Kubernetes - kube-proxy 代理模式工程优化
2023-10-23 Cloud Native Kubernetes
概述
kube-proxy 是集群中运行在每个工作节点 (Node) 上面的网络代理,通过维护网络转发规则 (iptables, ipvs),将流量分发到对应的 Pod 中, 是实现 Service 功能 ClusterIP (虚拟 IP) 的重要组件。
kube-proxy 会通过 API Server 的通知消息来检测 Service 和 EndPoint 的变化,然后改变节点上的网络转发规则 (iptables, ipvs), kube-proxy 可以根据 EndPoint 的数据作为流量转发规则的指定依据。也就是说,kube-proxy 并不会直接就接收进入 Node 的流量, 而是会创建相应的 iptables 规则,将流量转发到 Service 对应的 Pod 中。
代理模式
下面着重介绍下 kube-proxy 内部实现的工程优化历史过程。
userspace
userspace 是 Kubernetes 早期的默认代理模式,这里简单提一下。
在这种模式中,对于每个 Service, kube-proxy 会在节点上随机选择一个端口作为 “代理端口”,然后新建 iptables 规则,将 Service 对应的 ClusterIP (虚拟 IP) + Port 重定向到 “代理端口”, 这样一来,任何发送到 Service 的请求都会被转发到 “代理端口”,最后转发到 Service 对应的 Pod 中。
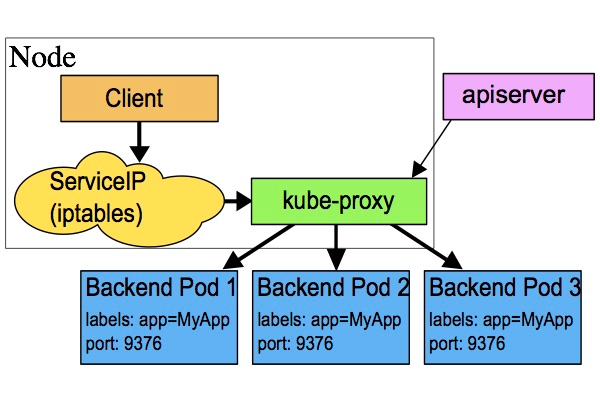
userspace 模式已经不再推荐使用,因为其存在显而易见的 性能问题: userspace 模式通过在用户空间中处理网络数据包来实现负载均衡和流量转发,这会引发用户态到内核态的上下文切换和数据拷贝。
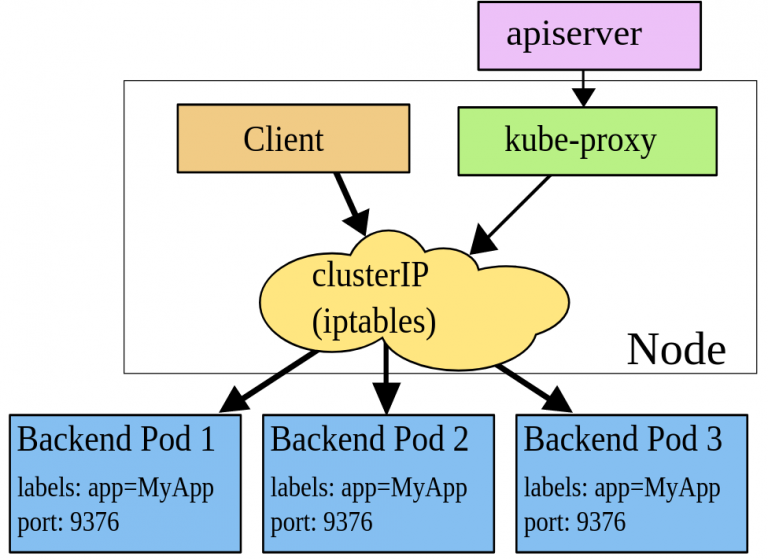
iptables
创建一个 Service 时会得到一个对应的 ClusterIP (虚拟 IP),然后 API Server 通过所有工作节点 (Node) 上运行的 kube-proxy 组件, 为新创建的 Service 建立对应的 iptables 规则,确保任何发送到 Service 的请求被正确解析并转发到对应的 Pod 中。
在这种模式中,对于每个 Service, kube-proxy 会新建 iptables 规则,将 Service 对应的 ClusterIP (虚拟 IP) + Port 重定向到 Service 对应的 Pod, 这样一下,任何发送到 Service 的请求都会被转发到 Service 对应的 Pod 中。
优化参数
| 字段 | 描述 |
|---|---|
| syncPeriod | iptables 规则的刷新周期 (例如,‘5s’、‘1m’、‘2h22m’) |
| minSyncPeriod | iptables 规则被刷新的最小周期 (例如,‘5s’、‘1m’、‘2h22m’) |
Kubernetes v1.28 版本开始,kube-proxy 的 iptables 模式采用了更精确的方法,只有在 Service 或 EndpointSlice 的值真正发生变化时才会进行更新。
相比于 userspace 模式,iptables 模式运行在内核态,所以性能要高出一个数量级,但是当集群中的节点数量较大时,iptables 也会遇到性能瓶颈, 因此这种模式只适用于小规模集群。
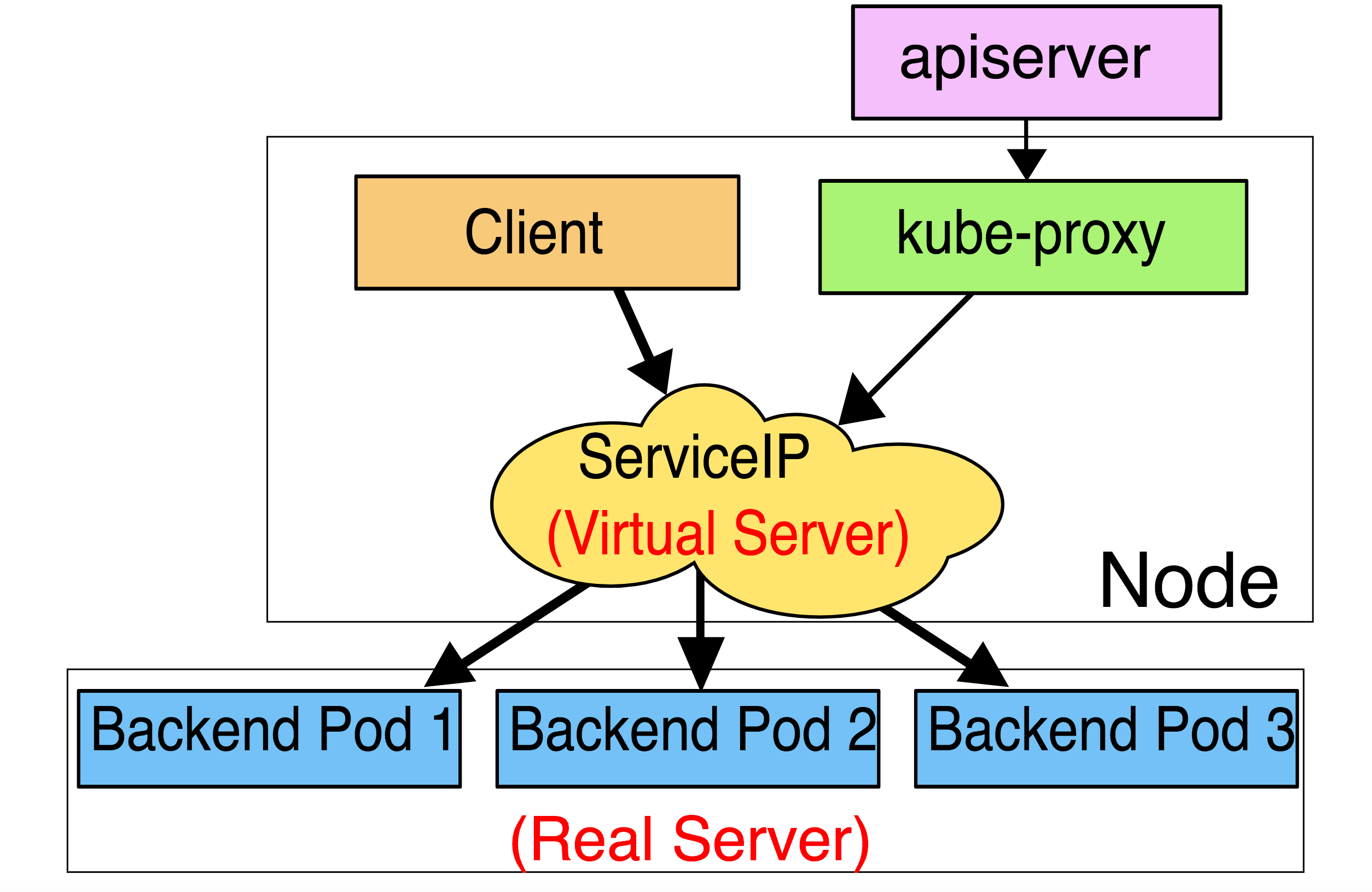
ipvs
在这种模式中,转发规则的维护过程、流量转发的过程和 iptables 模式类似,ipvs 虽然也是基于 netfilter 钩子函数实现并且工作在内核态,但是它使用哈希表作为底层数据结构, 所以性能要优于 iptables。
此外,ipvs 提供了更多的负载均衡算法选项:
rr 轮询调度
lc 最小连接数
dh 目标哈希
sh 源哈希
sed 最短期望延迟
nq 不排队调度
注意: ipvs 模式假定节点上已经安装了 ipvs 内核模块,当 kube-proxy 以 ipvs 代理模式启动时,如果节点未安装 ipvs 内核模块,则回退到 iptables 模式。
ipvs 为什么优于 iptables
iptables 是一项 Linux 内核功能,目标是成为一个高效的防火墙,具有足够的灵活性来处理各种常见的数据包操作和过滤需求,但是其底层的链表数据结构的实现决定了, 每次添加或更新规则时需要遍历所有规则,最终控制平面时间复杂度为 O(N²), 数据平面时间复杂度为 O(N)。 根据社区统计,当集群中的 Service 数量超过 5000 个时,每增加一条 iptables 规则耗时将超过 10 分钟。
ipvs 是专门为负载平衡而设计的 Linux 内核功能,其底层数据结构为哈希表,时间复杂度为 O(1), 也就是说,大多数情况下其性能和集群规模无关 (回忆一下哈希表数据结构的最好情况和最坏情况)。
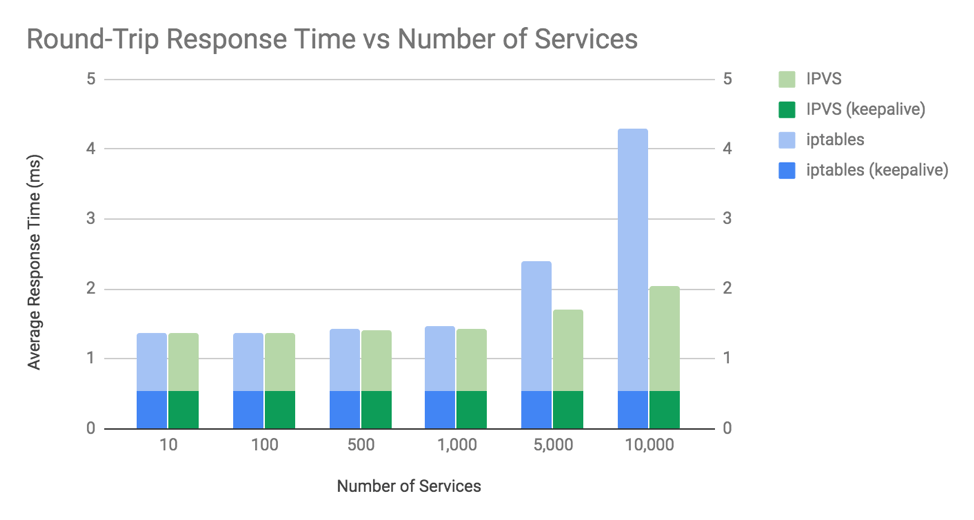
上图是针对 iptables 和 ipvs 模式进行的性能测试,从输出的图表结果来看,在 Service 数量不超过 1000 个时,两者之间的性能差异很小。
美中不足
虽然 ipvs 的性能要优于 iptables, 但是 ipvs 只负责负载均衡和流量转发功能,而一个完整的 Service 功能还包括数据包过滤、SNAT 等操作,这部分功能依然需要配合 iptables 来实现。 如果希望获得更强悍的性能,就需要从这个角度入手了,例如 扩展阅读第二篇文章 中提到的优化方法。
Reference
- Comparing kube-proxy modes: iptables or IPVS?
- Kubernetes: Service, load balancing, kube-proxy, and iptables
- 虚拟 IP 和服务代理
