HTTP Router 算法演进
2023-07-13 算法 Trie Tree Radix Tree Go 源码分析 读代码
概述
本文从开发中常见的应用场景 “路由管理” 为例,介绍三种常用的实现方案背后的数据结构和算法 (代码实现为 Go 语言)。
应用示例
下面是一个典型的 REST 风格的 API 列表:
| Method | URL |
|---|---|
| GET | /users/list |
| GET | /users/dbwu |
| POST | /users |
| PUT | /users/dbwu |
| DELETE | /users/dbwu |
上面的 API 翻译为 Go 代码,大致如下 (忽略方法的具体实现):
package main
import (
"log"
"net/http"
)
func main() {
http.HandleFunc("/users/list", nil)
http.HandleFunc("/users/dbwu", nil)
http.HandleFunc("/users", nil)
http.HandleFunc("/users/dbwu", nil)
http.HandleFunc("/users/dbwu", nil)
log.Fatal(http.ListenAndServe(":8080", nil))
}
标准库方案
最简单的方案就是直接使用 map[string]func() 作为路由的数据结构,键为具体的路由,值为具体的处理方法。
标准库中使用的就是这种方案,我们可以简单追踪一下对应的代码:
// 路由管理数据结构
type ServeMux struct {
mu sync.RWMutex // 对象操作读写锁
m map[string]muxEntry // 存储路由映射关系
}
方法从 http.HandleFunc 方法开始追踪:
// 注册路由处理方法
func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
DefaultServeMux.HandleFunc(pattern, handler)
}
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
mux.Handle(pattern, HandlerFunc(handler))
}
func (mux *ServeMux) Handle(pattern string, handler Handler) {
mux.mu.Lock()
defer mux.mu.Unlock()
...
if _, exist := mux.m[pattern]; exist {
// 如果注册的 URL 重复了,抛出 panic
panic("http: multiple registrations for " + pattern)
}
if mux.m == nil {
// 惰性初始化
mux.m = make(map[string]muxEntry)
}
// 注册完成
e := muxEntry{h: handler, pattern: pattern}
mux.m[pattern] = e
...
}
优点和不足
使用 map[string]func() 作为路由的数据结构,最明显的优点就是:
- 实现简单: map 是标准库内置的数据结构,可以直接使用并且代码可读性高
- 性能较高: 因为路由写入操作只会发生一次 (注册时),后续的操作全部是读取操作,基于标准库的 map 性能已经足够优秀
同时,该方案的不足也是显而易见的:
- 内存浪费: 即使存在很多前缀相同的路径 (例如 /users, /users/list, /users/dbwu, 三个路径的前缀都是 /users, 这部分是可以复用的),map 结构还是会每个路径单独映射,浪费大量的内存
- 不够灵活: 难以处理动态路由和正则表达式匹配等复杂的路径 (例如 /users/:id 或 /users/{id:[0-9]+})
- 无法处理重复路径:如果多个处理方法绑定到相同的路径上 (例如 GET /users 和 POST /users),map 只能存储一个键值对,也就是只有最后一个注册的处理函数会被调用
- 不支持中间件:map 结构不支持中间件,这在现代 Web 开发中几乎是不可接受的
基于以上特点,在真实的项目开发中不会使用 map[string]func() 作为路由的实现数据结构。
Trie Tree
Trie Tree 也称为字典树或前缀树,是一种用于高效存储和检索、用于从某个集合中查到某个特定 key 的数据结构。 这些 key 通常是字符串,节点之间的父子关系不是由整个 key 定义,而是由 key 中的单个字符定义。 对某个 key 对应的元素进行相关操作 (写入、更新、删除) 就是一次 DFS (深度优先遍历) 过程。
算法复杂度
- N: 字符串的数量
- M: 字符串的平均长度
- L: 字符串的长度
| 空间复杂度 |
|---|
| O(NM) |
| 操作 | 时间复杂度 |
|---|---|
| 插入 | O(L) |
| 查找 | O(L) |
| 删除 | O(L) |
Trie Tree 的核心思想是空间换时间,利用字符串的公共前缀来减少字符比较操作,提升查询效率。
图示
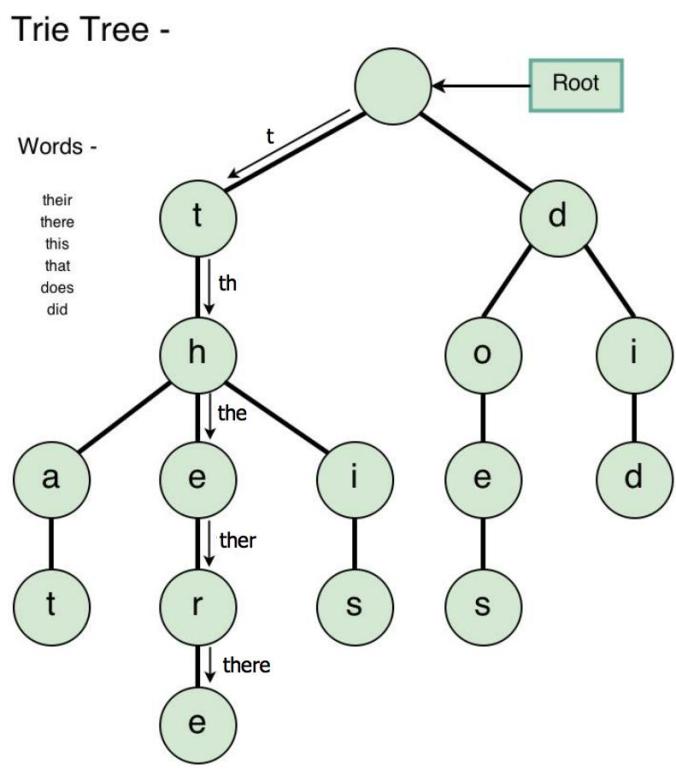
如图所示,是一个典型的 Trie Tree, 其中包含了如下元素:
"their", "there", "this", "that", "does", "did"
本文不再描述算法的具体操作过程了,读者可以通过代码来感受一下,如果希望抓住细节,可以阅读维基百科的介绍, 或者通过 这个可视化在线工具 来手动操作体验。
实现代码
首先写一个基础版的 Trie Tree 代码,对算法本身做一个初步认识。
package trie
// Trie Tree 节点
type Trie struct {
// 标记当前节点是否为有效的路由
// 例如添加了路由 /users
// 那么 /user, /usr 不能算作有效的路由
// 也就是只有字符 "s" 节点的 IsPath 字段为 true
IsPath bool
// 当前节点的子节点
Children map[byte]*Trie
}
func New() Trie {
return Trie{false, make(map[byte]*Trie)}
}
// Add 添加一个路由到 Trie Tree
func (t *Trie) Add(path string) {
parent := t
// 逐个 byte 加入到 Trie Tree
for i := range path {
if child, ok := parent.Children[path[i]]; ok {
// 如果子节点不为空,继续向下遍历
parent = child
} else {
// 如果子节点为空,构造新的节点
newChild := &Trie{false, make(map[byte]*Trie)}
parent.Children[path[i]] = newChild
parent = newChild
}
}
// 更新当前路由的叶子节点的 IsPath 字段
parent.IsPath = true
}
// Find 返回指定路由是否存在于 Trie Tree 中
func (t *Trie) Find(path string) bool {
parent := t
for i := range path {
if child, ok := parent.Children[path[i]]; ok {
parent = child
} else {
return false
}
}
return parent.IsPath
}
然后对上面的实现代码做一个简单的小测试:
package trie
import "testing"
func TestTrie(t *testing.T) {
trieTree := New()
if got := trieTree.Find("hello"); got != false {
t.Errorf("Get() = %v, want %v", got, false)
}
trieTree.Add("hello")
if got := trieTree.Find("hello"); got != true {
t.Errorf("Get() = %v, want %v", got, true)
}
if got := trieTree.Find("he"); got != false {
t.Errorf("Get() = %v, want %v", got, false)
}
trieTree.Add("he")
if got := trieTree.Find("he"); got != true {
t.Errorf("Get() = %v, want %v", got, true)
}
}
实现路由管理
现在,我们将刚才的 “算法部分” 代码配合标准库提供的 API 代码,完成一个基础版的路由管理功能。
package main
import (
"fmt"
"log"
"net/http"
)
// Router 节点
type Router struct {
Path string
Method string
// 标记当前节点是否为有效的路由
// 例如添加了路由 /users
// 那么 /user, /usr 不能算作有效的路由
// 也就是只有字符 "s" 节点的 IsPath 字段为 true
IsPath bool
// 当前节点的子节点
Children map[byte]*Router
// 路由处理方法
Handler http.HandlerFunc
}
func NewRouter() *Router {
return &Router{IsPath: false, Children: make(map[byte]*Router)}
}
// Add 添加一个路由到 Router
func (r *Router) Add(method, path string, handler http.HandlerFunc) {
parent := r
// 逐个 byte 加入到 Router Tree
for i := range path {
if child, ok := parent.Children[path[i]]; ok {
// 如果子节点不为空,继续向下遍历
parent = child
} else {
// 如果子节点为空,构造新的节点
newChild := NewRouter()
parent.Children[path[i]] = newChild
parent = newChild
}
}
parent.Method = method
parent.Handler = handler
// 更新当前路由的叶子节点的 IsPath 字段
parent.IsPath = true
}
// Find 返回指定路由是否存在于 Router 中
func (r *Router) Find(method, path string) (http.HandlerFunc, bool) {
parent := r
for i := range path {
if child, ok := parent.Children[path[i]]; ok {
parent = child
} else {
return nil, false
}
}
return parent.Handler, parent.IsPath && parent.Method == method
}
// 实现 http.Handler 接口
func (r *Router) ServeHTTP(w http.ResponseWriter, req *http.Request) {
handler, ok := r.Find(req.Method, req.URL.Path)
if ok {
handler(w, req)
} else {
http.NotFound(w, req)
}
}
// 处理所有路由的方法
// 输出请求 Method 和 URL
func allHandler(w http.ResponseWriter, req *http.Request) {
_, _ = fmt.Fprintln(w, req.Method, req.URL)
}
func main() {
r := NewRouter()
r.Add("GET", "/hello", allHandler)
r.Add("GET", "/users/list", allHandler)
log.Fatal(http.ListenAndServe(":8080", r))
}
为了节省篇幅,这里就不写测试代码了,下面进行几个简单的测试:
# 启动服务
$ go run main.go
# 测试两个正常的 URL
$ curl 127.0.0.1:8080/hello
# 输出如下
GET /hello
$ curl 127.0.0.1:8080/users/list
# 输出如下
GET /users/list
# 测试两个不存在的 URL
$ curl 127.0.0.1:8080
# 输出如下
404 page not found
$ curl 127.0.0.1:8080/users/123456
# 输出如下
404 page not found
优点
Trie Tree 时间复杂度低,和一般的树形数据结构相比,Trie Tree 拥有更快的前缀搜索和查询性能,和查询时间复杂度为 O(1) 常数的哈希算法相比, Trie Tree 支持前缀搜索,并且可以节省哈希函数的计算开销和避免哈希值碰撞的情况,最后,Trie Tree 还支持对关键字进行字典排序。
适用场景
- 排序 : 一组字符串 key 的字典排序,可以通过为给定 key 构建一个 Trie Tree, 然后通过前序方式遍历树来实现, burstsort 是 2007 年最快的字符串排序算法,其基础数据结构就是 Trie Tree
- 全文索引: 通过一种特殊的 Trie Tree 实现,一般称为后缀树,可用于索引文本中的所有后缀以执行快速全文搜索
- 搜索引擎: 当你在搜索引擎的输入框中输入关键字时,自动补全的提示信息
- 生物信息: 基因序列对比软件
- 路由管理: 网络 IP 路由表,Web 中的 HTTP Router 管理
不适用场景
- 字符串公共前缀太少,造成 Trie Tree 节点稀疏分布,这时哈希表是更好的选择
- 节点之间的父子节点使用指针连接,对 CPU 和自带 GC 语言不太友好
- 字符集过大会造成过多的存储空间占用 (Trie Tree 是空间换时间)
- 字符串过长会使 Trie Tree 深度变大,这时应该使用接下来讲到的 Radix Tree
Radix Tree
Radix Tree(基数树)是一种特殊的数据结构,用于高效地存储和搜索字符串键值对,它是一种基于前缀的树状结构,通过将相同前缀的键值对合并在一起来减少存储空间的使用。 Radix Tree 的关键思想是利用公共前缀来合并节点,每个节点代表一个字符,从根节点到叶子节点的路径即为一个字符串键,每个节点上存储着一个字符串的部分子串,并且每个节点可以代表多个键值对。
算法复杂度
- N: 字符串的数量
- M: 字符串的平均长度
- L: 字符串的长度
| 空间复杂度 |
|---|
| O(NM) |
注意: Radix Tree 的使用场景是树中有较多节点拥有相同前缀,所以即使和 Trie Tree 的空间复杂度一样,但是实际应用中,Radix Tree 通过压缩公共前缀, 空间使用要比 Trie Tree 节省很多。
| 操作 | 时间复杂度 |
|---|---|
| 插入 | O(L) |
| 查找 | O(L) |
| 删除 | O(L) |
操作示例
下面引用维基百科页面上的示例图来说明 Radix Tree 的操作过程。
初始状态下,树中包含两个节点,分别是字符串 test 和 slow。
1. 将字符串 water 插入到树中
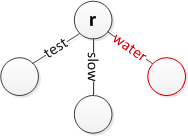
因为字符串 water 和已有的两个节点没有公共前缀,所以直接插入到新的节点中。
2. 将字符串 slower 插入到树中
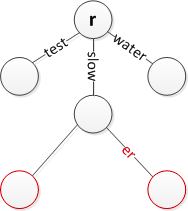
字符串 slower 和已有的节点 slow 存在公共前缀 slow, 所以放在 slow 节点下面。
3. 将字符串 tester 插入到树中
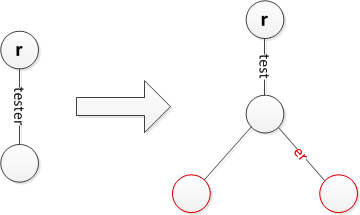
字符串 tester 和已有的节点 test 存在公共前缀 test, 所以放在 test 节点下面。
4. 将字符串 team 插入到树中
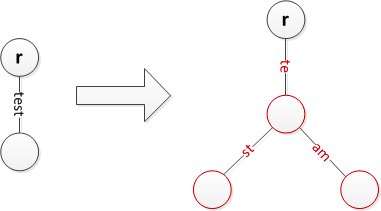
字符串 team 和已有的节点 test 存在公共前缀 te, 将 test 节点分裂为 st 和 am 两个子节点,两个子节点的父节点为 te。
5. 将字符串 toast 插入到树中
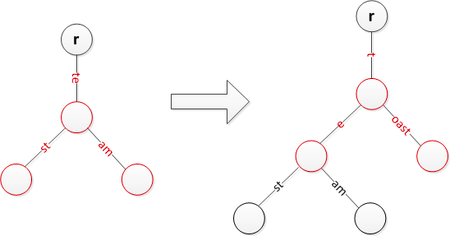
字符串 toast 和已有的节点 te 存在公共前缀 t, 将 te 节点分裂为 e 和 oast 两个子节点,两个子节点的父节点为 t, 将 te 原来的两个子节点放在 e 节点下面。
实现代码
笔者选择了开源的组件库 httprouter 来作为代码实现的学习方案,选择这个组件的主要原因有两点:
- 该组件专注于路由管理,代码量少且结构简单,涉及到 Radix Tree 数据结构和算法的代码已经独立到一个文件中,这可以大大降低我们阅读源代码的压力和时间成本
- 很多 Web 框架中的路由管理功能都是基于该组件实现的,比如非常流行的 Gin

httprouter 提供的 API 非常简洁,例如下面是一个简单的 Demo :
package main
import (
"net/http"
"log"
"github.com/julienschmidt/httprouter"
)
func main() {
router := httprouter.New()
router.GET("/", someHandle)
router.GET("/hello/:name", someHandle)
log.Fatal(http.ListenAndServe(":8080", router))
}
接下来我们分为两部分来学习 httprouter 组件的源代码实现:
- Radix Tree 数据结构和算法的实现
- 基于 Radix Tree 的路由管理功能实现
💡 重要提示: 下文中的代码和注释内容较多,读者如果时间有限,可以快速浏览一下核心对象及方法和文末的总结,在需要了解细节时再回来阅读。
Radix Tree 实现
工作原理简述
路由管理功能中,底层的数据结构是使用公共前缀的树形结构,也就是基数树。在该数据结构中,所有具有公共前缀的节点共享同一个父节点, 下面是一个关于这种数据结构的示例 (请求方法为 GET)。
Priority Path Handle
9 \ *<1>
3 ├s nil
2 |├earch\ *<2>
1 |└upport\ *<3>
2 ├blog\ *<4>
1 | └:post nil
1 | └\ *<5>
2 ├about-us\ *<6>
1 | └team\ *<7>
1 └contact\ *<8>
对上面的结构图做一个简单的说明:
- *<数字> 代表 Handler 方法指针
- search 节点和 support 节点拥有共同的父节点 s ,并且 s 没有对应的 Handle, 只有叶子节点才有 Handler
- 从 root 节点开始,一直到叶子节点,算作一条路由的完整路径
- 路径搜索的顺序是从上向下 -> 从左到右,为了快速找到尽可能多的路由,子节点越多的节点优先级越高
将上面的结构图转换代码:
router.GET("/", func1)
router.GET("/search/", func2)
router.GET("/support/", func3)
router.GET("/blog/:post/", func5)
router.GET("/about-us/", func6)
router.GET("/about-us/team/", func7)
router.GET("/contact/", func8)
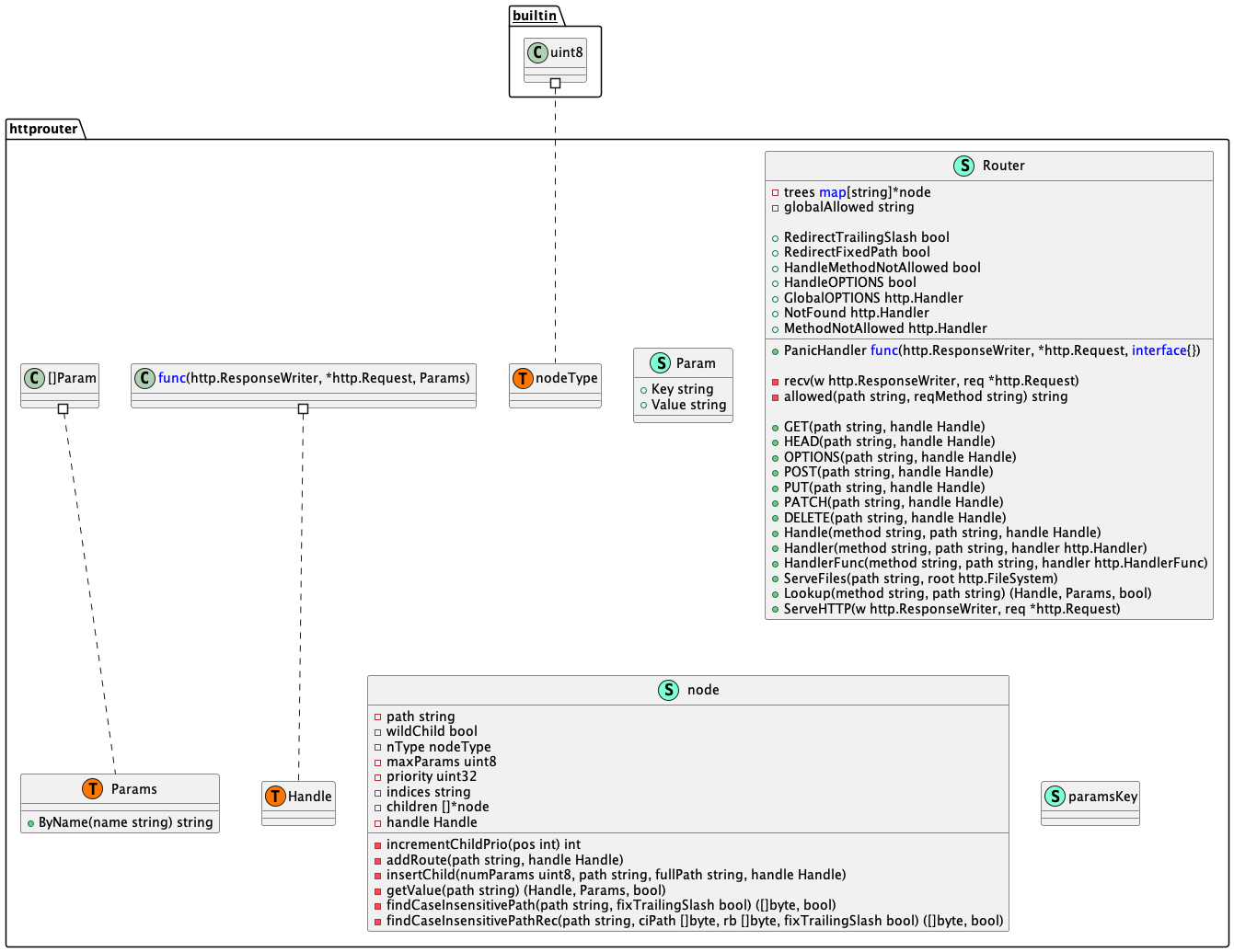
node 对象
node 对象表示 Radix Tree 的单个节点。
// 节点类型
type nodeType uint8
const (
static nodeType = iota
root // 根节点
param // 参数节点 (例如 /users/:id)
catchAll // 通用节点,匹配任意参数 (例如 /users/*logs)
)
type node struct {
path string // 路径
wildChild bool // 是否为参数节点
nType nodeType // 节点类型
maxParams uint8 // 路径参数个数上限
priority uint32 // 优先级
indices string // 导致当前节点和其子节点分裂的首个字符 (wildChild == true 时, indices == "")
children []*node // 子节点
handle Handle // 路由处理方法
}
添加路由
addRoute 方法将给定的路由处理方法绑定到具体的 Path 上面,该方法不是并发安全的,也就是需要通过加锁等机制将操作串行化。
为了最大化提升读者的阅读体验和效率,这里将代码剖析注解直接贴在源代码中。
func (n *node) addRoute(path string, handle Handle) {
fullPath := path
// 当前节点优先级 + 1
n.priority++
// 计算路径中的参数个数
numParams := countParams(path)
// non-empty tree
if len(n.path) > 0 || len(n.children) > 0 {
// 说明当前 Radix Tree 已经存在节点了
// 接下来进入 walk 循环标签
walk:
for {
// 更新当前节点最大参数个数
if numParams > n.maxParams {
n.maxParams = numParams
}
// 查找当前节点路径和参数路径的最长公共前缀
// 公共前缀中不能包含 ':' '*' 通配符 (因为这样就无法区分具体的路径了)
// PS: 查找最长公共前缀应该独立为一个函数,提高代码可读性,编译器会自动内联优化
// Gin 框架中已经独立为一个函数 longestCommonPrefix
// https://github.com/gin-gonic/gin/blob/d4a64265f21993368c90602c18e778bf04ef36db/tree.go#L75C6-L75C6
i := 0
max := min(len(path), len(n.path))
for i < max && path[i] == n.path[i] {
i++
}
// 如果最长公共前缀长度小于当前节点路径长度
// 这意味着可能是下列两种情况之一 :
// 1. 最长公共前缀 > 0, 例如当前节点路径为 /users, 参数路径为 /usr
// 2. 最长公共前缀 == 0, 例如当前节点路径为 /users, 参数路径为 /books
// 此时当前节点就需要分裂成两个节点
if i < len(n.path) {
// 将当前节点路径中非 “公共前缀” 部分独立到一个新的子节点中
child := node{
// 路径为当前节点路径中非 “公共前缀” 部分
path: n.path[i:],
// 类型待定, 没有 handler
nType: static,
indices: n.indices,
children: n.children,
handle: n.handle,
// 优先级 - 1
priority: n.priority - 1,
}
// 遍历新的子节点的所有子节点 (也就是当前节点的所有子节点)
// 更新当前节点最大参数个数
for i := range child.children {
if child.children[i].maxParams > child.maxParams {
child.maxParams = child.children[i].maxParams
}
}
// 将新节点作为当前节点的子节点 (当前节点之前的子节点已经被挂载到了新节点的子节点上面)
n.children = []*node{&child}
// 获取导致当前节点和其子节点分裂的首个字符,并更新 indices 字段
// (例如 /users/dbwu 和 /users/dbwt, 更新 indices 字段为 "u")
n.indices = string([]byte{n.path[i]})
// 更新当前节点的路径为公共前缀
n.path = path[:i]
// 删除当前节点的路由处理方法
n.handle = nil
// 删除当前节点的参数节点标志
n.wildChild = false
}
// 如果最长公共前缀长度小于参数路径长度
// 为什么这样判断呢?
// 因为如果最长公共前缀长度大于等于参数路径长度
// 说明参数路径本身就是公共前缀的一部分,就没必要插入这个新节点了
// 将新节点插入到当前节点的子节点
if i < len(path) {
// 删除公共前缀部分,剩余部分的 path 是子节点的路径
path = path[i:]
// 如果当前节点是参数节点 (例如 /users/:id)
if n.wildChild {
// 代码执行到这里说明: 最长公共前缀长度大于等于当前节点路径长度
// 也就是说: 参数路径的长度要大于当前节点路径长度
// (例如 当前节点路径为 /users/:id, 参数路径为 /users/:id/profile)
// 获取到当前节点的第一个子节点
n = n.children[0]
// 当前节点要插入一个新节点,优先级 + 1
n.priority++
// 更新当前节点最大参数个数
if numParams > n.maxParams {
n.maxParams = numParams
}
numParams--
// 检测通配符模式是否匹配
if len(path) >= len(n.path) && n.path == path[:len(n.path)] &&
n.nType != catchAll &&
// 检测更长的通配符匹配
// (例如当前节点的 path = name, 子节点的路径是 path = names)
(len(n.path) >= len(path) || path[len(n.path)] == '/') {
// 如果通配符模式匹配,进入下一次循环
continue walk
} else {
// 通配符发生了冲突
// (例如当前节点的 path = /users/:id/profile, 子节点的路径是 path = /users/:name/profile)
var pathSeg string
// 如果当前节点类型是通用节点 (通配符类型)
if n.nType == catchAll {
pathSeg = path
} else {
// 如果当前节点类型不是通用节点
// 将 path 字符串进行分割
// (例如 path = /users/:id/profile, 分割之后 pathSeg = profile)
pathSeg = strings.SplitN(path, "/", 2)[0]
}
// 提取出参数 path 的前缀
// (例如 fullPath = /users/:id/profile, 当前节点 path = :id, prefix = /user/:id)
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path
// 直接抛出一个 panic
// 信息中会输出产生冲突的具体通配符 path
panic("'" + pathSeg +
"' in new path '" + fullPath +
"' conflicts with existing wildcard '" + n.path +
"' in existing prefix '" + prefix +
"'")
}
}
c := path[0]
// 如果当前节点是一个参数节点并且只有一个子节点 并且参数 path 是以 "/" 开头的
// (例如当前节点 path = /:name/profile, 参数 path = /:name/setting)
if n.nType == param && c == '/' && len(n.children) == 1 {
// 将当前节点修改为其第一个子节点
n = n.children[0]
// 优先级 + 1
n.priority++
// 进入下一次循环
continue walk
}
// 检测新增子节点的 path 的首字母是否存在于当前节点的 indices 字段中
for i := 0; i < len(n.indices); i++ {
if c == n.indices[i] {
// 更新子节点的优先级
i = n.incrementChildPrio(i)
// 更新当前节点为对应的子节点
// (
// 例如当前节点 path = p, 包含两个子节点 rofile, assword)
// 此时 indices 字段就包含字符 r 和 a, 正好和两个子节点相对应
// 新增子节点的 path = projects, 删除和当前节点的公共前缀符 p 后,变成了 rojects
// 然后当前节点会被更新为 rofile 子节点
// 最后,跳转到下一次循环,然后拿 rofile 和 rojects 进行对比
// )
n = n.children[i]
// 进入下一次循环
continue walk
}
}
// 如果上面的条件都不满足
// 直接将新的子节点插入
if c != ':' && c != '*' {
// 如果参数 path 的第一个字符不是通配符
// 将第一个字符追加到当前节点的 indices 字段
n.indices += string([]byte{c})
// 初始化一个新的子节点
child := &node{
maxParams: numParams,
}
// 将新的子节点追加到当前节点的子节点列表中
n.children = append(n.children, child)
// 更新子节点的优先级
n.incrementChildPrio(len(n.indices) - 1)
// 更新当前节点为新增的子节点
n = child
}
n.insertChild(numParams, path, fullPath, handle)
return
} else if i == len(path) {
// 如果公共前缀和参数 path 长度相同
// 说明参数 path 本身就是当前节点 path 的一部分
if n.handle != nil {
// 如果当前节点已经注册了路由处理方法
// 那么再次注册时等于重复注册
// 直接抛出 panic
panic("a handle is already registered for path '" + fullPath + "'")
}
// 如果当前节点没有注册路由处理方法
// 说明当前节点是作为其子节点的公共前缀符而存在的
// (例如 当前节点 path = p, 包含两个子节点 rofile, assword))
n.handle = handle
}
return
}
} else {
// 如果当前节点是一个空节点
// 说明当前 Radix Tree 没有任何节点
// 直接插入一个新节点
// 并且将插入的新节点类型标记为 root
// PS: 笔者认为这两行边界检测代码应该放在函数开头部分,提高可读性
n.insertChild(numParams, path, fullPath, handle)
n.nType = root
}
}
incrementChildPrio 方法用于更新给定子节点的优先级,并在必要的时候进行排序。
func (n *node) incrementChildPrio(pos int) int {
// 将对应索引的子节点的优先级 + 1
n.children[pos].priority++
prio := n.children[pos].priority
// 向前移动位置
// (例如原本的子节点顺序为 [a, b, c, d], 此时传入参数 2, 移动之后的子节点顺序为 [c, a, b, d])
newPos := pos
for newPos > 0 && n.children[newPos-1].priority < prio {
n.children[newPos-1], n.children[newPos] = n.children[newPos], n.children[newPos-1]
newPos--
}
// 更新当前节点的 indices 字段信息
// (例如原本的 indices 字段为 abcd, 此时传入参数 2, 移动之后的 indices 字段为 cabd
if newPos != pos {
n.indices = n.indices[:newPos] + // unchanged prefix, might be empty
n.indices[pos:pos+1] + // the index char we move
n.indices[newPos:pos] + n.indices[pos+1:] // rest without char at 'pos'
}
// 返回移动后的新的位置
return newPos
}
insertChild 方法负责执行将具体的 path 插入到节点中。
func (n *node) insertChild(numParams uint8, path, fullPath string, handle Handle) {
// 参数 path 已经处理完的计算数量
var offset int
// 查找前缀直到第一个参数匹配或者通配符 (以 ':' 或 '*' 开头)
// 参数匹配 (类似这种形式 :name)
// 通配符 (类似这种形式 *logs)
// 为了便于描述,下文中统一将 参数匹配符号 和 通配符号 统称为 Token
for i, max := 0, len(path); numParams > 0; i++ {
c := path[i]
if c != ':' && c != '*' {
// 如果不是 ':' 或 '*', 直接跳过
continue
}
// 查找当前 Token 结束符, 也就是下一个 '/'
// (例如 Token 为 /:name/profile, 查找的就是 :name 后面的 / 符号)
end := i + 1
for end < max && path[end] != '/' {
switch path[end] {
// 如果 Token 中嵌套 Token,直接 panic
// (例如 /:name:id)
case ':', '*':
panic("only one wildcard per path segment is allowed, has: '" +
path[i:] + "' in path '" + fullPath + "'")
default:
end++
}
}
// 如果 Token 所在的索引位置已经有节点了,直接 panic
// (例如已经存在了节点 path = /users/dbwu, 就不能再定义 path = /user/:name)
if len(n.children) > 0 {
panic("wildcard route '" + path[i:end] +
"' conflicts with existing children in path '" + fullPath + "'")
}
// Token 至少需要一个字符表示的参数名称, 否则直接 panic
// (例如 :name, :id 中的 name 和 id 就是 Token 的参数名称)
if end-i < 2 {
panic("wildcards must be named with a non-empty name in path '" + fullPath + "'")
}
// 如果 Token 的类型是参数匹配符
if c == ':' {
// 将当前节点的位置更新为 从 offset 到当前索引位置之间的 path,
if i > 0 {
n.path = path[offset:i]
// 更新 offset
offset = i
}
// 根据参数初始化一个新的子节点
child := &node{
nType: param,
maxParams: numParams,
}
// 更新当前节点的子节点
n.children = []*node{child}
// 更新当前节点类型为参数节点
n.wildChild = true
// 当前节点下降为子节点,继续后面的路由处理
n = child
// 当前节点优先级 + 1
n.priority++
// 最大参数个数 - 1
numParams--
// 如果 Token 结束符比参数 path 长度要小
// 说明参数 path 中还有子路径
if end < max {
// 更新当前节点 path
n.path = path[offset:end]
// 更新 offset
offset = end
// 初始化一个新节点作为参数 path 中的子路径节点
child := &node{
maxParams: numParams,
priority: 1,
}
// 更新当前节点的子节点
n.children = []*node{child}
// 当前节点下降为子节点,继续后面的路由处理
n = child
}
} else { // 如果 Token 的类型是通配符
if end != max || numParams > 1 {
// 通配符类型的路径必须位于路由 path 的最后一部分,否则直接 panic
// (
// 例如 /users/*name 是合法的,但是 /users/*name/profile 不是合法的,因为这样就无法区分其他路由了
// 例如 path = /users/dbwu/profile 是一个单独的 path, 但是却匹配了 /users/*name 这个 path
// 因此获取到的参数 name = "dbwu/profile"
// 所以不会再将后面的 /dbwu/profile 作为单独路径来处理了
// )
panic("catch-all routes are only allowed at the end of the path in path '" + fullPath + "'")
}
if len(n.path) > 0 && n.path[len(n.path)-1] == '/' {
// 新定义的通配符和已有的通配符冲突了,直接 panic
// (例如一个已有的 path = /users/dbwu, 新定义的 path = /users/:name, 如果不终止,后者就会覆盖前者)
panic("catch-all conflicts with existing handle for the path segment root in path '" + fullPath + "'")
}
i--
if path[i] != '/' {
// 如果通配符前面没有 '/', 直接 panic
panic("no / before catch-all in path '" + fullPath + "'")
}
n.path = path[offset:i]
// 初始化一个新的子节点,类型为通配符节点
child := &node{
wildChild: true,
nType: catchAll,
maxParams: 1,
}
// 更新当前节点的最大参数个数
if n.maxParams < 1 {
n.maxParams = 1
}
// 更新当前节点的子节点
n.children = []*node{child}
// 更新当前节点的 indices 字段
n.indices = string(path[i])
// 当前节点下降为子节点,继续后面的路由处理
n = child
// 当前节点优先级 + 1
n.priority++
// 初始化一个新节点作为参数 path 中的剩余部分的节点
child = &node{
path: path[i:],
nType: catchAll,
maxParams: 1,
handle: handle, // 绑定路由的处理函数
priority: 1,
}
// 更新当前节点的子节点
n.children = []*node{child}
// 通配符类型的路径必须位于路由 path 的最后一部分
// 直接返回即可
return
}
}
// 更新当前节点的 path
n.path = path[offset:]
// 更新当前节点的处理函数
n.handle = handle
}
查找路由处理方法
getValue 方法根据指定的 path,查找并返回对应的路由处理方法。
返回值列表顺序如下:
- handle : path 对应的处理方法,如果没有找到,返回 nil
- p : 如果 path 对应的节点类型是参数节点,会将参数返回
- tsr : 路由是否可以被重定向
func (n *node) getValue(path string) (handle Handle, p Params, tsr bool) {
// 循环标签
walk:
for {
// 如果要查找的 path 长度大于当前节点的 path 长度
// 除了根路径 /, 其他 path 应该都可以满足这个条件
if len(path) > len(n.path) {
// 如果当前节点的 path 是要查找的 path 的前缀
if path[:len(n.path)] == n.path {
// 那么就将前缀去掉,查找剩余的部分
path = path[len(n.path):]
// 如果当前节点类型不是参数节点
// 直接在其子节点中查找即可
if !n.wildChild {
// 通过要查找 path 的首字母快速匹配对应的子节点
c := path[0]
for i := 0; i < len(n.indices); i++ {
if c == n.indices[i] {
// 更新当前节点
n = n.children[i]
// 跳转到下一个循环
continue walk
}
}
// 代码执行到这里,说明没有匹配到子节点
// 如果路径剩余的部分正好是 '/', 并且当前节点注册了路由处理方法
// 更新 tsr 重定向标记为 true
// (例如查找的 path = /users/, 当前节点 path = /users, 那么就重定向到 /users)
tsr = (path == "/" && n.handle != nil)
return
}
// 如果当前节点类型是参数节点或者通配符节点
// 那么当前节点只会有一个子节点
// 更新当前节点为其第一个子节点
n = n.children[0]
switch n.nType {
// 如果当前节点类型是参数节点
// 参数匹配 (类似这种形式 :name)
case param:
// 查找路径中的参数结束符或者 '/'
end := 0
for end < len(path) && path[end] != '/' {
end++
}
if p == nil {
// 惰性初始化参数返回值
// 注意初始化的时候已经指定了切片容量
p = make(Params, 0, n.maxParams)
}
// 为参数返回值赋值
i := len(p)
p = p[:i+1]
p[i].Key = n.path[1:]
p[i].Value = path[:end]
// 如果路径还没有匹配完,
if end < len(path) {
// 如果子节点下面还存在子节点
// (例如 path = /users/:name/:setting, 当前匹配到 :name, 发现其还有子节点)
if len(n.children) > 0 {
// 更新查找路径
path = path[end:]
// 更新当前节点为其第一个子节点
n = n.children[0]
// 跳转到下一个循环
continue walk
}
// 没有查到到对应到路由处理函数
// 直接返回
tsr = (len(path) == end+1)
return
}
if handle = n.handle; handle != nil {
// 如果当前节点有对应到路由处理函数
// 直接返回
return
} else if len(n.children) == 1 {
// 如果当前节点没有对应到路由处理函数
// 确认其子节点是否为 '/' 并且子节点有对应到路由处理函数
// 这样就可以进行进行重定向了
n = n.children[0]
tsr = (n.path == "/" && n.handle != nil)
}
return
// 如果当前节点类型是通配符节点
// 通配符 (类似这种形式 *logs)
case catchAll:
if p == nil {
// 惰性初始化参数返回值
// 注意初始化的时候已经指定了切片容量
p = make(Params, 0, n.maxParams)
}
// 通配符不会有子节点,直接赋值后返回即可
// 为参数返回值赋值
i := len(p)
p = p[:i+1]
p[i].Key = n.path[2:]
p[i].Value = path
handle = n.handle
return
default:
// 代码执行到这里
// 说明当前节点的类型不在枚举范围内,直接 panic
panic("invalid node type")
}
}
} else if path == n.path {
// 如果要查找的 path 等于当前节点的 path
// 检测当前节点是否有路由处理函数,如果有的话,直接返回即可
if handle = n.handle; handle != nil {
return
}
// 如果要查找的 path 等于 / 并且当前节点类型不是 root, 并且当前节点是参数节点
// 允许重定向
if path == "/" && n.wildChild && n.nType != root {
tsr = true
return
}
// 当前节点没有路由处理函数,但是有一个子节点的路径为 '/', 这时允许重定向
// (例如当前节点的 path = /users/, 但是查找的 path = /users, 此时就允许重定向到 /users/ 上面)
for i := 0; i < len(n.indices); i++ {
if n.indices[i] == '/' {
n = n.children[i]
tsr = (len(n.path) == 1 && n.handle != nil) ||
(n.nType == catchAll && n.children[0].handle != nil)
return
}
}
return
}
// 没有查到到对应到路由处理函数
// 根据条件更新是否允许重定向字段
tsr = (path == "/") ||
(len(n.path) == len(path)+1 && n.path[len(path)] == '/' &&
path == n.path[:len(n.path)-1] && n.handle != nil)
return
}
}
路由管理实现
相比于上面 Radix Tree 的实现,路由管理功能实现要简单的多,这里分析一下核心的代码。
Router 对象
Router 对象表示全局的路由管理对象,可以将不同的 HTTP Method + Path 请求分发给不同的路由处理函数。
type Router struct {
// 路由管理的核心字段,每个 HTTP Method 对应一个 Radix Tree 结构
// 例如
// GET => Radix Tree
// POST => Radix Tree
// DELETE => Radix Tree
// ...
trees map[string]*node
// 是否启用请求的自动重定向
// (例如当前请求为 /foo/, 但是路由管理注册的路径只有 /foo, 此时就将 /foo/ 重定向到 /fooo)
// (重定向时,GET 请求的响应码为 301, 其他请求的为 307)
RedirectTrailingSlash bool
// 是否启用自动修复路径
// 首先会删除路径中多余的部分,例如 ../ 和 //
// 然后再次查找路径 (这一次不区分大小写),看是否可以匹配到对应的路径处理方法
// 如果能匹配到路径,就进行重定向
// (重定向时,GET 请求的响应码为 301, 其他请求的为 307)
RedirectFixedPath bool
// 是否启用 Method Not Allowed
// 启用机制后,如果当前路径没有匹配到对应的路径处理方法
// 查看其他当前路径是否注册了其他 HTTP 请求类型的路径处理方法
// 如果注册了,返回 405 状态码
// 如果没有开启机制,当前路径没有匹配到对应的路径处理方法
// 返回 404 状态码
HandleMethodNotAllowed bool
// 是否启用 OPTIONS 请求响应
HandleOPTIONS bool
// 404 响应方法
// 如果没有设置,就使用标准库的 404 方法
NotFound http.Handler
// 405 响应方法
// 如果没有设置,就使用标准库的 Error 方法
// 其中响应文本为 Method Not Allowed,状态码为 405
MethodNotAllowed http.Handler
// 用于捕获并处理 panic 错误的方法,返回错误码 500 (Internal Server Error)
// 保证程序因为没有捕获 panic 而崩溃退出
PanicHandler func(http.ResponseWriter, *http.Request, interface{})
}
// 通过编译期间保证 Router 必须实现 http.Handler 接口
var _ http.Handler = New()
// 创建并返回一个路由管理实例
func New() *Router {
return &Router{
RedirectTrailingSlash: true,
RedirectFixedPath: true,
HandleMethodNotAllowed: true,
HandleOPTIONS: true,
}
}
注册路由处理方法
Router 提供了常见的 HTTP 请求路由处理方法注册的 API, 每个方法的内部都是调用了 Handle 方法,下面是 GET 方法和 POST 方法的实现代码。
// 注册 GET 请求处理方法
func (r *Router) GET(path string, handle Handle) {
r.Handle(http.MethodGet, path, handle)
}
// 注册 POST 请求处理方法
func (r *Router) POST(path string, handle Handle) {
r.Handle(http.MethodPost, path, handle)
}
...
Handle 方法将指定的 HTTP Method + Path 和路由处理方法进行绑定。
func (r *Router) Handle(method, path string, handle Handle) {
if len(path) < 1 || path[0] != '/' {
// 如果路径为空或者路径第一个字符不等于 '/'
// 这种路径格式就是不合法的,直接 panic
panic("path must begin with '/' in path '" + path + "'")
}
if r.trees == nil {
// 初始化 trees 字段
r.trees = make(map[string]*node)
}
root := r.trees[method]
if root == nil {
// 初始化参数 HTTP 方法对应的 Radix Tree 结构
root = new(node)
r.trees[method] = root
r.globalAllowed = r.allowed("*", "")
}
// 添加路由的注册方法
// 详情见前文对于 addRoute 方法的注解
root.addRoute(path, handle)
}
ServeHTTP 实现
ServeHTTP 方法负责处理 HTTP 请求并返回响应,同时实现了标准库中的 http.Handler 接口。
// net/http/server.go
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
func (r *Router) ServeHTTP(w http.ResponseWriter, req *http.Request) {
if r.PanicHandler != nil {
// 将 panic 错误处理函数注册到 defer 函数
defer r.recv(w, req)
}
// 获取当前请求路径
path := req.URL.Path
// 检测当前请求方法是否存在对应的 Radix Tree 结构
if root := r.trees[req.Method]; root != nil {
if handle, ps, tsr := root.getValue(path); handle != nil {
// 如果当前请求路径有对应的处理方法,直接调用即可
handle(w, req, ps)
return
} else if req.Method != http.MethodConnect && path != "/" {
// PS: 上面的 if 条件分支都已经直接返回了
// 这里实在没必要再写一个 else 条件分支
// 整个库的代码,可读性比较低 ~
// 如果当前请求路径没有对应的处理方法
// 将响应状态码设置为 301 (永久重定向,针对 GET 方法)
code := 301
if req.Method != http.MethodGet {
// 如果当前请求不是 GET 方法
// 将响应状态码设置为 307 (临死重定向,针对非 GET 方法)
// 为什么不使用 301 呢?
// 因为 308 和 307 不允许请求从 POST 修改为 GET
// Temporary redirect, request with same method
// As of Go 1.3, Go does not support status code 308.
code = 307
}
// 如果请求路径需要重定向并且路由支持重定向
if tsr && r.RedirectTrailingSlash {
// 如果路径的长度大于 1 并且路径是以 '/' 字符结尾的
// 就将末尾的 '/' 字符删除
if len(path) > 1 && path[len(path)-1] == '/' {
req.URL.Path = path[:len(path)-1]
} else {
// 在路径的结尾加一个 '/' 字符
req.URL.Path = path + "/"
}
// 返回重定向响应
http.Redirect(w, req, req.URL.String(), code)
return
}
// 如果当前请求路径没有对应的处理方法 并且 也没有符合规则的重定向条件
// 尝试修复请求路径
if r.RedirectFixedPath {
// 去除路径中的多余部分并返回经过修正后是否有匹配的路径
fixedPath, found := root.findCaseInsensitivePath(
CleanPath(path),
r.RedirectTrailingSlash,
)
if found {
// 如果经过修正,可以找到匹配的路径
// 直接重定向
req.URL.Path = string(fixedPath)
http.Redirect(w, req, req.URL.String(), code)
return
}
}
}
}
// 代码执行到了这里
// 说明上面的几个条件都不符合,当前请求路径还是没有找到对应的处理方法
if req.Method == http.MethodOptions && r.HandleOPTIONS {
// 如果请求方法是 OPTIONS, 并且路由管理允许响应 OPTIONS
// 返回一个 OPTIONS 响应
if allow := r.allowed(path, http.MethodOptions); allow != "" {
w.Header().Set("Allow", allow)
if r.GlobalOPTIONS != nil {
r.GlobalOPTIONS.ServeHTTP(w, req)
}
return
}
} else if r.HandleMethodNotAllowed {
// 如果请求方法不是 OPTIONS, 或者路由管理不允许响应 OPTIONS
// 返回一个 405 响应
if allow := r.allowed(path, req.Method); allow != "" {
w.Header().Set("Allow", allow)
if r.MethodNotAllowed != nil {
r.MethodNotAllowed.ServeHTTP(w, req)
} else {
http.Error(w,
http.StatusText(http.StatusMethodNotAllowed),
http.StatusMethodNotAllowed,
)
}
return
}
}
if r.NotFound != nil {
// 如果路由管理中注册了 404 处理函数
// 直接调用
r.NotFound.ServeHTTP(w, req)
} else {
// 如果路由管理中没有注册 404 处理方法
// 调用标准库中的 404 处理方法
http.NotFound(w, req)
}
}
优点
Radix Tree 通过合并公共前缀来降低存储空间的开销,避免了 Trie Tree 字符串过长和字符集过大时导致的存储空间过多问题,同时公共前缀优化了路径层数,提升了插入、查询、删除等操作效率。
使用 Radix Tree 可以减少树的层高,同时每个节点上的数据存储通常比 Trie Tree 多,所以程序的 CPU 缓存局部性较好 (一个节点的 path 加载到 CPU 缓存就可以进行多个字符的操作)。
适用场景
- 字典和前缀匹配 :适合用作字典或关联数组的底层数据结构,可以快速找到以给定前缀开头的所有键,例如 Redis 中的某个前缀 key
- IP 路由表 :可以高效地存储和搜索 IP 地址及其对应的路由表信息
- 文件系统和目录 :每个节点可以表示一个目录或文件,节点之间的关系通过共同的路径前缀进行连接
- 编译器 :可以用于编译器中的符号表管理,符号表存储了程序中定义的变量、函数名和类型等信息,Radix Tree 可以快速查找和更新符号表项,支持高效的名称解析和类型检查
不适用场景
- 字符串公共前缀太少,造成 Radix Tree 节点稀疏分布 (退化到 Trie Tree),这时哈希表是更好的选择 (这个问题在 Trie Tree 中同样存在)
- 字符集过小,可以直接使用其他简单的数据结构
- 动态数据集,也就是数据集需要频繁地进行插入和删除操作,由于 Radix Tree 的节点需要合并和路径重组,动态修改树结构可能引起较大的开销,在这种情况下,这时平衡二叉搜索树结构(AVL树、红黑树)更适合
- 节点之间的父子节点使用指针连接,对 CPU 和自带 GC 语言不太友好 (这个问题在 Trie Tree 中同样存在)
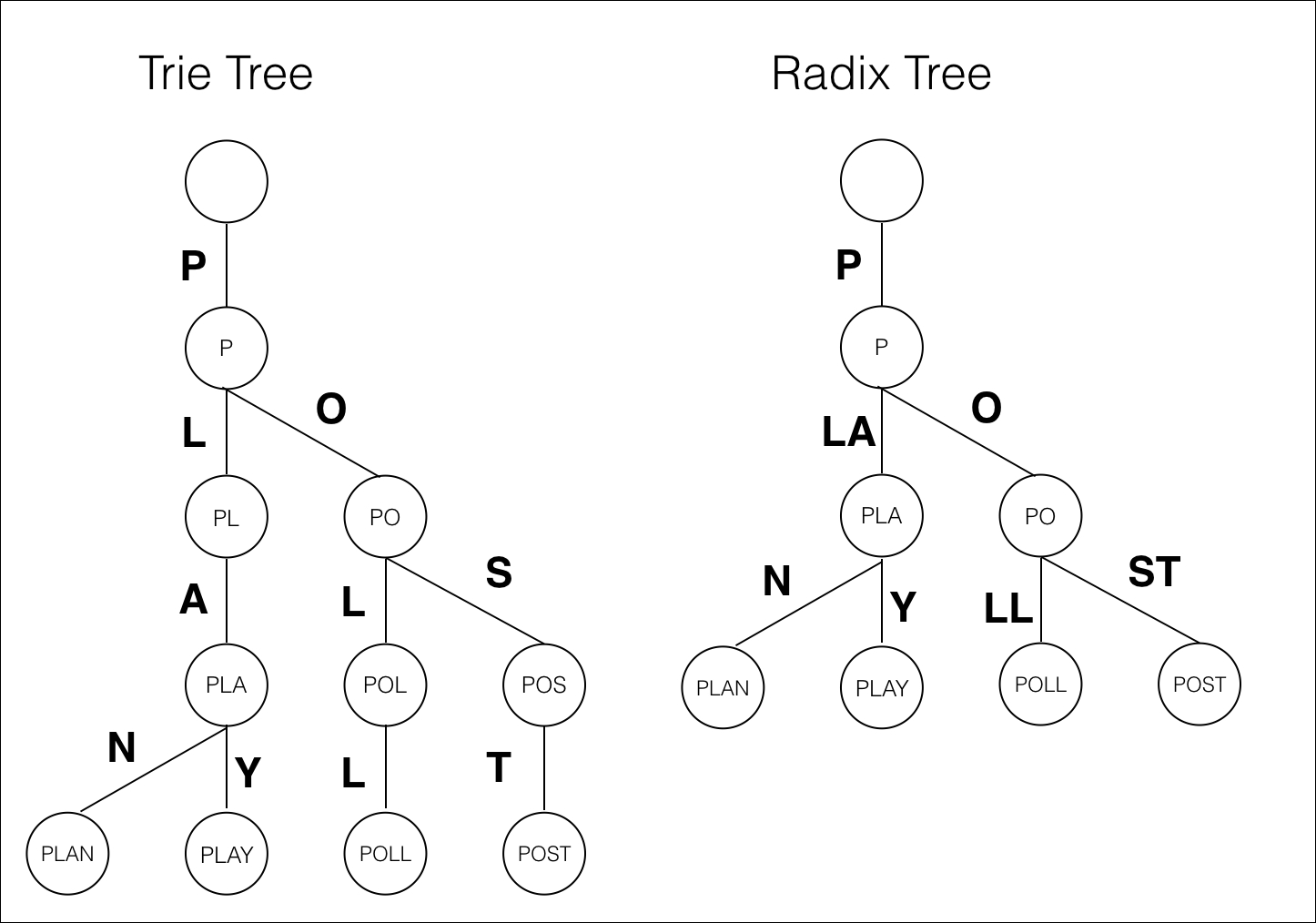
Trie Tree 和 Radix Tree 对比
下面是插入 4 个单词 [PLAN, PLAY, POLL, POST] 后的结果 (粗体字符表示节点字符,圆圈内字符串表示该节点表示的值)。
小结
本文从开发中常见的 “路由管理” 功能为出发点,探索了实现背后用到的数据结构和算法,并先后分析了各解决方案的优化过程,分别是 Go 标准库、手动实现 Trie Tree、开源的 Radix Tree, 希望读者在读完文章后,能准确地理解 Trie Tree 和 Radix Tree 的差异及其适用场景,如果在此基础上还有兴趣和时间,可以深入了解下由这两种数据结构演变出的其他数据结构和算法。
