.Duration("backoff", time.Second),
)
}
输出日志除了 时间戳 字段外,其他字段和刚才的日志没有任何区别。通过代码我们可以看到: Logger 比 SugaredLogger 在应用层面多了一层约束,
每个日志字段必须调用 zap 中的类型方法来声明其类型,例如上面例子中的 zap.String, zap.Int, zap.Duration。
代码分析
我们来分析下 zap 的源代码,着重研究其高性能背后的技术实现,笔者选择的版本为 v1.24.0。
对象复用
zap组件内部对位于hot path上面的对象使用对象池管理进行复用。
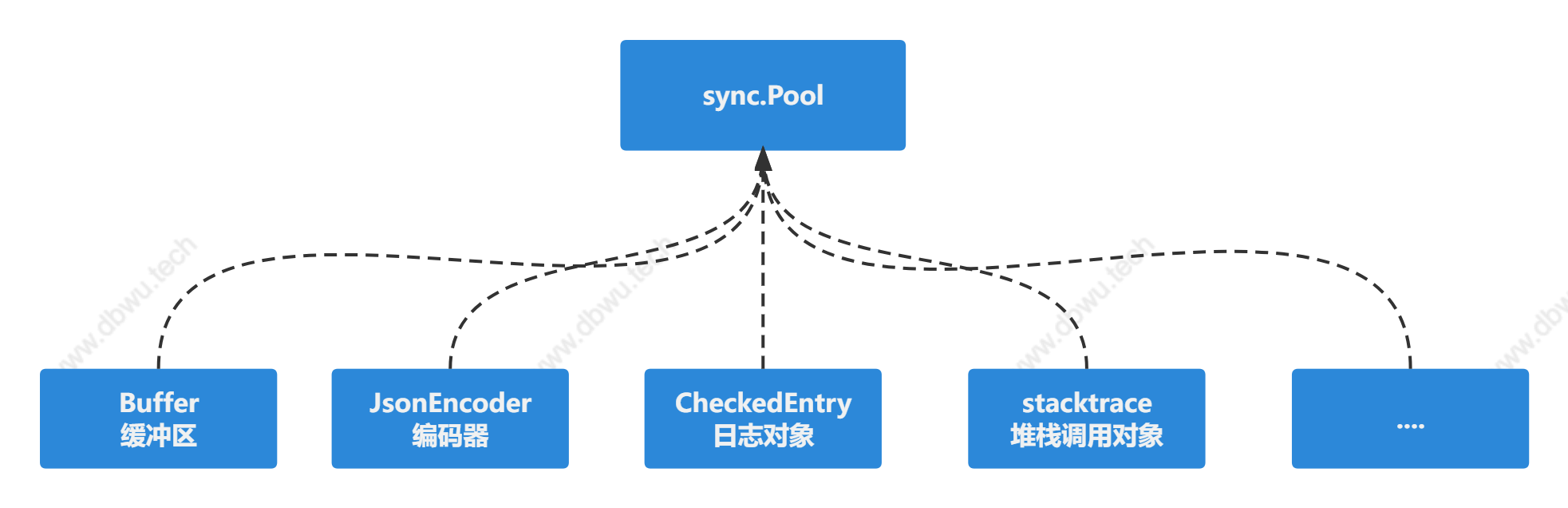
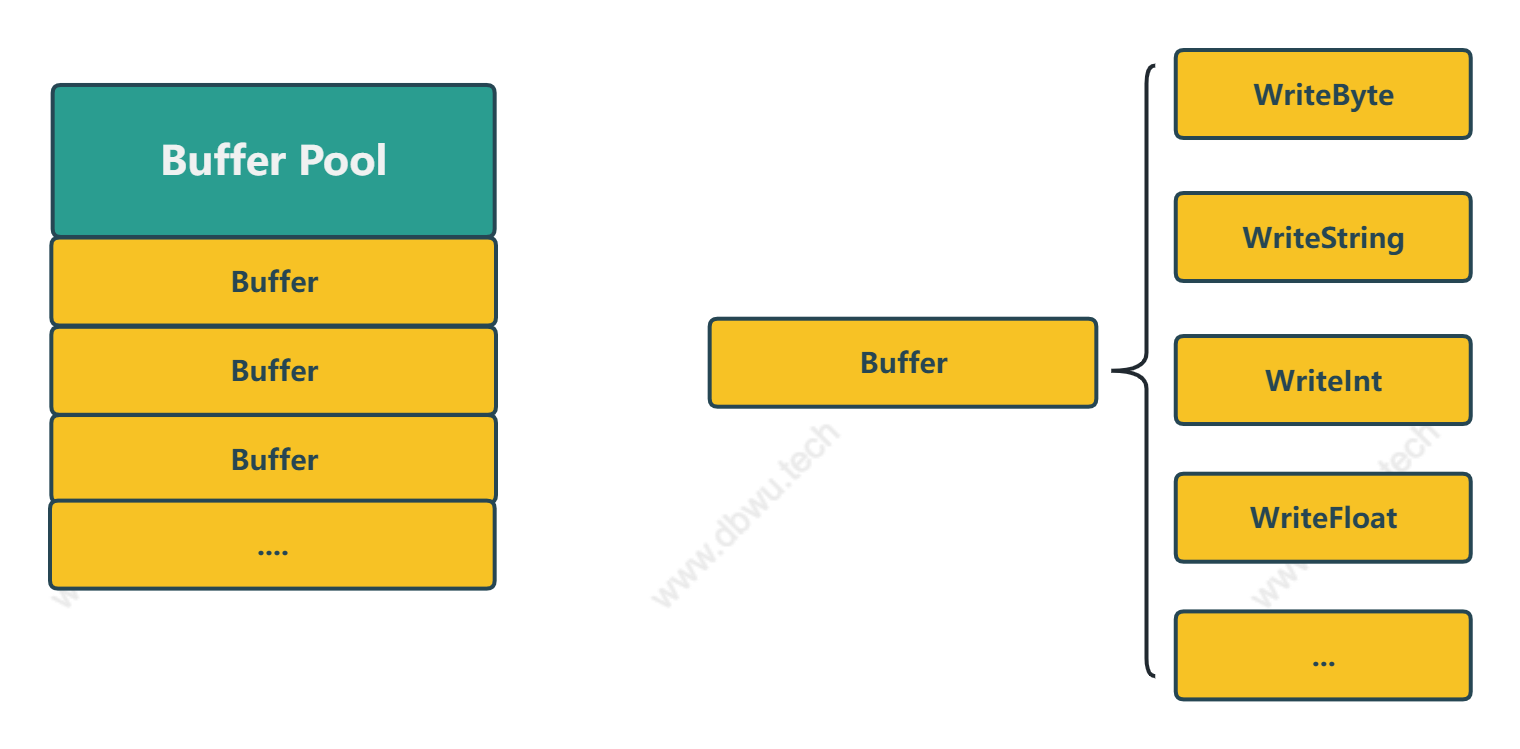
下面以 Buffer 缓冲区 对象复用为例,分析一下内部代码,其他几个对象实现都是类似的,具体到后面用到时再分析。
缓冲区对象池
日志库很重要的一部分就是处理输入的日志字符串,zap 在内部采用了 []byte 缓冲区 + 对象池 的管理模式,对象池沿用了标准库中的 sync.Pool,
但是 []byte 缓冲区 并没有使用标准库中的 bytes.Buffer, 而是自己独立实现了一套,主要原因有两个:
bytes.Buffer仅支持 {byte,[]byte,rune,string} 4 种数据类型的直接写入,不满足zap日志信息多种数据类型的写入场景- 独立实现的支持多种数据类型的
缓冲区可以配合zap内置的编码器进一步提升性能
核心代码
// 默认的缓冲区大小为 1 KB
const _size = 1024
// 缓冲区对象
type Buffer struct {
// 底层切片
bs []byte
// 对象池的引用
// 这个字段主要是为了 Free 方法的语义化
// 缓冲区的归还操作可以直接调用 buf.Free,而不需要间接调用 pool.Put(buf)
pool Pool
}
// 重置缓冲区
// 直接复用了原有的数据区域,实现零分配
func (b *Buffer) Reset() {
b.bs = b.bs[:0]
}
// 归还缓冲区到对象池
func (b *Buffer) Free() {
b.pool.put(b)
}
// 获取对象池
func NewPool() Pool {
return Pool{p: &sync.Pool{
New: func() interface{} {
// 初始化缓冲区时预分配容量,提升性能
return &Buffer{bs: make([]byte, 0, _size)}
},
}}
}
缓冲区的默认大小为1KB, 这也提醒我们要合理控制单条日志的数据量大小,避免缓冲区底层的[]byte数据结构发生扩容带来的性能损耗。
自定义数据类型
zap 将数据类型全部映射为自定义常量:
type FieldType uint8
const (
UnknownType FieldType = iota
...
BoolType
Float64Type
Int64Type
StringType
...
)
字段对象
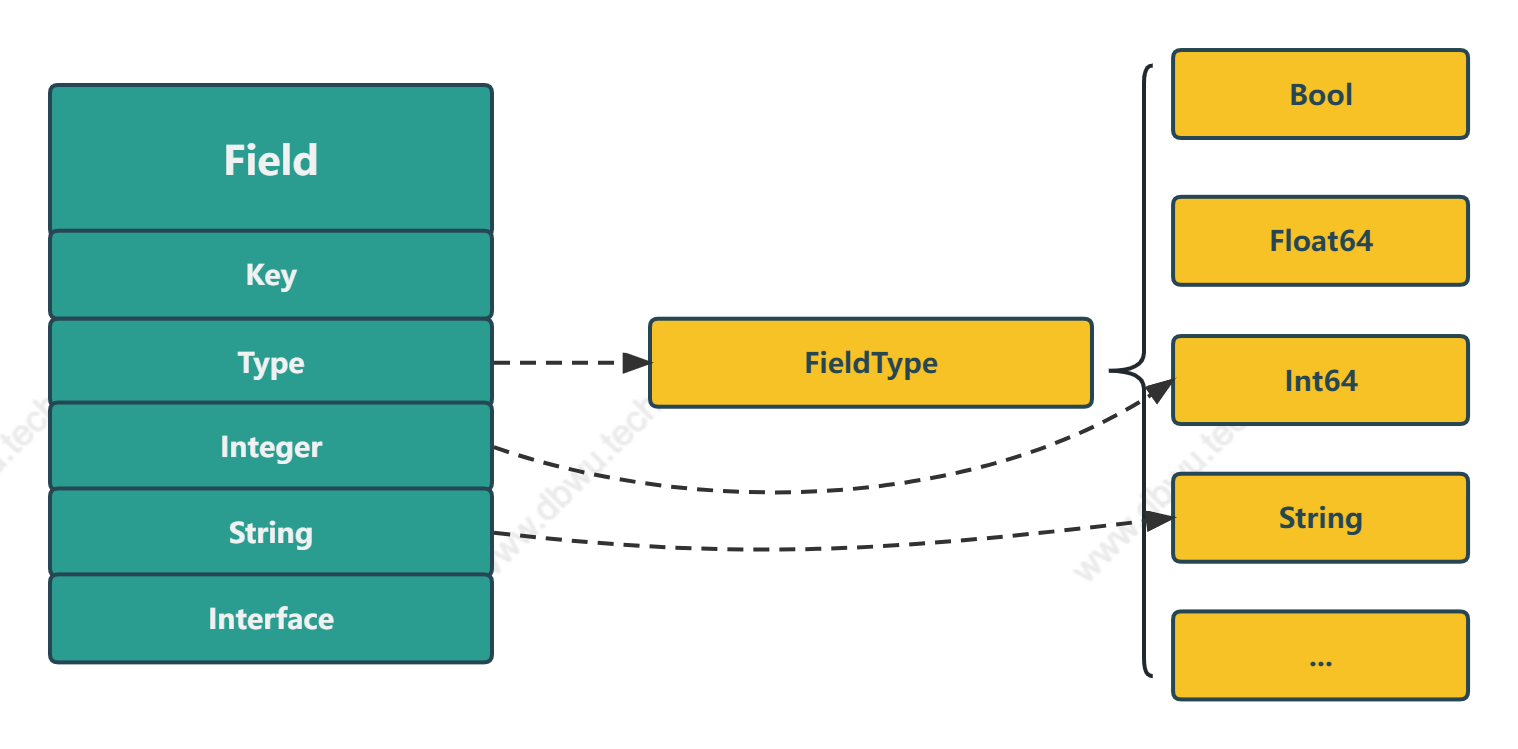
Field 对象表示日志信息中的单个字段,字段包装 方法通过 Type 字段将具体的数据包装为 Field 对象,编码器可以通过 Type 字段得出该对象所表示的具体类型,然后在对应的数据字段取值。
例如 Type 是 Int64Type, 编码器 就会获取 Integer 字段的值,Type 是 StringType, 编码器 就会获取 String 字段的值。
type Field struct {
// 字段名称
Key string
// 字段类型
Type FieldType
// 存储所有数值类型数据
Integer int64
// 存储字符串类型数据
String string
// 存储所有除 数值/字符串 之外的其他类型数据
Interface interface{}
}
Field 通过 1 个类型字段加 3 个数据字段的组合,使编码器对象巧妙地实现了多态性 (根据不同的类型获取不同的值),最重要的是,完全规避了反射。
字段对象包装
调用 zap.Int64, zap.String 等方法时,会根据参数的数据类型,返回一个包装好的 Field 对象。
// 将类型为 int64 的参数包装为 Field 对象
func Int64(key string, val int64) Field {
return Field{Key: key, Type: zapcore.Int64Type, Integer: val}
}
// 将类型为 string 的参数包装为 Field 对象
func String(key string, val string) Field {
return Field{Key: key, Type: zapcore.StringType, String: val}
}
当然了,为了提升开发效率 (摸鱼),我们可以直接调用 zap.Any 方法自动转换数据类型:
func Any(key string, value interface{}) Field {
switch val := value.(type) {
...
case bool:
return Bool(key, val)
case float64:
return Float64(key, val)
case int64:
return Int64(key, val)
case string:
return String(key, val)
...
}
自定义编码器
标准库中的 json.Marshal 方法内部是基于 反射 实现的,极大地降低了效率。
func Marshal(v any) ([]byte, error) {
e := newEncodeState()
err := e.marshal(v, encOpts{escapeHTML: true})
...
}
func (e *encodeState) marshal(v any, opts encOpts) (err error) {
...
e.reflectValue(reflect.ValueOf(v), opts)
...
}
zap 没有调用标准库的方法,而是实现了一套自定义的 编码器,完全避免了使用 反射 带来的性能损耗。
编码器接口
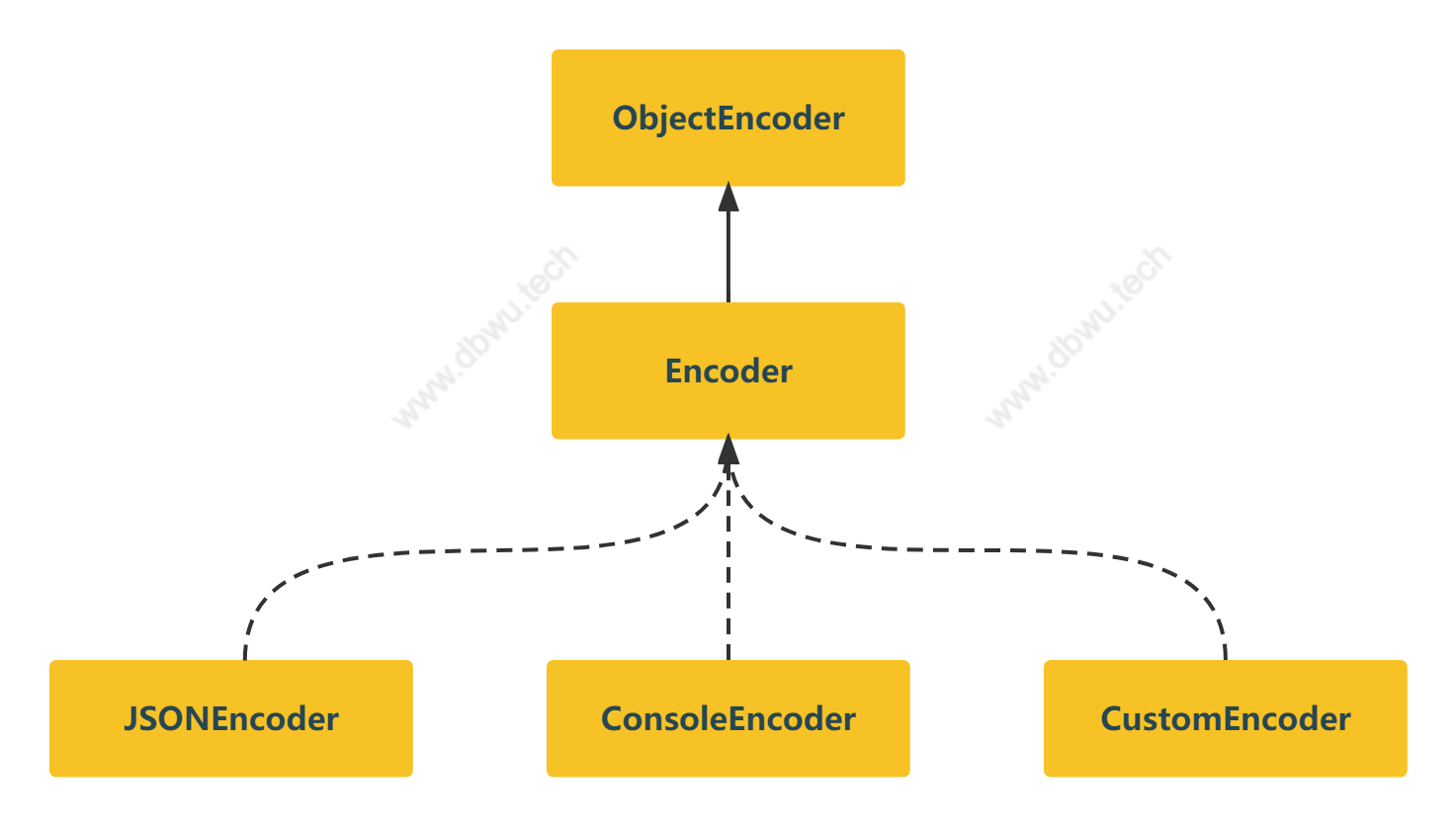
ObjectEncoder 接口表示基础数据和复合数据的编码器。
type ObjectEncoder interface {
// 复合数据格式化
AddArray(key string, marshaler ArrayMarshaler) error
AddObject(key string, marshaler ObjectMarshaler) error
// 基础数据格式化方法
AddBool(key string, value bool)
AddInt64(key string, value int64)
AddString(key, value string)
...
}
Encoder 接口表示不同类型的日志格式编码,其中内嵌了一个 ObjectEncoder 接口用于格式化基础数据和复合数据 (主要是数组和对象)。
type Encoder interface {
ObjectEncoder
// 返回当前对象的深拷贝
Clone() Encoder
// 编码日志消息,将格式化后的日志数据直接写入缓冲区中
EncodeEntry(Entry, []Field) (*buffer.Buffer, error)
}
编码器接口实现
zap 内置了两种编码器实现: JSON 和 Console (文本) 编码器,下面分析下 JSON 编码器的具体实现。
JSON 编码器结构体
jsonEncoder 表示 JSON 编码器,实现了 Encoder 编码器接口。
type jsonEncoder struct {
// 编码器配置对象
*EncoderConfig
// 编码后的 JSON 字符存储缓冲区
buf *buffer.Buffer
// 编码后的 JSON 字符存是否在冒号和逗号后面加空格
spaced bool
// 对象嵌套层数
openNamespaces int
// 通过反射编码基础数据类型
reflectBuf *buffer.Buffer
// 反射编码器
reflectEnc ReflectedEncoder
}
JSON 编码器结对象池
zap 采用了对象池来管理编码器对象,因为其位于 hot path, 对象池可以避免对象创建和回收带来的性能损耗,提升性能。
// JSON 编码器对象池
var _jsonPool = sync.Pool{New: func() interface{} {
return &jsonEncoder{}
}}
// 申请对象
func getJSONEncoder() *jsonEncoder {
return _jsonPool.Get().(*jsonEncoder)
}
// 归还对象
func putJSONEncoder(enc *jsonEncoder) {
...
_jsonPool.Put(enc)
}
JSON 编码器深拷贝
func (enc *jsonEncoder) Clone() Encoder {
clone := enc.clone()
// 复制缓冲区内容
clone.buf.Write(enc.buf.Bytes())
return clone
}
// 深拷贝内部实现
func (enc *jsonEncoder) clone() *jsonEncoder {
// 从对象池中获取一个编码器对象
clone := getJSONEncoder()
...
// 从对象池中获取一个 buffer 对象
clone.buf = bufferpool.Get()
return clone
}
JSON 编码日志
EncodeEntry 方法将日志信息编码为 JSON 后写入字符串缓冲对象然后返回 (字符串缓冲对象也是通过对象池管理的,规避了内存分配),
方法内部实现中,编码器根据不同的字段类型和数据信息,调用对应的的编码方法生成字段编码,最后采用最朴素的 字符串拼接 生成日志编码字符串,规避了反射。
func (enc *jsonEncoder) EncodeEntry(ent Entry, fields []Field) (*buffer.Buffer, error) {
// 深拷贝一个当前的对象,这样对拷贝对象的操作不会影响当前对象
final := enc.clone()
// 开始写入字符串到缓冲区,第一个为字符为 {
final.buf.AppendByte('{')
// 首先写入日志的基本字段
if final.LevelKey != "" && final.EncodeLevel != nil {
// 写入日志级别
...
}
if final.TimeKey != "" {
// 写入时间戳
...
}
if ent.LoggerName != "" && final.NameKey != "" {
// 写入日志名称
...
}
if final.MessageKey != "" {
// 写入日志 msg
...
}
// 然后写入日志的自定义字段
addFields(final, fields)
// 根据字段对象的嵌套层数补充对应的 } 字符
final.closeOpenNamespaces()
if ent.Stack != "" && final.StacktraceKey != "" {
// 写入堆栈信息
final.AddString(final.StacktraceKey, ent.Stack)
}
// 补充和第一个 { 字符对应的 } 字符
final.buf.AppendByte('}')
// 日志结尾写入换行符
final.buf.AppendString(final.LineEnding)
// 将字符串缓冲区数据赋值给返回值变量
ret := final.buf
// 将拷贝的编码器对象归还到对象池中
putJSONEncoder(final)
return ret, nil
}
字段编码
addFields 函数将参数 编码器 作用于具体的字段 (日志调用方自定义的数据字段)。
func addFields(enc ObjectEncoder, fields []Field) {
for i := range fields {
fields[i].AddTo(enc)
}
}
AddTo 方法调用 编码器 对应的方法格式化字段。
func (f Field) AddTo(enc ObjectEncoder) {
var err error
switch f.Type {
case BoolType:
enc.AddBool(f.Key, f.Integer == 1)
case Int64Type:
enc.AddInt64(f.Key, f.Integer)
case StringType:
enc.AddString(f.Key, f.String)
...
}
...
}
下面以 AddBool 方法调用来说明调用过程,其他方法流程是类似的。
func (enc *jsonEncoder) AddBool(key string, val bool) {
enc.addKey(key)
enc.AppendBool(val)
}
func (enc *jsonEncoder) AppendBool(val bool) {
enc.addElementSeparator()
// 写入缓冲区
enc.buf.AppendBool(val)
}
func (b *Buffer) AppendBool(v bool) {
// 调用标准库方法
b.bs = strconv.AppendBool(b.bs, v)
}
func AppendBool(dst []byte, b bool) []byte {
if b {
return append(dst, "true"...)
}
return append(dst, "false"...)
}
接口
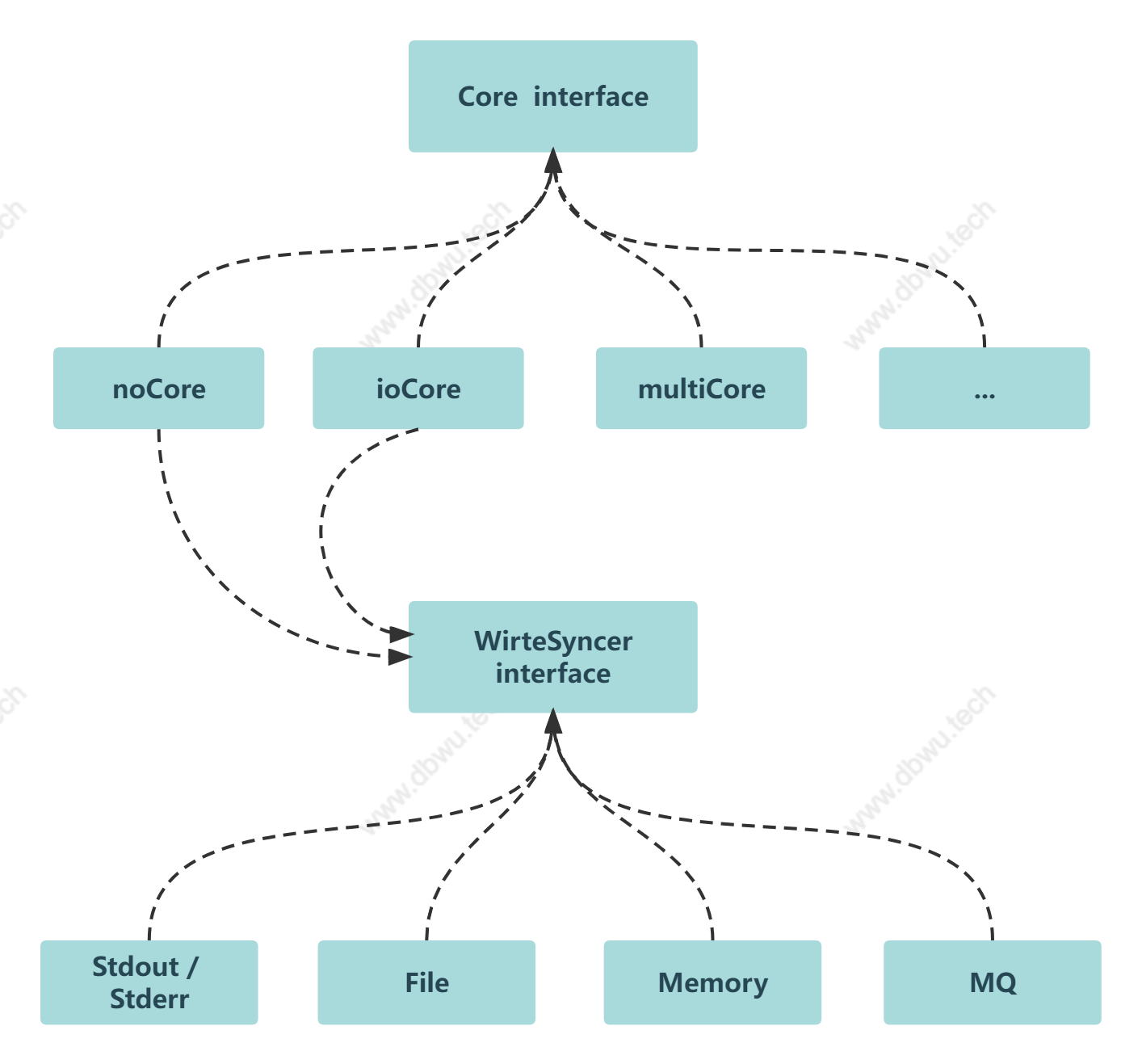
日志接口
Core 表示基础日志接口。
type Core interface {
// 日志等级检测接口
LevelEnabler
// 写入日志自定义字段
With([]Field) Core
// 检测日志是否应该被记录
// 如果日志需要记录,就将参数 Entry 添加到返回值 CheckedEntry
// 该方法可以理解为中间件
// 支持单个检测模式, 例如 ioCore.Check
// 也支持多个检测模式, 例如 multiCore.Check
Check(Entry, *CheckedEntry) *CheckedEntry
// 写入日志 (先写入缓冲区,然后刷出)
Write(Entry, []Field) error
// 刷出缓冲区的日志信息 (Stdout, File, Memory, MessageQueue ...)
Sync() error
}
日志写入接口
WriteSyncer 接口在标准库的 io.Writer 接口的基础上包装了一层,增加了一个 Sync 方法表示将缓冲区数据刷出并写入,标准库中的 Stderr, Stdout, File 都已经实现了该接口。
type WriteSyncer interface {
io.Writer
Sync() error
}
调用方可以使用 zapcore.AddSync 方法设置写入接口,例如:
zapcore.AddSync(os.Stdout)
multiWriteSyncer 对象是一个 WriteSyncer 接口切片,表示将缓冲区数据刷出并写入到多个接口,同时它自身也实现了 WriteSyncer 接口 (非常巧妙的设计)。
type multiWriteSyncer []WriteSyncer
调用方可以使用 zapcore.NewMultiWriteSyncer 方法设置多个输出接口,例如:
zapcore.NewMultiWriteSyncer(os.Stdout, os.Stderr)
在创建方法的内部实现中,如果参数只有一个元素,直接返回,如果参数切片有多个元素,返回包装后的 multiWriteSyncer 对象 (再一次体现了接口设计的扩展性和生命力) 。
func NewMultiWriteSyncer(ws ...WriteSyncer) WriteSyncer {
if len(ws) == 1 {
return ws[0]
}
return multiWriteSyncer(ws)
}
multiWriteSyncer 对象的 Write 方法和 Sync 方法实现机制类似 (相当于装饰器模式),直接遍历切片中的 WriteSyncer 接口元素,然后调用对应的方法即可。
func (ws multiWriteSyncer) Write(p []byte) (int, error) {
for _, w := range ws {
n, err := w.Write(p)
}
}
func (ws multiWriteSyncer) Sync() error {
for _, w := range ws {
err = multierr.Append(err, w.Sync())
}
}
日志等级检测
LevelEnabler 表示日志等级检测接口。
type LevelEnabler interface {
Enabled(Level) bool
}
常规的实现是直接比较日志等级大小,例如 WarnLevel > DebugLevel, InfoLevel < ErrorLevel。
日志事件钩子
CheckWriteHook 表示日志写入完成后要执行的钩子函数接口。
type CheckWriteHook interface {
// 当日志信息完成后调用函数
OnWrite(*CheckedEntry, []Field)
}
4 种类型事件钩子
CheckWriteAction 表示自定义的事件类型,按照事件的严重程度从低到高排序。
type CheckWriteAction uint8
const (
// 不执行任何操作
WriteThenNoop CheckWriteAction = iota
// 调用 runtime.Goexit 方法
WriteThenGoexit
// 抛出一个 panic
WriteThenPanic
// 致命错误,调用 os.Exit(1) 结束程序
WriteThenFatal
)
func (a CheckWriteAction) OnWrite(ce *CheckedEntry, _ []Field) {
switch a {
case WriteThenGoexit:
runtime.Goexit()
case WriteThenPanic:
panic(ce.Message)
case WriteThenFatal:
exit.With(1)
}
}
日志相关对象
日志对象
Logger 表示基础日志对象,SugaredLogger 对象就是在这个基础上面封装了一层。
type Logger struct {
// 内嵌一个最小化日志 Core 接口
core zapcore.Core
// 是否为开发模式
development bool
// 是否输出调用方堆栈
addCaller bool
// 写入日志错误事件钩子函数
// 默认为 WriteThenFatal
onFatal zapcore.CheckWriteHook
// 日志名称
name string
// 日志写入接口实现
errorOutput zapcore.WriteSyncer
// 输出堆栈信息的日志等级
addStack zapcore.LevelEnabler
// 跳过堆栈信息的层数
callerSkip int
// 时间接口,主要用于获取时间戳和设置定时器
clock zapcore.Clock
}
属性设置
Logger 对象的字段属性通过 FUNCTIONAL OPTIONS 模式设置,可以在创建对象时通过传递可变参数设置,也可以在对象创建完成后调用 Logger.WithOptions 方法修改。
type Option interface {
apply(*Logger)
}
type optionFunc func(*Logger)
func (f optionFunc) apply(log *Logger) {
f(log)
}
Logger.WithOptions 方法会拷贝当前的日志对象,并将可变参数选项作用到拷贝的新对象上面,实现写时复制机制。
func (log *Logger) WithOptions(opts ...Option) *Logger {
c := log.clone()
for _, opt := range opts {
opt.apply(c)
}
return c
}
日志等级
Level 表示自定义的日志等级类型,从低到高排序。
type Level int8
const (
DebugLevel Level = iota - 1
InfoLevel // 0
WarnLevel // 1
ErrorLevel // 2
DPanicLevel // 3
PanicLevel // 4
FatalLevel // 5
)
Level 实现了 LevelEnabler 接口。
func (l Level) Enabled(lvl Level) bool {
// 直接比较两个日志等级的大小
return lvl >= l
}
各种日志级别写入方法
Logger 对象将可用的日志等级封装为对应的方法,方便应用层直接调用。
func (log *Logger) Debug(msg string, fields ...Field) {
...
}
func (log *Logger) Info(msg string, fields ...Field) {
...
}
func (log *Logger) Warn(msg string, fields ...Field) {
...
}
...
日志元数据对象
Entry 对象表示日志的元数据,对象只有日志级别、时间戳、消息等几个基础字段,不包含调用方自定义的数据字段。
type Entry struct {
// 日志等级
Level Level
// 日志时间戳
Time time.Time
// 日志名称
LoggerName string
// 日志消息
Message string
// 调用方信息
Caller EntryCaller
// 堆栈信息
Stack string
}
Entry对象并没有使用对象池模式管理,如果使用了对象池的话,性能还能提升一些,当然,官方的考虑可能是几乎不存在重复的日志元数据对象, 对象的每个字段也不存在复用的场景,对象池带来的性能提升不如代码可读性重要 (毕竟,每次从对象池申请对象或归还对象时要重置每个字段)。
通过检测的日志数据对象
CheckedEntry 对象表示通过日志等级检测的日志数据对象,其中内嵌了一个 Entry 对象,在日志写入完成后,应该及时将对象归还到对象池中。
type CheckedEntry struct {
// 日志元数据
Entry
// 日志写入接口
ErrorOutput WriteSyncer
// 标识日志是否已经输出写入,避免多次写入
dirty bool
// {日志写入后事件} 钩子函数
after CheckWriteHook
//
cores []Core
}
日志对象池
zap 采用了对象池来管理 CheckedEntry 对象,和 编码器 对象一样位于 hot path, 对象池可以避免对象创建和回收带来的性能损耗,提升性能。
var (
_cePool = sync.Pool{New: func() interface{} {
...
}}
)
func getCheckedEntry() *CheckedEntry {
...
}
func putCheckedEntry(ce *CheckedEntry) {
...
}
日志写入流程
当调用写入日志方法时 (例如 logger.Info),会经过如下流程:
- 检测写入日志等级和配置等级的匹配度 (例如配置等级为
WarnLevel, 那么DebugLevel和InfoLevel两个等级的日志就不需要写入) - 如果写入日志通过等级检测,将日志数据封装成一个
Entry对象 - 通过
Core.Check中间件方法检测Entry对象,通过检测后生成CheckedEntry对象 - 根据日志等级给
CheckedEntry对象设置对应的钩子函数 - 获取调用堆栈相关信息写入
CheckedEntry.Stack字段 - 获取调用方相关信息写入
CheckedEntry.Caller字段 - 调用
CheckedEntry对象的Write方法写入日志数据 - 日志重复写入检测
- 调用注册的所有
zapcore.Core接口,完成 日志的写入工作 (编码、写入、缓冲区刷出) - 如果 日志的写入工作 过程中出现错误,附加记录一条错误日志
- 调用钩子函数
- 将
CheckedEntry对象归还到对象池中,日志写入结束
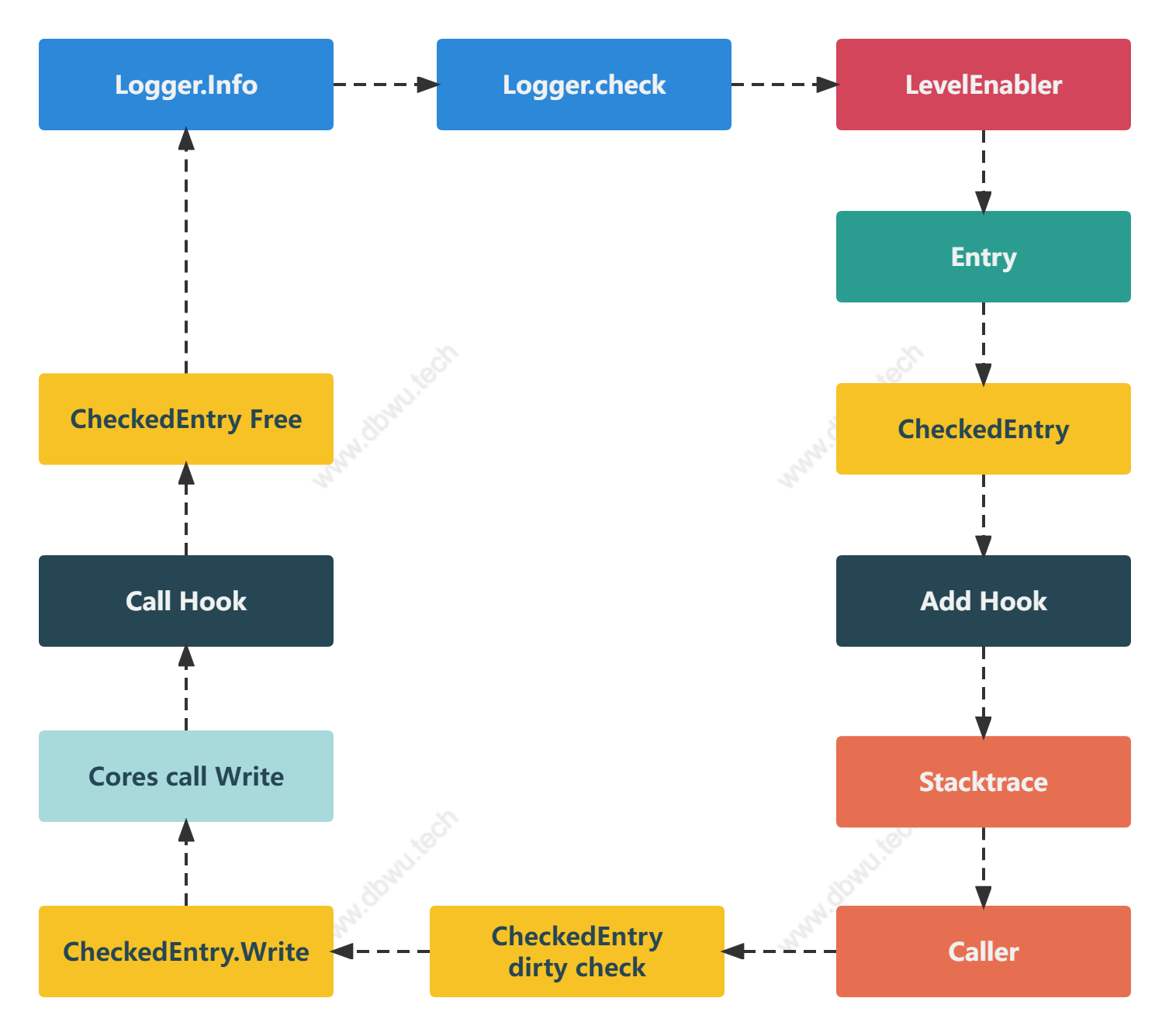
这里以 logger.Info 方法为例,分析一下日志的写入流程。
func (log *Logger) Info(msg string, fields ...Field) {
if ce := log.check(InfoLevel, msg); ce != nil {
ce.Write(fields...)
}
}
Logger.check 方法
check 方法会根据日志等级检测日志是否需要写入,如果需要写入,返回通过检测的日志数据对象 CheckedEntry 。
func (log *Logger) check(lvl zapcore.Level, msg string) *zapcore.CheckedEntry {
// 跳过 2 个调用堆栈:
// 1. Logger.check (也就是当前方法)
// 2. 当前方法的调用方: (Logger.Info, Logger.Fatal 等)
const callerSkipOffset = 2
// 检测写入日志等级和配置等级的匹配度
// 当前日志等级低于配置等级,直接返回
if lvl < zapcore.DPanicLevel && !log.core.Enabled(lvl) {
return nil
}
// 创建一个日志元数据对象
ent := zapcore.Entry{
LoggerName: log.name,
Time: log.clock.Now(),
Level: lvl,
Message: msg,
}
// 调用 Core 接口方法检测日志
ce := log.core.Check(ent, nil)
// 如果返回值不为 nil, 说明当前的日志需要写入
willWrite := ce != nil
// 设置 {日志写入后事件} 钩子函数
switch ent.Level {
case zapcore.PanicLevel:
// 添加 panic 钩子
ce = ce.After(ent, zapcore.WriteThenPanic)
case zapcore.FatalLevel:
onFatal := log.onFatal
// 将 onFatal 默认值设置为 WriteThenFatal (避免调用运行时错误)
if onFatal == nil || onFatal == zapcore.WriteThenNoop {
onFatal = zapcore.WriteThenFatal
}
// 添加 Fatal 钩子
ce = ce.After(ent, onFatal)
case zapcore.DPanicLevel:
if log.development {
// 如果是开发模式,添加 panic 钩子
ce = ce.After(ent, zapcore.WriteThenPanic)
}
}
// 日志不需要写入,直接返回
if !willWrite {
return ce
}
// 将负责写入的对象赋值到通过检测的日志
// PS: ErrorOutput 这个命名感觉不太合理 ?
ce.ErrorOutput = log.errorOutput
addStack := log.addStack.Enabled(ce.Level)
if !log.addCaller && !addStack {
// 如果日志配置为不输出调用方堆栈
// 并且
// 当前日志级别无法匹配启用堆栈的级别
// 默认启用堆栈级别为 FatalLevel+1, 也就是不启用
// 可以创建日志对象时通过 zap.AddStacktrace 方法修改默认级别
// 直接返回当前通过检测的日志对象即可
return ce
}
// 开始获取调用堆栈信息
stackDepth := stacktraceFirst // 默认仅输出调用堆栈的第一层
if addStack {
// 输出调用堆栈的所有层
stackDepth = stacktraceFull
}
// 获取调用堆栈信息
stack := captureStacktrace(log.callerSkip+callerSkipOffset, stackDepth)
defer stack.Free()
if stack.Count() == 0 {
// 没有获取到任何堆栈信息
// 出现这个问题是因为日志初始化设置了过高的 {跳过堆栈层数} 参数
// 可以检查 zap.AddCallerSkip 方法的参数值
if log.addCaller {
// 如果日志配置为输出调用方堆栈
// 显然应用层的配置冲突了,写入一条错误日志
fmt.Fprintf(log.errorOutput, "%v Logger.check error: failed to get caller\n", ent.Time.UTC())
log.errorOutput.Sync()
}
// 直接返回
return ce
}
// 跳过调用当前方法的栈帧 (第一层)
frame, more := stack.Next()
if log.addCaller {
// 如果日志配置为输出调用方堆栈
// 初始化调用方堆栈对象
ce.Caller = zapcore.EntryCaller{
Defined: frame.PC != 0,
PC: frame.PC,
File: frame.File,
Line: frame.Line,
Function: frame.Function,
}
}
if addStack {
// 如果当前日志级别匹配启用堆栈的级别
// 申请一个 buffer 缓冲区用于写入调用堆栈数据
buffer := bufferpool.Get()
defer buffer.Free()
stackfmt := newStackFormatter(buffer)
// 将第一层堆栈信息格式化写入缓冲区
stackfmt.FormatFrame(frame)
if more {
// 将第一层外剩余堆栈信息格式化写入缓冲区
stackfmt.FormatStack(stack)
}
// 将缓冲区堆栈数据赋值到日志的堆栈数据字段
ce.Stack = buffer.String()
}
return ce
}
CheckedEntry.Write 方法
CheckedEntry.Write 方法负责日志的具体写入工作,需要注意的一点是,方法内部会执行日志写入脏检测 (也就是同一条日志多次写入),
什么场景下会触发这种情况呢?例如调用方执行了类似下面的代码:
if ce := logger.Check(zap.DebugLevel, "debugging"); ce != nil {
ce.Write(...) // 正常写入
ce.Write(...) // 不会写入
ce.Write(...) // 不会写入
}
当然实际场景中,都是直接调用包装好的 Logger 对象的写入方法,可以完全避免这个问题。
func (ce *CheckedEntry) Write(fields ...Field) {
// 日志重复写入检测
if ce.dirty {
if ce.ErrorOutput != nil {
// 如果日志已经写入
// 写一条错误日志,直接返回
fmt.Fprintf(ce.ErrorOutput, "%v Unsafe CheckedEntry re-use near Entry %+v.\n", ce.Time, ce.Entry)
// 日志缓冲区刷出并写入
ce.ErrorOutput.Sync()
}
return
}
// 标识日志已经写入
ce.dirty = true
var err error
// 因为日志可能有多个写入接口 (Stdout, File, Memory, MessageQueue ...)
// 遍历, 逐个接口写入
// 每个实现了写入接口的对象,需要在 Write 方法写入前完成日志数据的编码
// 例如: ioCore.Write 方法在写入前将日志编码为内置的 `buffer.Buffer` 对象
// 这里顺便提一下, multierr 也是 uber 开源的一个库,主要用于包装 error,类似 errorGroup
for i := range ce.cores {
err = multierr.Append(err, ce.cores[i].Write(ce.Entry, fields))
}
if err != nil && ce.ErrorOutput != nil {
// 如果有接口写入时发生错误
// 写一条错误日志
fmt.Fprintf(ce.ErrorOutput, "%v write error: %v\n", ce.Time, err)
// 日志缓冲区刷出并写入
ce.ErrorOutput.Sync()
}
hook := ce.after
if hook != nil {
// 如果设置了日志事件钩子
// 则执行对应的钩子函数
hook.OnWrite(ce, fields)
}
// 日志写入完成后,将 CheckedEntry 归还到对象池
putCheckedEntry(ce)
}
调用堆栈对象池
zap 采用了对象池来管理调用堆栈对象,因为其位于 hot path, 对象池可以避免对象创建和回收带来的性能损耗,提升性能。
type stacktrace struct {
...
}
var _stacktracePool = sync.Pool{
New: func() interface{} {
return &stacktrace{
...
}
},
}
captureStacktrace 函数获取调用的堆栈信息,可以通过参数指定需要跳过的堆栈层数。
func captureStacktrace(skip int, depth stacktraceDepth) *stacktrace {
stack := _stacktracePool.Get().(*stacktrace)
// 在参数基础上再跳过 2 层:
// 1. 当前函数
// 2. runtime.Callers
// 注意这里调用的是 runtime.Callers 方法,而非 runtime.Stack (之前的文章讲到过: 两者的性能差距很大)
// 因为后者会触发 STW, 这也是一个高性能的技巧
numFrames := runtime.Callers(
skip+2,
stack.pcs,
)
if depth == stacktraceFull {
// 获取调用堆栈的所有层
...
} else {
// 仅获取调用堆栈的第一层
...
}
stack.frames = runtime.CallersFrames(stack.pcs)
return stack
}
zap 组件结构
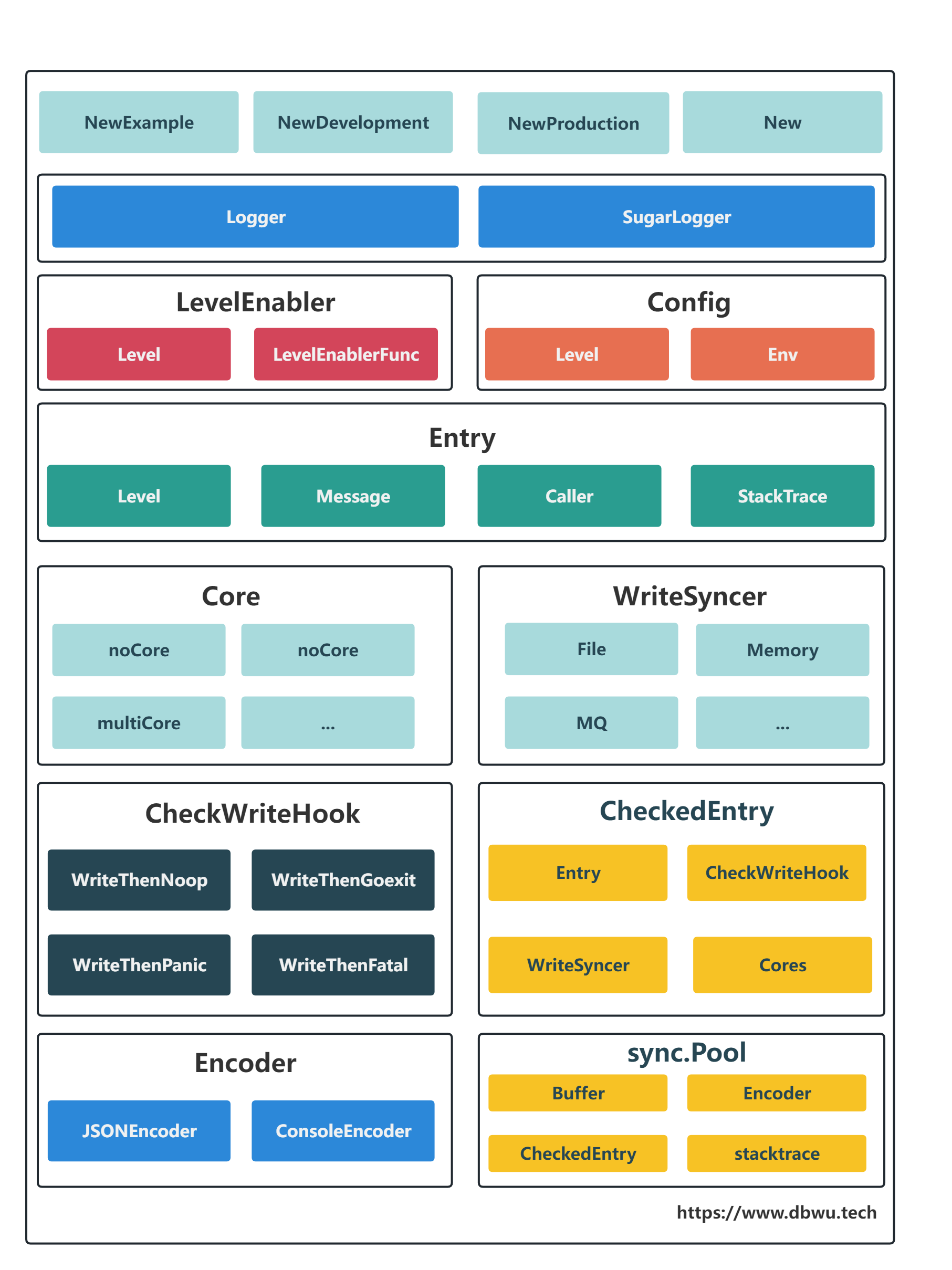
zap 高性能实现细节
- 通过内建的数据类型
zapcore.Field和内建的日志编码器 (Encoder接口),避免标准库的序列化方法使用反射带来的性能损耗 - 通过内建的数据类型
zapcore.Field, 避免使用interface{}带来的开销 (拆装箱、对象逃逸到堆上) - 通过内建的
[]byte缓冲池配合zapcore.Field进一步提升日志数据的写入性能 - 获取调用堆栈方法优化 (使用
runtime.Callers而非runtime.Stack) - 写时复制机制 (多个日志共享一个
Logger对象,在属性变更时复制一个新的对象,详情见Logger.clone方法及其调用方) - 按需分配机制 (
Check方法检查可写后,再通过CheckedEntry.Write方法写入日志数据,可以保证zapcore.Field日志对象内存按需分配) - 对象复用避免
GC(位于hot path上面的对象全部使用对象池管理模式进行复用) - 避免数据竞态,虽然有对象池管理复用,但是对象的获取都需要经过各种条件过滤,有效缓解了底层
sync.Pool内部的数据竞态问题 - 重复检测,每个日志保证只写入一次,提升性能并且避免应用层的错误使用导致的 Bug
小结
本文着重分析了 zap 日志库高性能背后的实现原理,其中大部分优化技术点细节都在 高性能 Tips 一文中提到过。
作为开发者最重要的是,有了基础的优化理论之后,可以像 Uber 的工程师一样,根据不同的业务场景开发出匹配的高性能组件。
从开发者的角度看,大多数高性能组件背后的技术本质除了代码优化之外,开发效率的降低往往同样是不可避免的代价 (这似乎又回到了静态语言和动态语言的感觉)。
BTW, Uber 这家公司为 Go 生态贡献了不少高质量的组件库,感兴趣的读者可以查看 Uber-Go Github 官方页面。
附录
zap 与标准库相互切换
如果项目之前使用的是标准库 log,现在想改为 zap, 那么不需要修改已有的代码,直接调用 zap.NewStdLog() 即可将标准库中 log 的输出格式和方式改为当前 zap 对象的配置,
调用方式保持不变,但是输出行为已经发生变化。
package main
import (
"go.uber.org/zap"
"log"
)
func main() {
logger, _ := zap.NewProduction()
defer logger.Sync()
// 标准库日志输出
log.Print("standard log")
// zap 替换了标准库日志的配置
undo := zap.RedirectStdLog(logger)
// 标准库再次输出时,内部其实是 zap 在输出
log.Print("standard log")
// 撤销 zap 的替换
undo()
// 标准库日志输出
log.Print("standard log")
}
$ go run main.go
# 输出如下
2023/04/05 15:16:49 standard log
{"level":"info","ts":1680765409.5444076,"caller":"go-high-performance/main.go:18","msg":"standard log"}
2023/04/05 15:16:49 standard log
全局 Logger
zap 提供了两个全局的 Logger,调用 zap.L() 返回 zap.Logger, 调用 zap.S() 返回 zap.SugaredLogger,
默认情况下,这两个全局的 Logger 不会记录日志,需要调用 zap.ReplaceGlobals() 方法进行设置。
package main
import (
"go.uber.org/zap"
)
func main() {
// 下面两行代码不会有任何输出
zap.L().Info("before global log settings")
zap.S().Infow("before global log settings")
logger := zap.NewExample()
logger.Sync()
// 设置全局日志
zap.ReplaceGlobals(logger)
// 下面两行代码正常输出
zap.L().Info("after global log settings")
zap.S().Infow("after global log settings")
}
为什么默认情况下全局日志没有输出呢?
因为调用 zap.L() 和 zap.S() 两个方法返回的是 nopCore 对象,顾名思义,该对象被调用时什么也不做,具体的代码如下:
var (
_globalMu sync.RWMutex
_globalL = NewNop()
)
func NewNop() *Logger {
return &Logger{
core: zapcore.NewNopCore(),
...
}
}
func NewNopCore() Core { return nopCore{} }
func (nopCore) Write(Entry, []Field) error { return nil }
func (nopCore) Sync() error { return nil }
日志切割
zap 组件库本身不支持轮转 (rotating) 日志文件,官方认为这不是 日志库 的核心功能,所以作为接口 (WriteSyncer) 留给了开发者自己实现。
例如,我们可以使用 lumberjack 组件库来完成日志的自动化切割备份等功能。
lumberjack 可以和任何实现了 io.Writer 接口的组件库配合使用,主要功能是日志文件相关操作。
package main
import (
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
"gopkg.in/natefinch/lumberjack.v2"
)
func main() {
ljLogger := &lumberjack.Logger{
Filename: "zap_test.log",
MaxSize: 1, // 单个文件最大 1 MB
MaxBackups: 3, // 多于 3 个日志文件,清理较旧的日志
Compress: true,
}
syncer := zapcore.AddSync(ljLogger)
encoder := zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
core := zapcore.NewCore(encoder, syncer, zapcore.DebugLevel)
logger := zap.New(core)
logger.Sync()
// {"level": ... ,"ts" ... ,"msg":"hello world"}
// 一行日志大约 60B,写入 100000 次,总大小为 6 MB+
for i := 0; i < 100000; i++ {
logger.Info("hello world")
}
}
$ go run main.go
# 输出如下
... 57K zap_test-2023-04-06T09-36-29.816.log.gz
... 57K zap_test-2023-04-06T09-36-29.870.log.gz
... 57K zap_test-2023-04-06T09-36-29.930.log.gz
... 812K zap_test.log
从输出的结果中可以看到: 虽然测试输出的日志数据总大小超过了 6MB,理论上应该是 7 个日志文件,但是历史的日志文件只保留了 3 个,其他的都被删除了,
并且这 3 个日志文件已经自动压缩为 .gz 格式,节省了很多空间,完全符合我们的配置项输出预期。
日志中的重复字段
zap 不会对日志数据中的字段自动去重,多个重复的字段会原样输出:
logger.Info("hello world", zap.String("name", "Tom"), zap.String("name", "Tom"))
$ go run main.go
# 输出如下, name 字段输出了两次
{"level":"info","ts":1680765409.2753036,"msg":"hello world","name":"Tom","name":"Tom"}
