Kubernetes 应用最佳实践 - 探针
2023-03-03 Kubernetes Kubernetes 应用最佳实践
探针类型
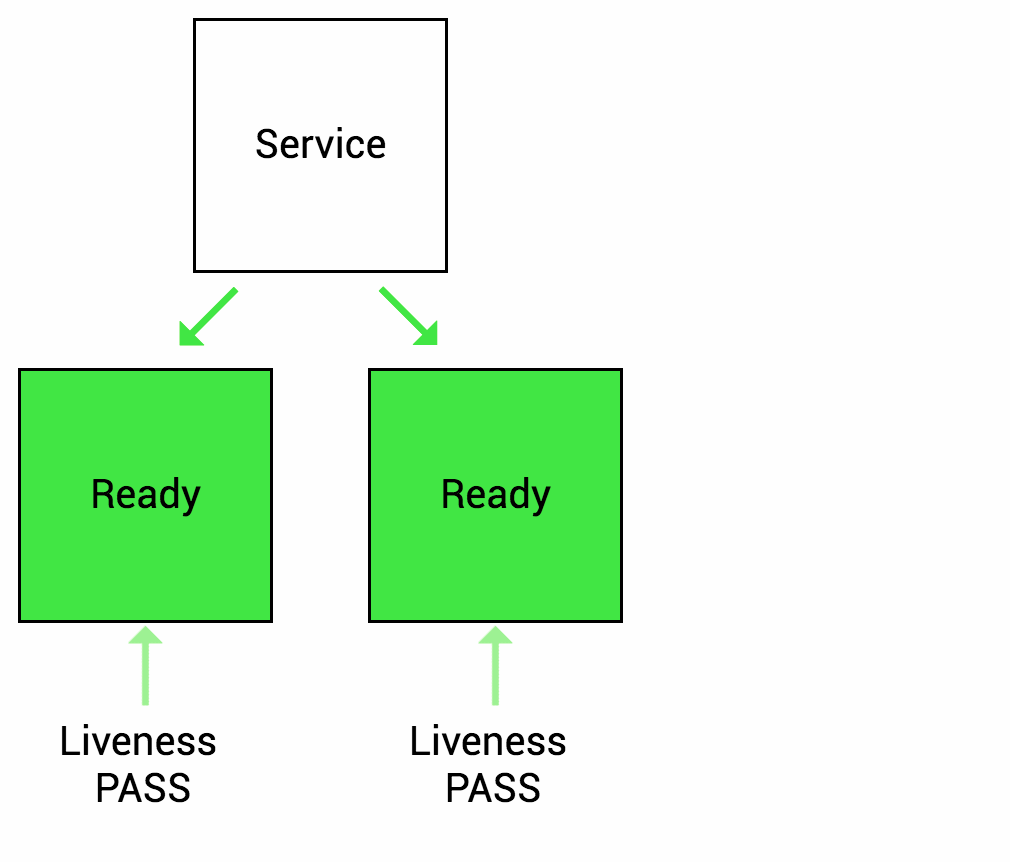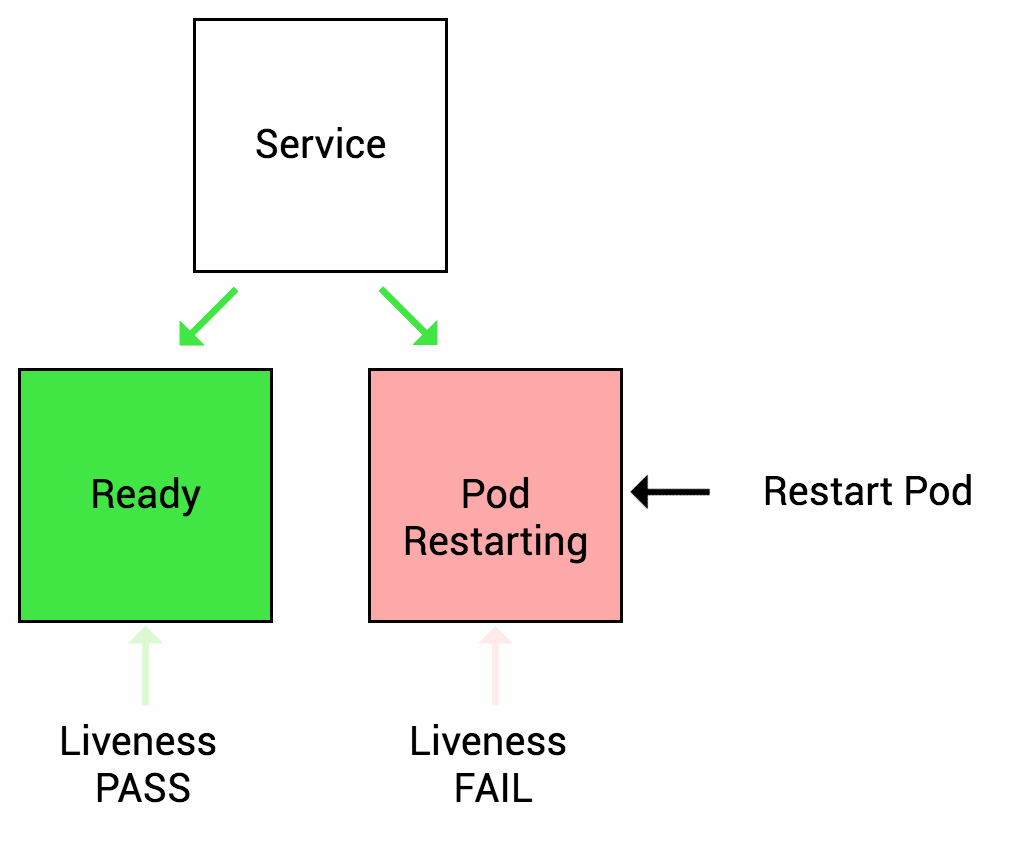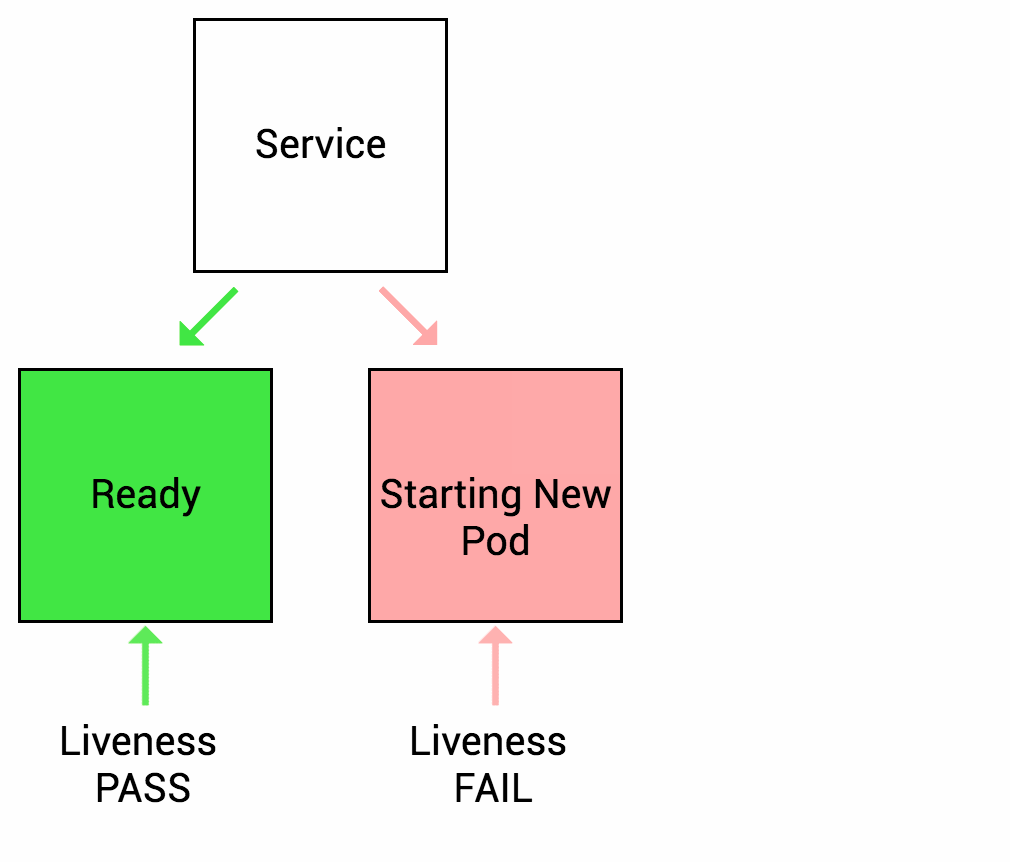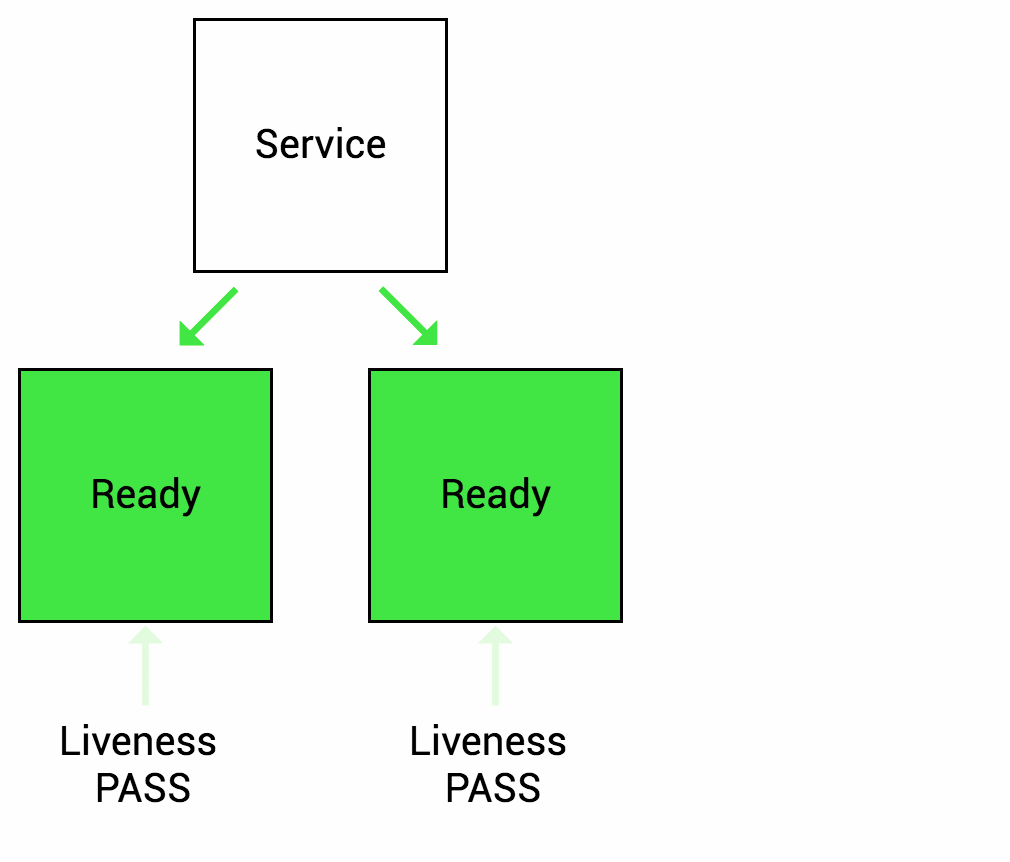
Kubernetes 存在 3 种类型的探针,当探针检测失败时容器会被重启,如果容器在多次 (次数通过配置参数决定) 重启后仍然无法通过探针检测,容器状态将会被设置为 CrashLoopBackOff, 这意味着容器处于崩溃循环状态,无法成功启动和运行。
启动探针
Startup Probe (启动探针) 用于检测容器是否已经完成所有初始化操作。
存活探针
Liveness Probe (存活探针) 用于检测容器内部应用是否在运行,可以为单个 Pod 中的所有容器单独设置,存活探针会监控容器的健康状态,如果容器发生故障或崩溃,存活探针会判断容器不再存活,容器会被重启或替换。
一旦启动探针成功返回一次,存活探针就开始接管对容器对监控。
就绪探针
Readiness Probe (就绪探针) 用于检测容器是否已经准备好接收流量,应用启动需要一系列初始化操作,就绪探针可以确保容器就绪前不会接收任何流量。 如果就绪检测失败,Pod 就不会再收到任何流量。
检测方式
HTTP GET
针对容器指定 URL 执行 HTTP 请求,如果响应码 Status Code 是 2xx 或者 3xx, 将应用标记为正常运行。否则将应用标记为不健康。
TCP
针对容器指定端口号发起 TCP 连接,如果连接成功,将应用标记为正常运行。否则将应用标记为不健康。
该方法主要针对 HTTP 探针或命令探针无法运行的情况,例如 gRPC 或 FTP 等协议。
Exec
在容器内执行任意命令 (例如文件检查、网络检查),并检查命令的退出状态码,如果状态码为 0,将应用标记为正常运行。否则将应用标记为不健康。
重要参数
initialDelaySeconds
表示容器启动后,等待多少时间之后再启动各类探针
periodSeconds
表示探针执行检测的间隔时间
timeoutSeconds
表示探针执行检测的超时后的等待时间
successThreshold
表示探针执行检测失败之后,如果容器状态想再次被标记为健康,至少需要经过多少次连续成功检测
failureThreshold
表示探针执行检测时,连续失败多少次,容器状态就会被确认不健康
最佳实践
启动探针
如果应用的启动时间过长,应该设置一个启动探针,并且将 initialDelaySeconds 参数的值设置为大于应用的启动时间,应用启动时, 不应该因为数据库等依赖项尚未就绪而崩溃,例如应该在连接失败后继续尝试重新连接,直到连接成功或者重试次数超出最大限制。
initialDelaySeconds 参数的取值可以参考监控中的应用启动时间 P99 分位值。
启动探针常用业务场景:
- 数据库连接池初始化完成
- 缓存连接池初始化完成
- 热点数据缓存在本地初始化完成
还有一种做法是,直接将 initialDelaySeconds 参数值设置为大于应用启动的估计时长,不使用启动探针。
存活探针
如果应用在发生鼓掌时无法自动结束退出 (例如遇到了死锁),应该设置一个存活探针,并指定 restartPolicy 为 “Always” 或 “OnFailure”, 这样该应用会被重启。
就绪探针
如果需要应用在完成初始化工作之后才能开始接收流量,应该设置一个就绪探针,这样可以避免流量进入到错误到 Pod 中。
就绪探针可能与存活探针相同,但是 就绪探针表示 Pod 在初始化阶段不接收任何流量,并且只有就绪探针返回成功后再开始接收流量, 虽然使用启动探针也可以完成同样的功能,但是就绪探针可以区分应用位于 “正在启动中” 和 “已经完成启动,正在当前状态是正常|失败” 两个不同的阶段中的哪一个。
小结
就绪探针和存活探针可以同时用于同一 Pod,这样可以确保流量无法到达未准备好的 Pod,并且在探针检测失败时重启。
就绪探针和存活探针应该保持独立 (不使用相同的检测逻辑),不应该依赖于数据库的状态或者第三方接口返回的结果值,避免发生故障雪崩 (例如数据库状态不稳定可能导致 Pod 被标记为不健康), 也不要将 Pod 的重启、删除等逻辑混入探针逻辑,让 Kubernetes 自动完成这些操作。
探针应该保持轻量,运行时不需要太多的资源和时间,大对数情况下,探针执行检测的频率相对较高,并且必须在 1s 之内返回结果。 探针中不需要实现重试循环,因为探针的失败阙值是可以通过参数配置的。
定义期望的状态,剩下的交给 Kubernetes 来完成。
其他观点
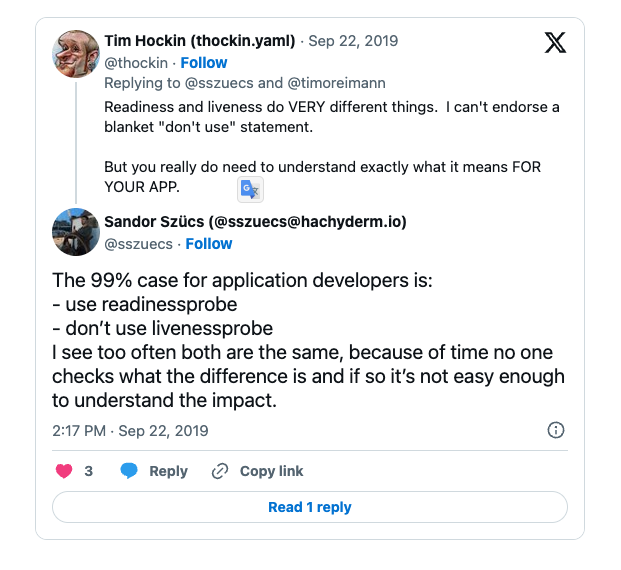
这篇文章 的建议是为了避免级联故障,不要使用存活指针,而是应该保证应用代码的健壮性,不要出现死锁等卡死容器的 Bug。
