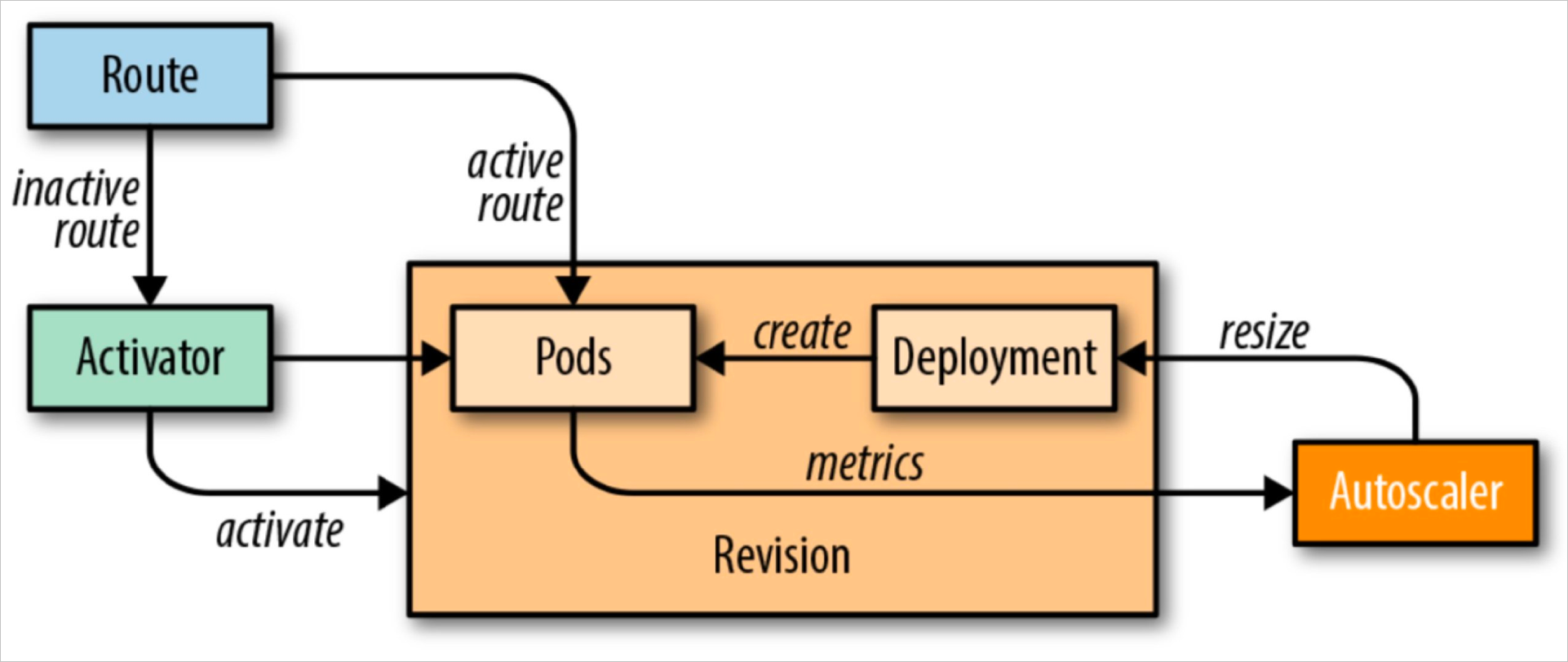
Kubernetes 应用最佳实践 - 水平自动伸缩
2023-04-14 Cloud Native Kubernetes Kubernetes 应用最佳实践
概述
水平自动伸缩 (Horizontal Pod AutoScale) 简称 HPA, 目标是自动伸缩 Pod 的副本数量来满足应用服务负载。
Kubernetes 可以监控应用 Pod, 并在检测到度量指标 (例如 CPU 使用率, 内存使用率) 发生变化时自动对 Pod 进行扩容或缩容。 如果 Kubernetes 运行在主流云计算服务商提供的集群环境中,甚至可以在现有节点无法负载更多 Pod 时自动创建更多新节点 (按需付费),也就是说,实现了 Node 的自动伸缩。
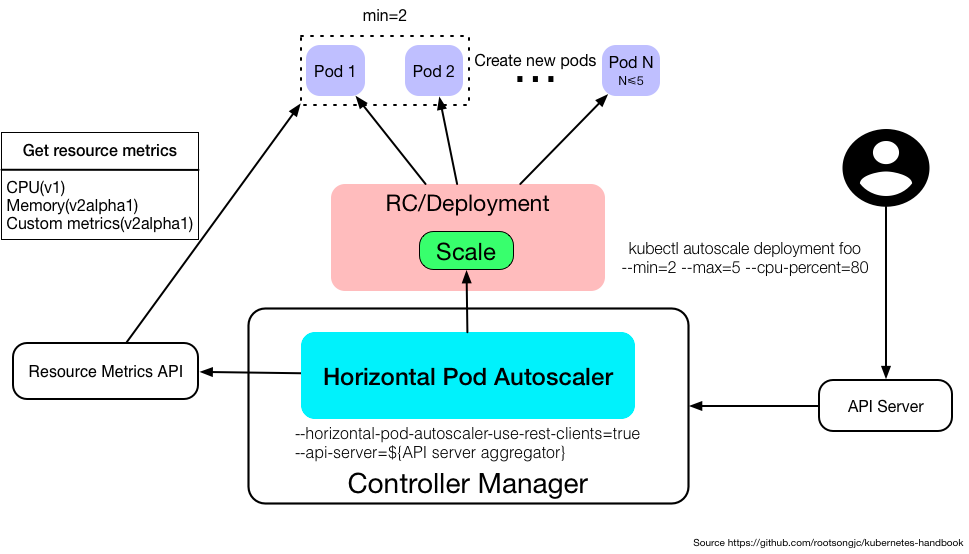
使用方式
创建了 Deployment 之后,为了使对应的 Pod 自动伸缩,需要创建一个 HPA 对象,并将它指向 Deployment。
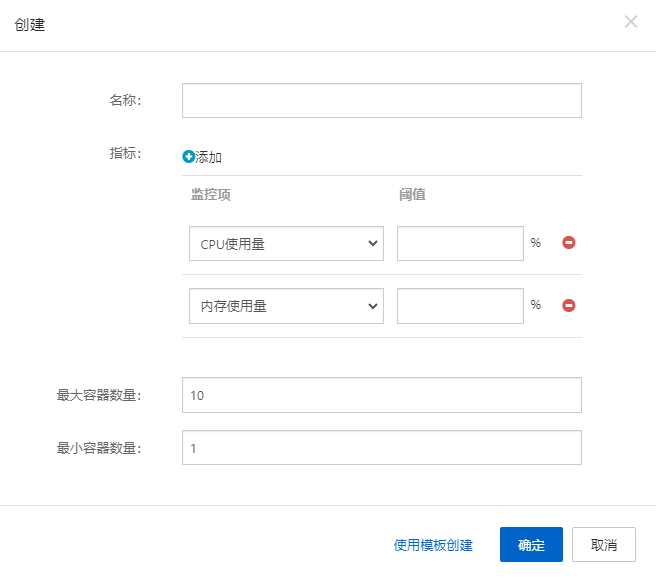
指标伸缩

对应的 yaml 声明代码如下:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
...
spec:
metrics:
- resource:
name: cpu
target:
averageUtilization: 70
type: Utilization
type: Resource
如果 Kubernetes 运行在主流云计算服务商提供的集群环境中,直接使用对应的界面化操作即可。
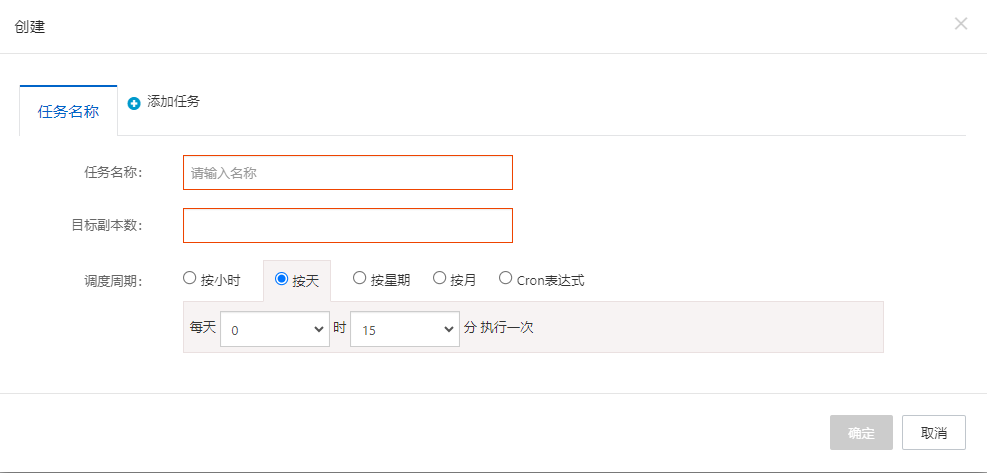
定时伸缩
关键问题
水平自动伸缩的关键问题是使用哪些指标,指标值和 Pod 副本数量之间必须存在直接关联。
例如 HPA 指标为 QPS, 增加 Pod 的副本数量后,每个 Pod 的 QPS 会下降,因为流量分到了更多的 Pod 上面,那么可以说 QPS 指标和 Pod 副本数量是关联的。
CPU 使用率
如果 HPA 指标是 CPU 使用率,增加 Pod 的副本数量后,每个 Pod 的 CPU 使用率会下降,因为单个 Pod 的流量下降了,所以 CPU 利用率指标和 Pod 副本数量是关联的。
注意: 一定要为自动伸缩的 Pod 设置 CPU 请求与限制,否则 Kubernetes 无法确认 CPU 使用率的主体是指节点 CPU、还是资源请求量 CPU, 还是用资源限制量的 CPU。
内存使用率
如果 HPA 指标是 内存使用率,增加 Pod 的副本数量后,如果希望每个 Pod 的内存减少,至少需要满足以下三个条件:
- 应用本身的组成形态是集群方式,每个 Pod 实例可以了解到清晰实例的信息
- 应用本身负责整个集群中的一部分数据 (例如以分布式一致性算法为基础设计的数据集群)
- 每个 Pod 实例具有分配和自动释放失效数据的机制
否则,Pod 实例中的内存使用会越来越多,导致 HPA 创建越来越多的 Pod,直到副本数量的上限,所以如果使用内存作为 HPA 指标,需要尽可能精准地预估出单个 Pod 的内存使用上限。
其他因素
除了考虑应用本身所需资源外,还要考虑相关技术栈运行时的资源,例如使用 Go 语言开发的应用在运行时有 GMP 调度、GC 带来的资源消耗。
缓冲区大小
假设 Pod 的 HPA 指标中的 CPU 利用率为 70%, 这意味着 Pod 具有 30% 的 CPU 缓冲区,当 Pod 负载超过 HPA 指标导致扩容并且新的 Pod 未完成就绪前, 这个中间过渡阶段的负载可以交给这 30% 的缓冲区。
- 如果缓冲区设置的比较小,可以避免 Pod 过早扩容,但是会在业务高峰期造成 Pod 负载过重
- 如果缓冲区设置的比较大,可以避免 Pod 负载过重,但是可能会造成资源浪费
所以应该保证集群有相对充足的节点,毕竟 Node 的自动伸缩相对 Pod 的自动伸缩是比较费时的,同时要保证缓冲区可以应对的时间要远远大于 Pod 的启动 + 就绪时间。
优化设置
QPS
通过压测计算出单个 Pod 的负载极限请求处理量,然后设置 HPA 中对应的 QPS 值。
- 开始压测前,关闭应用的自动伸缩
- 进行压测,获取隔离的单个 Pod 的负载上限
- 根据压测结果和目标应对负载配置资源请求和资源限制参数、HPA 参数
- 重新开始压测并逐次加大强度
- 根据压测结果调整各项参数
- 重复第三步到第五步,直到性能到达预期为止
快速扩容
当应用服务遇到突增流量需要快速扩容时,可以指定 HPA 中的 spec.behavior.scaleUp 字段:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
spec:
minReplicas: 1
maxReplicas: 1000
metrics:
...
behavior:
scaleUp:
policies:
- type: percent
value: 900% # 可以根据具体业务进行调整
上面的配置表示扩容时新增当前 Pod 数量的 9 倍,也就是说,Pod 扩容后的数量是当前数量的 10 倍,且最多为 1000 个。
假设刚开始只有一个 Pod, 在遇到突增流量时,扩容的数量变化依次为 1 -> 10 -> 100 -> 1000 (最大副本数)。
慢速缩容
默认情况下,扩容 5 分钟后开始缩容,与快速扩容对应的就是快速缩容,Pod 的数量很快会减少至扩容前的数量,如果此时再来一波突增流量,那么之前的扩容工作就全部白做了, 除了扩容本身花费的时间之外,更重要的还有应用服务本身内部的业务逻辑工作也全部清零 (例如应用的热点数据本地缓存、网络连接等)。
更好的方案应该是慢慢缩容,可以指定 HPA 中的 spec.behavior.scaleDown 字段:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
spec:
minReplicas: 1
maxReplicas: 1000
metrics:
...
behavior:
scaleDown:
stabilizationWindowSeconds: 1800
policies:
- type: pods
value: 1
periodSeconds: 60 # 单位: 秒,可以根据具体业务进行调整
上面的配置表示缩容之前需要等待 30 分钟,并且缩容时每 1 分钟只能减少 1 个 Pod, 这样即使遇到突增流量,也不会造成太大的影响。
监控
随着集群规模扩大和应用频繁自动伸缩,如果纯靠人工手动的方式查看和追踪各服务链路,很难快速有效地定位到问题,也很难追溯历史,基本不可能捕捉和发现一些瞬时和阶段性问题。 这时我们就需要一个强有力的自动化监控系统,辅助采集并展示具体的 Node、应用 Pod 指标数据。
下面以笔者在工作中使用的阿里云 Kubernetes 集群服务,演示一下常用的几个功能。
节点大盘

主要查看指标为:
- 是否开启节点自动伸缩
- 节点总数量如果不等于节点可用数量,说明存在异常节点
- Pod 正常/异常 数量
- Service 正常/异常 数量
- …
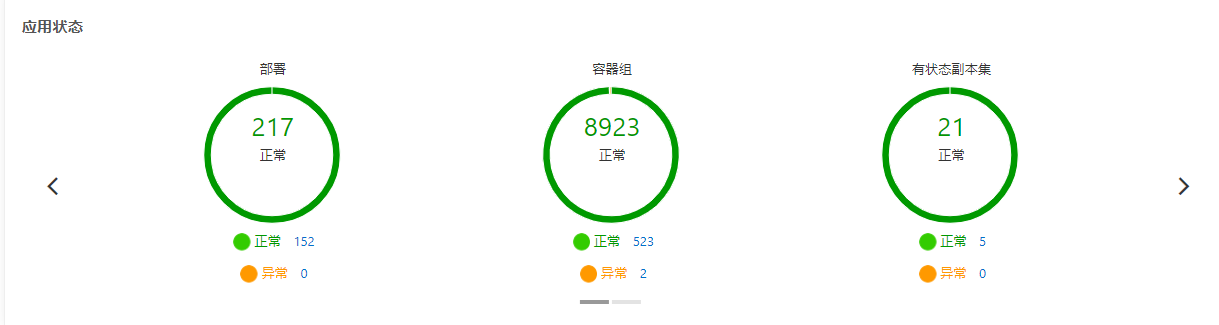
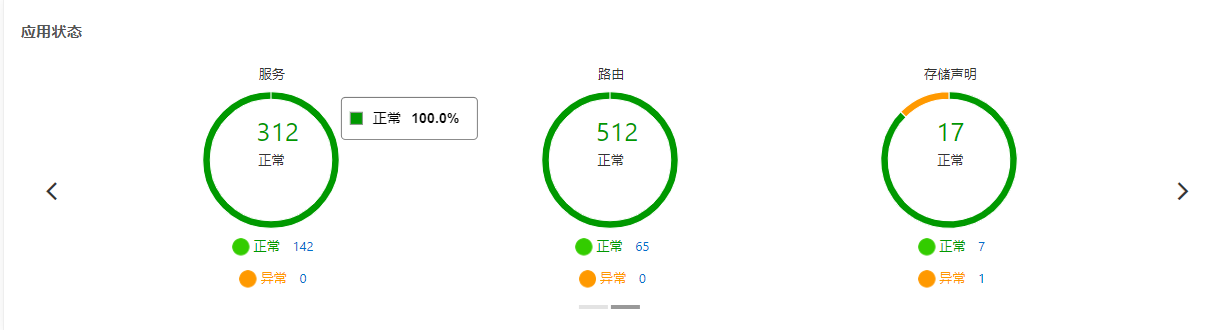
Node 详情
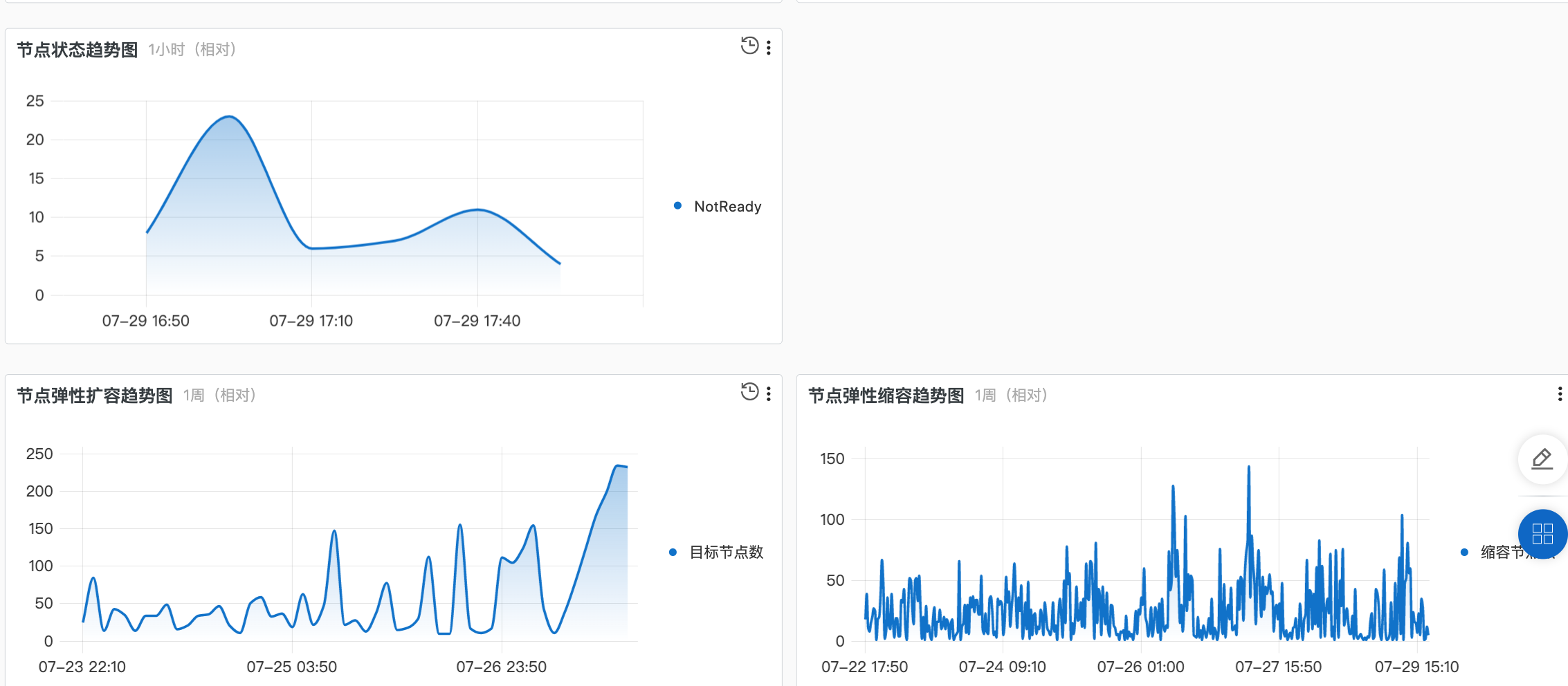
Pod 详情
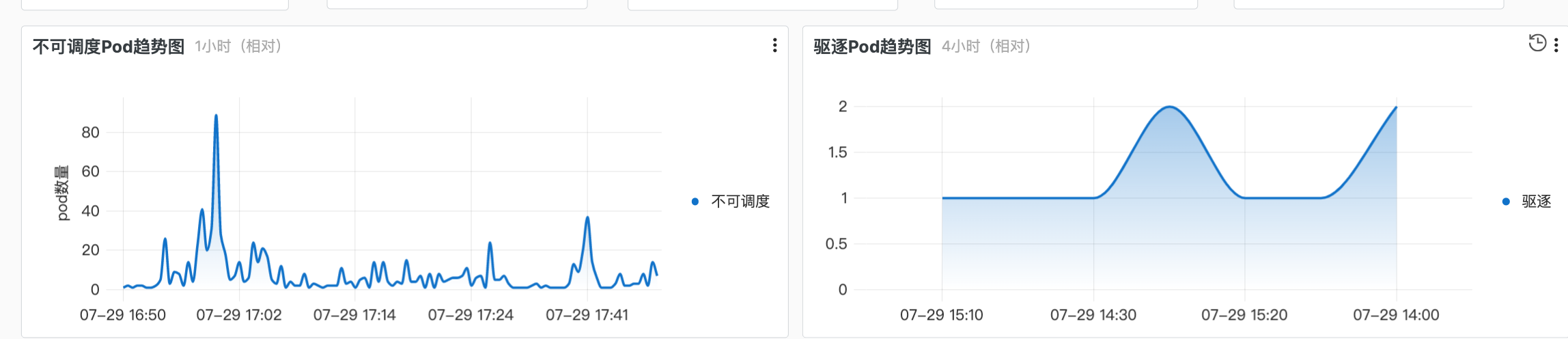
Prometheus
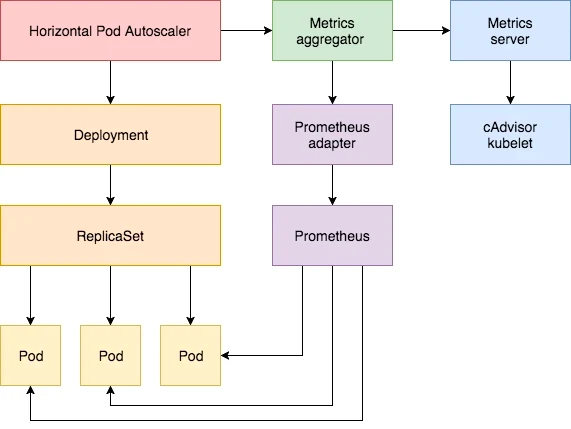
AHPA
虽然 HPA 可以实现应用的自动伸缩,但是这个过程本身是有滞后性的,例如 CPU 利用率 60%,监控系统发现 Pod 负载压力变大超过了指标的阈值,HPA 才会开始扩容 Pod 副本数量。 针对这个问题,腾讯云推出了 AHPA, 能够识别适合水平自动伸缩的应用程序,制定计划并自动进行操作。与原生 HPA 相比,AHPA 消除了手动配置和原生 HPA 滞后性问题,彻底解放运维, 感兴趣的读者可以自行了解。
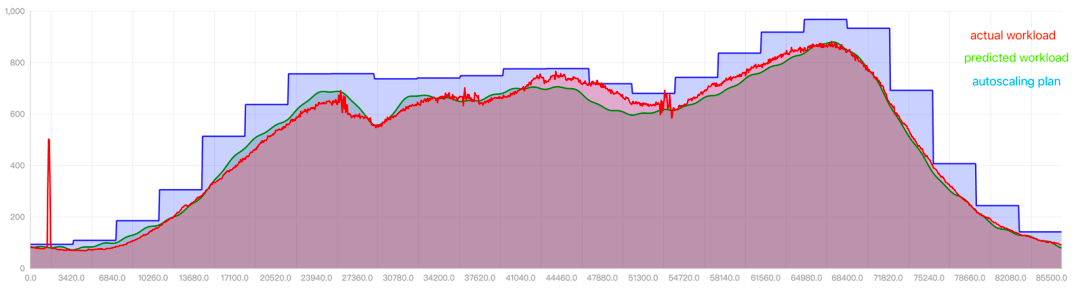
- 红线是实际资源使用量
- 绿线是预测资源使用量
- 蓝线是弹性推荐的资源使用量
HPA 最佳实践
- 确保应用服务可以水平扩展,并且可以快速启动
- 确保监控系统持续和稳定运行
- 确保 HPA 指标值和 Pod 副本数量之间必须存在直接关联性
- 确保设置资源请求和限制,并且预留适当的缓冲区,并根据监控功及时调整参数
- 通知客户端或服务下游,请求时必须考虑服务故障,并采取适当的容错机制,如重试、回退策略或熔断机制 (例如采用指数退避重试算法重新发起请求)
- 针对确定的流量峰值,提前扩容而非仅仅依赖于 HPA, 在流量峰值过后,不要着急缩容,避免突增的 “二次峰值”
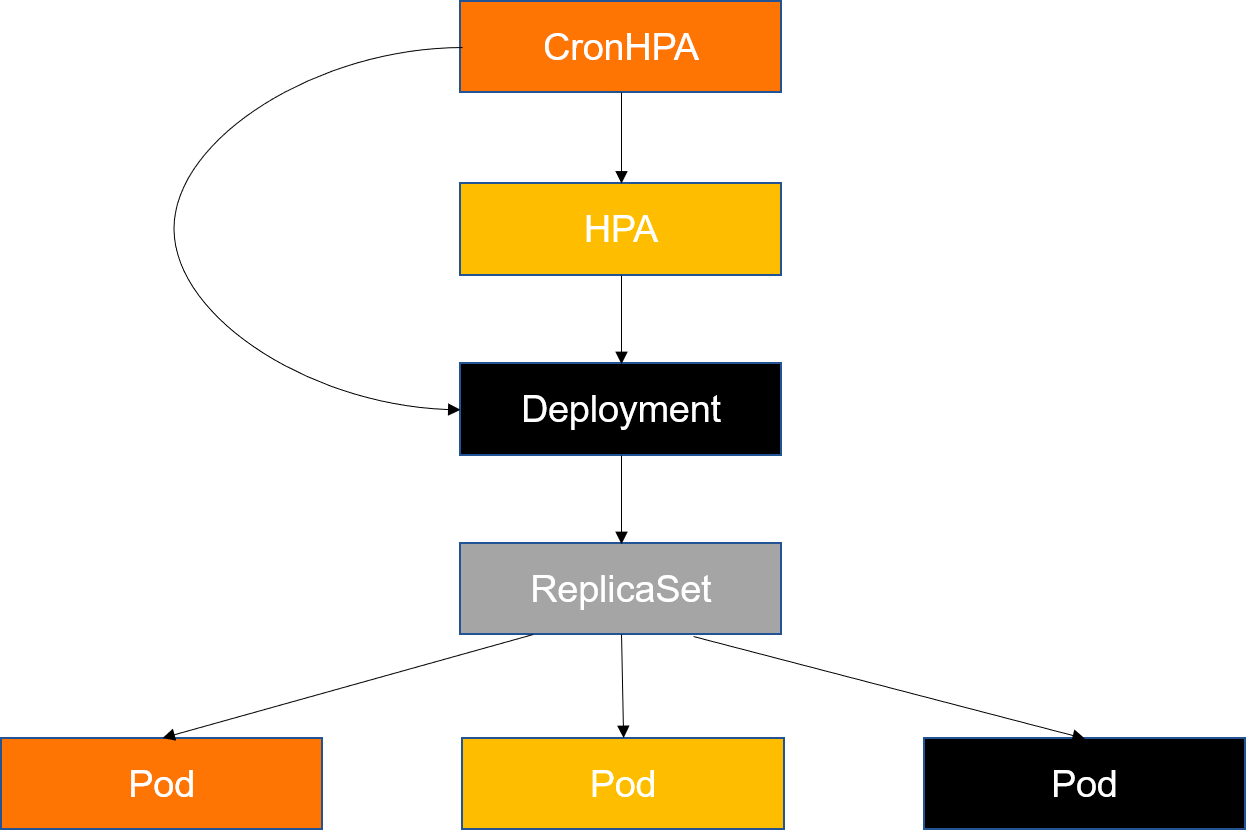
- 针对定期的流量高峰 (例如游戏业务中的周末活动),或者流量高峰在夜间,这时可以通过 CronJob + 自动伸缩 API 实现更智能的 HPA
- 如果有成本方面的考虑,要注意 minReplicas(最小副本数)、maxReplicas(最大副本数)和 targetAverageUtilization(目标平均利用率)等参数
