Kubernetes 架构 - 控制平面和数据平面
2023-10-12 Cloud Native Kubernetes
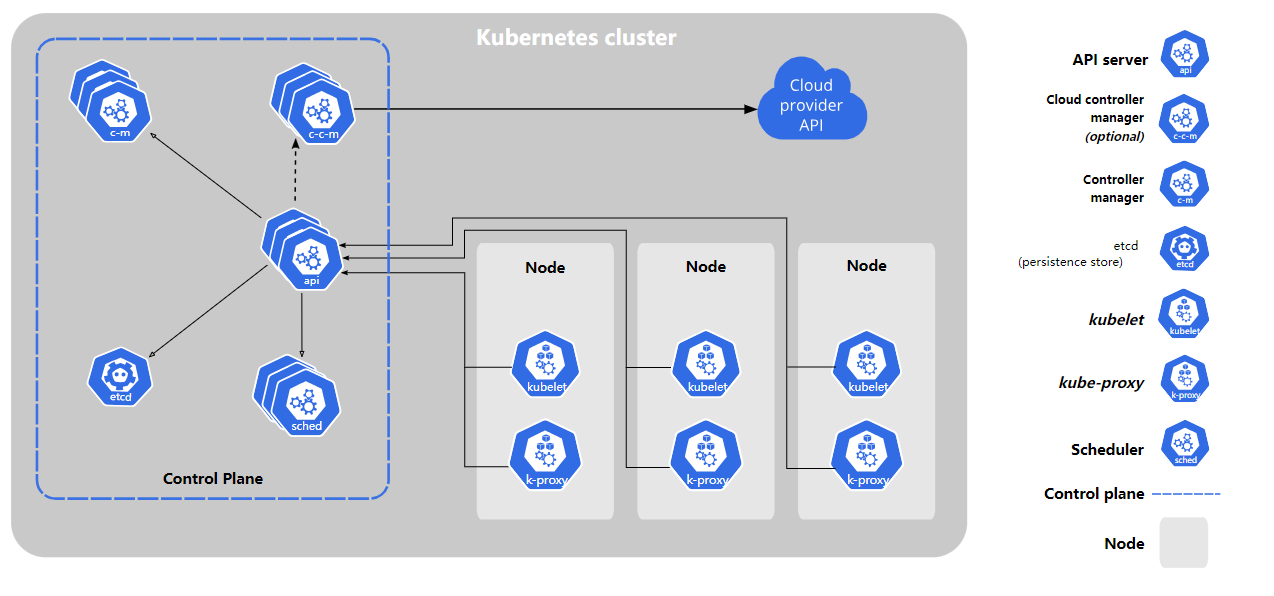
集群组成
Kubernetes 集群分为两部分
- Master Node (主节点,也就是控制平面)
- Worker Node (工作节点)
控制平面的组件
- API Server: 控制平面的前端,负责各组件之间的通信,接收和处理所有 REST 请求,并将处理结果状态存储到 etcd 中
- Scheduler: 负责将应用调度到具体节点,调度时会考虑软硬件约束、标签、亲和性、污点和容忍性等特征
- Controller Manager: 负责维护集群的状态,通过运行各种类型的控制器进程 (例如 NodeController, PodController, JobController),每个控制器保证对应资源的状态向期望值收敛
- etcd: 持久化存储集群配置、状态、元数据,担任后端 “服务发现 + 数据库” 的角色,是集群中唯一的 “有状态” 组件
控制平面组件会存储和管理集群状态,控制并保证整个集群正常运行,但是不运行具体的应用容器。
工作节点上的组件
下面的三个组件会在集群中的每个节点上运行。
- kubelet: 负责管理所在节点上面的容器和网络 (CNI),通过和控制平面的 API Server 进行通信,对节点上的各类资源操作管理和状态上报
- kube-proxy: 每个节点上运行的 “网络代理”,通过维护网络转发规则 (iptables, ipvs),将流量分发到对应的 Pod 中,
- CRI (容器运行时): 实现了 OCI 标准的容器类型,例如 Docker, containerd 等
附加组件
除了控制平面和工作节点上面的组件之外,还需要一些其他组件,通过组合来共同完成集群提供的功能。
DNS (必要组件)
表示集群内部运行的 DNS 服务器 (默认使用 CoreDNS),负责为 Kubernetes 服务提供 DNS 记录,Pod 中的容器自动将此 DNS 服务器包含在搜索列表中。
容器资源监控
存储容器运行时 Metrics 数据并提供浏览和查询,一般是集成到 Prometheus 完成。
集群日志
存储 Node 和 Pod 的日志数据并提供浏览和查询,一般是集成到 EFK 集群。
CNI
CNI (Container Network Interface) 表示容器网络接口,用于定义容器运行时如何与底层网络解耦,主要负责为 Pod 分配 IP 地址,保证 Pod 能在集群内部相互通信。
仪表盘 (Web 页面)
基于网页的 Kubernetes 用户界面,用户通过仪表盘可以管理集群、各类资源、应用容器、故障排查。
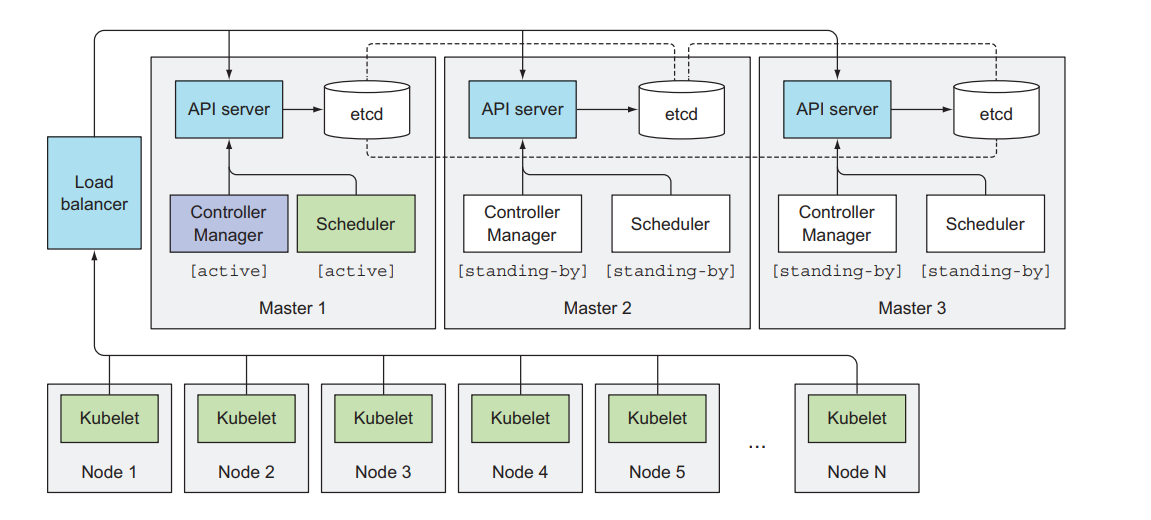
集群高可用
开发者应该尽可能将服务设计成 无状态应用,保证应用本身可以水平扩展, 然后为对应的 Deployment 配置不同的副本数量,剩下的工作交给 Kubernetes 处理就可以了。
控制平面
为了保证服务不中断,除了应用本身之外,更重要的是 kubernetes 控制平面组件要稳定运行,可以通过运行下面各组件的多个实例,形成多个 “主节点” 协同运行。
- API Server
- Scheduler
- Controller Manager
- etcd
如图所示是一个三节点的高可用集群。
API Server
API Server 本身就是无状态的 (所有数据都存在在 etcd 中),所以直接运行多个实例即可。典型的配置方案是: 单节点部署一个 API Server 实例加一个 etcd 实例, etcd 实例之前不需要任何负载均衡,因为每个 API Server 只和本地 etcd 实例进行通信。 但是 API Server 需要一个负载均衡, 这样可以保证所有需要和 API Server 通信的客户端 (Controller Manager、Scheduler, kubectl,Kubelet) 总是可以连接到健康的 API Server 实例。
Scheduler 和 Controller Manager
相比于 API Server,Scheduler 和 Controller Manager 运行多个实例会相对比较复杂,因为 Scheduler 和 Controller Manager 都会积极地监听集群状态, 并在监听数据状态发生变更时做出对应操作,(例如,当 Deployment 的期望复制数增加时,DeploymentController 会创建新的 Pod), 组件运行多个实例时,每个实例都会执行同一个操作,不可避免产生竞争状态,从而造成非预期的结果 (例如,本来只需要创建 2 个新 Pod, 结果三个实例创建了 6 个)。
基于上述原因,当运行多个 Scheduler 和 Controller Manager 实例时,给定时间内应该保证只有一个实例有效 (领导者), 只有当选为 “领导者” 的实例才能真正执行操作,其余实例都处于候选状态,当领导者实例宕机时,候选实例开始选举新的领导者接管工作。
Scheduler 和 Controller Manager 可以和 API Server 部署在同一节点,这样全程都是本地通信。
领导者选举机制
领导选举机制: 多个实例 (Scheduler 或 Controller Manager) 会同时向 API Server 发起创建资源请求,第一个创建成功的实例就会成为领导者, 内部采用了类似 “乐观锁” 的机制,保证即使多个实例同时发起请求,最后只会有一个实例写入成功。
一旦成为领导者,必须定时更新资源 (默认 2 秒),这样候选实例就可以知道领导者状态是否正常,当领导者实例发生故障,候选实例就会发起创建资源请求并尝试成为领导者。
etcd
除了持久化存储集群配置、状态、元数据之外,etcd 还会存储如 ConfigMap, Secret 等数据,etcd 会在多个实例间复制数据,所以多个节点中的一个节点宕机时,不会影响数据读写操作。
高可用性是通过部署奇数个数量节点来完成:
节点数量 = 节点故障容忍数量 * 2 + 1
例如为了容忍 2 个或者 3 个节点宕机,需要运行 5 个或 7 个 etcd 节点,但是节点数量并不是越多越多,过多的节点会对性能造成影响,尤其是当节点跨数据中心甚至跨区域的情况。
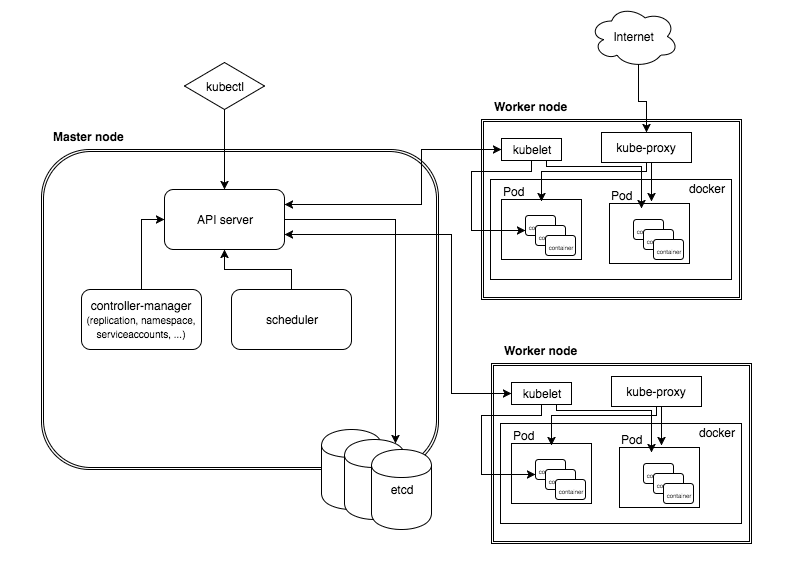
通信
集群各组件只能通过 API Server 进行通信,而不是组件之间直接通信。
API Server 是唯一和 etcd 通信的组件,其他组件获取/修改集群状态数据时,会将请求发送至 API Server, 然后由 API Server 处理成对应的读写请求并转发到 etcd, 最后将 etcd 的响应结果返回给请求方组件。
控制平面可以订阅资源被创建、修改或删除的通知,各组件可以利用这个功能,在资源数据发生变化时执行任何对应的操作。
下面是一个创建 Pod 的流程示例:
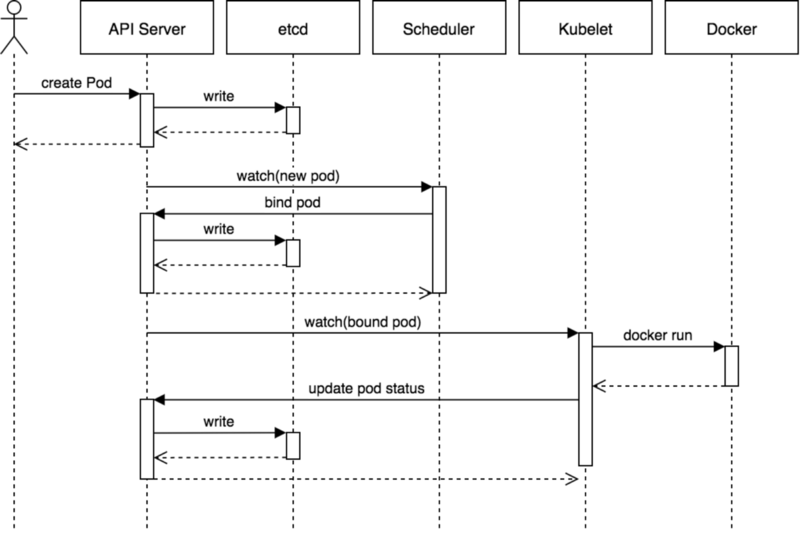
通信协议
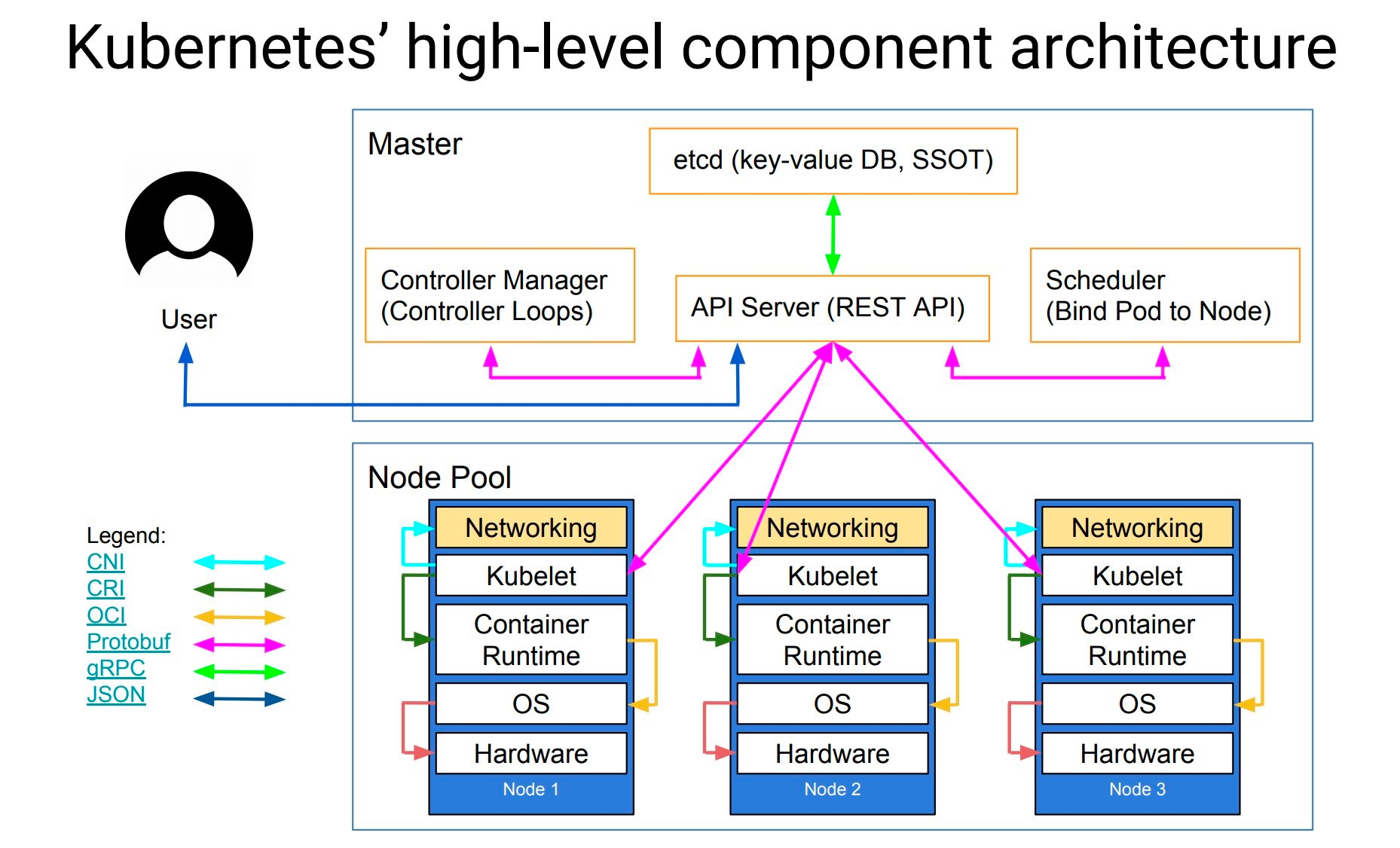
通过上面的大图,可以非常清晰地看到 Kubernetes 集群中组件之间的通信协议,例如:
- API Server 和 etcd 之间使用 gRPC 协议
- 控制平面内的组件之间、控制平面组件与 kubelet 之间使用 Protobuf 序列化编码协议
- …
小结
Kubernetes 组件概览: