Kubernetes 应用最佳实践 - 资源请求和限制
2023-03-01 Cloud Native Kubernetes Kubernetes 应用最佳实践
概述
通过定义 Pod 中容器的资源限制和请求,确保资源的公平分配并防止资源争用。资源限制指定 Pod 可以使用的最大资源量,而资源请求指定 Pod 运行所需的资源量,正确设置资源限制和请求,有助于防止资源耗尽并确保应用程序的最佳性能。
资源请求和限制并不在 Pod 的声明中指定,而是针对 Pod 中的每个容器单独指定,单个 Pod 内部所有容器的资源请求量和限制量之和,等于该 Pod 的资源请求量和限制量。
- requests: 表示资源请求量
- limits: 表示资源限制量
两者的关系如下:
requests <= limits
下面的 yaml 声明代码表示,对于 Pod 中的容器 my-container:
- 资源请求量为 0.5 个 CPU,128 MB 内存
- 资源限制量为 1 个 CPU,256 MB 内存
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image:tag
ports:
- containerPort: 80
resources:
limits:
cpu: 1
memory: 256Mi
requests:
cpu: 0.5
memory: 128Mi
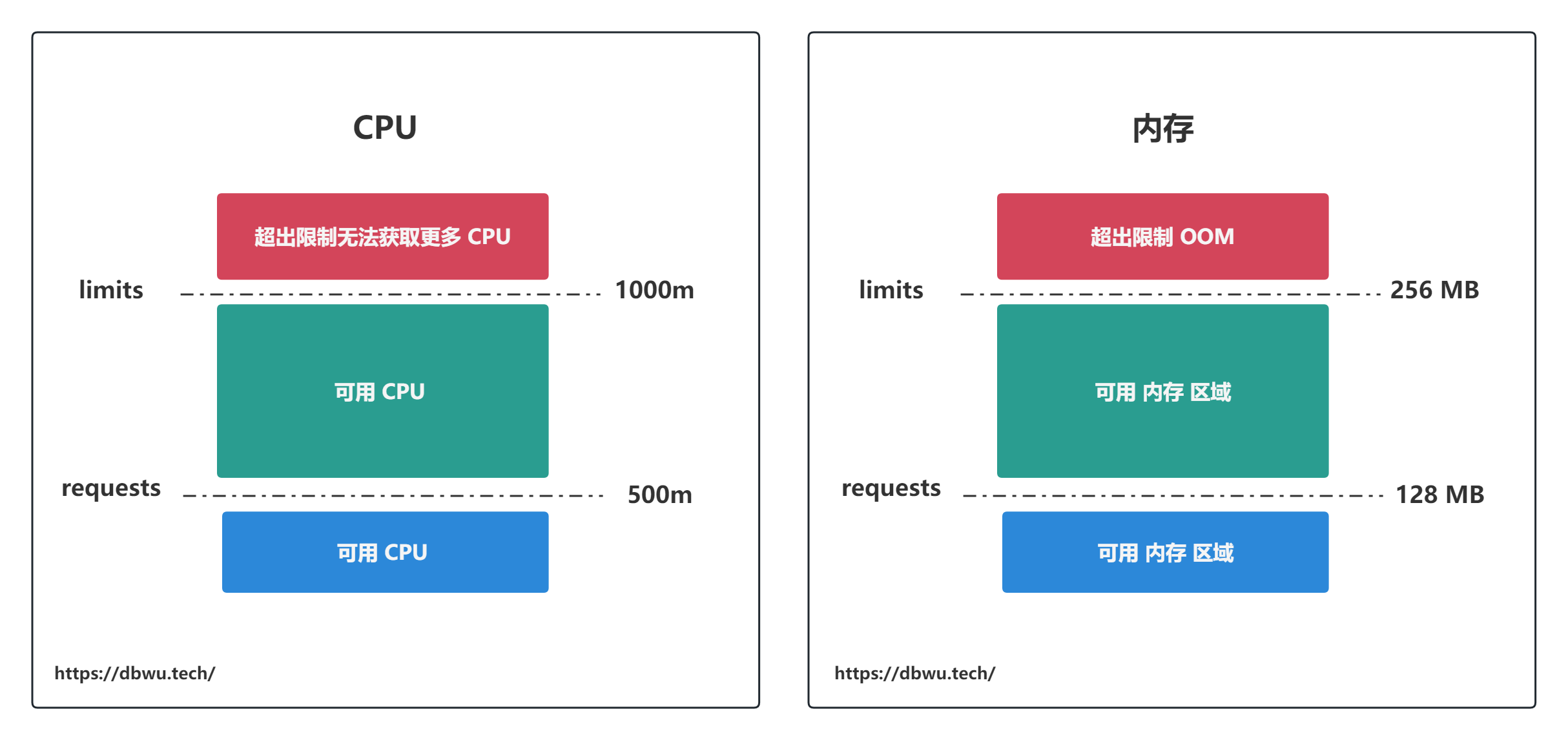
Kubernetes 会将资源请求量 requests 和资源限制量 limits 区分对待:
- 容器的 CPU 请求量为 0.5 个 CPU,但是可以超出使用,并且最多可以使用 1 个 CPU (limits 硬性规定)
- 容器的 CPU 请求量为 128 MB 内存,但是可以超出使用,并且最多可以使用 256 MB 内存 (limits 硬性规定)
单位
CPU 资源的基本位置是 m (milli cpu), 精度最小为 1m,举例来说:
- 1 个 CPU 资源表示为 1000m, 也可以使用数字 1
- 0.5 个 CPU 资源表示为 500m, 也可以使用数字 0.5
CPU 资源请求量要使用绝对数量,而非相对数量,0.1 的 CPU 请求量在单核、双核、64 核的机器中表达的语义是相同的,常见使用单位为 XXX m。
内存资源的基本单位是字节 (byte), 可以使用这些后缀之一,将内存表示为整数 (表示 byte) 或定点整数 (附带单位): E、P、T、G、M、K、Ei、Pi、Ti、Gi、Mi、Ki,
常见使用单位为 XXX Mi。
128974848, 129e6, 128M, 128Mi
默认情况
如果不指定 CPU limits 数值,表示系统并不关注容器的资源请求量,也就是说: 在极端场景下,容器内的进程可能会跑满 CPU, 或者根本分配不到 CPU 时间 (因为其他进程把 CPU 跑满了)。 对于内存 limits 数值来说,也会有类似极端场景下的问题。
CPU
CPU 是一种可压缩资源,因为它在多任务处理和资源分配方面具有一定的弹性,也就是说,Pod 中的所有容器都会尽可能抢占未使用的 CPU 资源。
CPU requests 数值不仅在调度时起作用,还决定着未使用的 CPU 时间如何在容器之间分配。
kind: Deployment
apiVersion: extensions/v1beta1
template:
spec:
containers:
- name: redis
image: redis:5.0.3-alpine
resources:
requests:
cpu: 0.8
- name: busybox
image: busybox:1.28
resources:
requests:
cpu: 0.2
以上面的 yaml 声明代码为例子,在一个 Pod 中存在两个容器 (redis 和 busybox),redis 的 CPU 资源请求量为 0.8 (800m), busybox 的 CPU 资源请求量为 0.2 (200m), 那么 Pod 中未使用的 CPU 资源将按照 1:4 的比例分配给这两个容器,这里假设该节点只要 1 个 CPU,那么可能会产生下面几种情况:
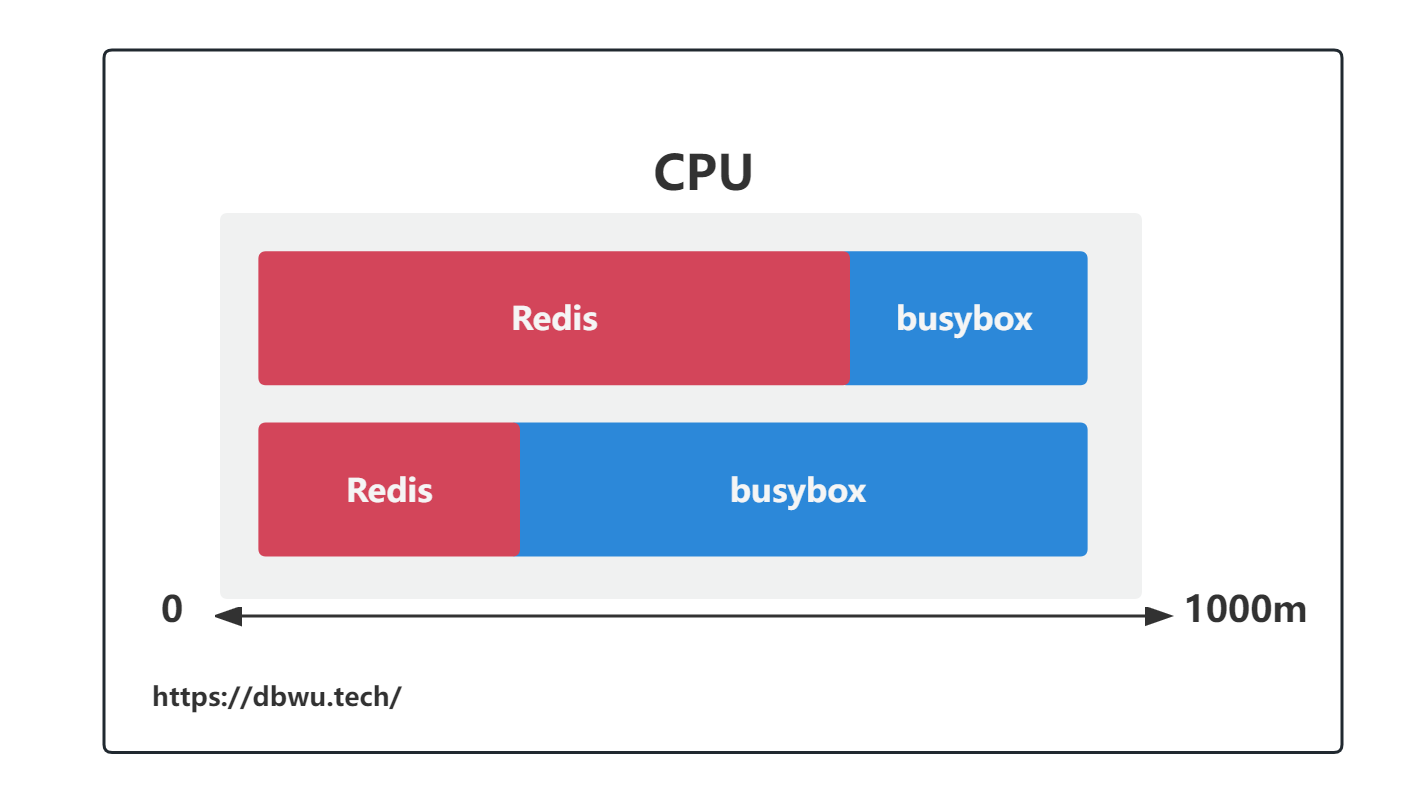
- redis 和 busybox 都在尽全力使用 CPU, redis 获得 80% 的 CPU 时间,busybox 获得 20% 的 CPU 时间
- redis 和 busybox 都处于闲置状态,此时 CPU 使用为 0
- redis 处于闲置状态,此时 busybox 获得 100% 的 CPU 时间
- busybox 处于闲置状态,此时 redis 获得 100% 的 CPU 时间
通过第三种情况和第四种情况可以看到,当两个容器中的其中一个闲置时,另外一个容器通过占用整个 CPU 而显著提高 CPU 资源的利用率, 如果此时闲置的容器恢复了运行,依然可以直接获取到 requests 字段定义的 CPU 请求资源量,与此同时另外一个容器的 CPU 资源就会被限制到其 limits 字段定义的 CPU 请求资源量。 此消彼长间,实现了 “CPU 资源超售”。
内存
和 CPU 资源不同,内存是无法压缩的资源,一旦系统为进程分配了内存,那么这块内存在进程主动释放之前将无法被回收 (高级语言中的 GC 也属于主动释放内存)。 因此当内存耗尽时需要移除并重新调度 Pod,为了避免这种情况发生,必须设置内存的资源限制量。
超出资源限制
当 Pod 中的容器内尝试使用比资源限制 limits 更多的资源时,会发生什么呢?
对于 CPU 来说,因为是可压缩资源,所以当容器超出 CPU 资源限制时,容器内的进程也仅仅只是分配不到更多的 CPU 资源而已。
对于内存来说,情况则完全不一样,当容器超出内存资源限制时,容器内的进程会因为 OOM 被 Kill。 如果 Pod 的重启策略为 Always 或 OnFailure,进程将会立即重启,重启之后如果进程内存依然超出请求限制量而被 Kill, Kubernetes 会增加下次重启的间隔时间。这种情况下 Pod 处于 CrashLoopBackoff 状态。
CrashLoopBackoff 状态
CrashLoopBackoff 状态表示 Kubelet 还没有放弃该 Pod, 在每次崩溃之后 Kubelet 就会增加下次重启之前的间隔时间。
- 第一次崩溃之后,Kubelet 立即重启 Pod
- 第二次崩溃之后,Kubelet 会等待 10 秒钟后再重启 Pod
- 随着不断崩溃,延迟时间也会按照 20、40、80、160 秒以几何倍数增长并最终收敛在 300 秒
- 此后 Kubelet 将以 300 秒为间隔对 Pod 进行无限重启,直到 Pod 恢复正常或者被删除
LimitRange
LimitRange 用于 Pod 的资源限制和默认值设置, 不仅可以对单个命名空间中的 Pod 和容器的最小和最大资源量进行限制,还可以设置资源请求量和限制量的默认值, 并且在运行时自动注入到容器中。
如果不想为命名空间中的每个容器单独设置资源请求量和限制量,可以通过创建 LimitRange 资源来简化流程。
下面是一个针对容器定义的 LimitRange 资源:
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-constraint
spec:
limits:
- default: # 资源默认限制值
cpu: 0.5
defaultRequest: # 资源默认请求值
cpu: 0.5
max: # 最大使用量
cpu: 1
min: # 最小使用量
cpu: 0.1
type: Container
注意: LimitRange 不会校验默认值的一致性,Pod 和容器设置的资源限制量 (limits) 数值可能要远远大于 LimitRange 资源设置的 limits 默认值, 这时 Pod 无法被调度。也就是说,LimitRange 中配置的 limits 数值只能应用于单个 Pod 或容器,用户依旧可能因为误操作而创建大量的 Pod 和容器,消耗掉集群的所有可用资源, 如果要解决这个问题,需要使用 ResourceQuota 资源。
ResourceQuota
LimitRange 应用于单独的 Pod, ResourceQuota 应用于命名空间中所有的 Pod。
ResourceQuota 用于对单个命名空间的资源消耗总量进行限制,可以限制命名空间中特定资源使用 (例如 CPU, 内存) 的总上限。
注意: 当使用 ResourceQuota 为特定资源配置了资源请求量 requests 或 资源限制量 limits 时,在 Pod 中必须为资源指定 requests 和 limits, 否则 API 服务器将拒绝 Pod 的创建。
调度相关
调度器在调度时只考虑节点上面未分配资源量是否可以满足 Pod 的资源请求量。
如果节点的未分配资源量小于 Pod 请求量,调度器不会将 pod 调度到这个节点。
调度器并不关注节点上面资源在当前时间的实际使用量,而只关心节点上面部署的所有 Pod 的声明式资源请求量之和, 即使已部署的 Pod 资源实际使用量远远小于请求量,也不会使用基于实际使用量作为调度算法的计算指标参数, 因为这样会破坏 Kubernetes 为已部署的 Pod 提供的资源足够的声明式保证。
最佳实践
单独为每个容器设置 requests 和 limits。
通过容器在监控中的各项指标,结合业务场景估算出 CPU 和内存的 最小使用量 (min) 和 最大使用量 (max), 最小使用量指标的意义在于, 避免实际资源使用量远远高于资源请求量,导致 Pod 更有可能从节点被驱逐。
这里有个工具,可以根据历史 Prometheus 的监控数据给出 CPU 和内存资源请求量的建议。
CPU 密集型
- requests: 直接使用 CPU 和内存的最小使用量 (min),避免资源不足时导致的性能下降、或者引发 Pod 数量的自动扩容
- limits: 直接使用 CPU 和内存的最大使用量 (max)
IO 密集型
大多数互联网应用都属于 IO 密集型场景。
requests
- CPU : 保持在较低水平 ( <= 1 )
- 内存 : 直接使用内存的最小使用量 (min)
这样可以使 Pod 有更多机会被调度,同时,面对突发性的负载,容器可以使用限制之内的所有闲置 CPU 资源。
limits
- CPU : 直接使用 CPU 和内存的最大使用量 (max)
- 内存 : 直接使用内存的最大使用量 (max)
这样即使出现突发性的负载,CPU 和内存也不会超出限制使用。
不同的观点
这里有篇文章 和笔者的观点不同,感兴趣的读者可以看看。
潜在问题
将 CPU 的资源限制量 limits 设置为 1, 并不是说主机只会暴露 1 个固定的 CPU 给容器使用, 也就是说容器可以访问宿主机的所有 CPU, 并且使用它们来执行任务, 容器本身并不会对 CPU 进行虚拟化。以 Docker 为例来说,Docker 使用 cgroups 来管理和限制 CPU 使用,确保单个容器使用 CPU 资源量不超过对应的限制 (通过 –cpus, –cpu-shares 参数指定的)。
CPU limits 限制的只是容器使用 CPU 的时间片,假设一个 limits = 1 的容器运行在一个 64 核的节点上,容器进行并不是运行在一个固定的 CPU 核上面, 不同的时间点,容器依然会运行在不同的 CPU 核上面,但是使用的 CPU 总时间最多不会超过总的 CPU 资源 (64 核) 的 1/64, 也就是 1 个 CPU 核。
64 核 * 1/64 = 1 核
单纯从资源利用的角度来看,CPU 的这种使用方式非常高效,也满足资源的声明式保证,但是如果应用本身强依赖具体的运行环境,可能就可能产生很多问题,例如之前的文章中提到的 Go 线程数量问题。
