Kubernetes Networking Model & CNI
2024-01-12 Cloud Native Kubernetes 计算机网络
概述
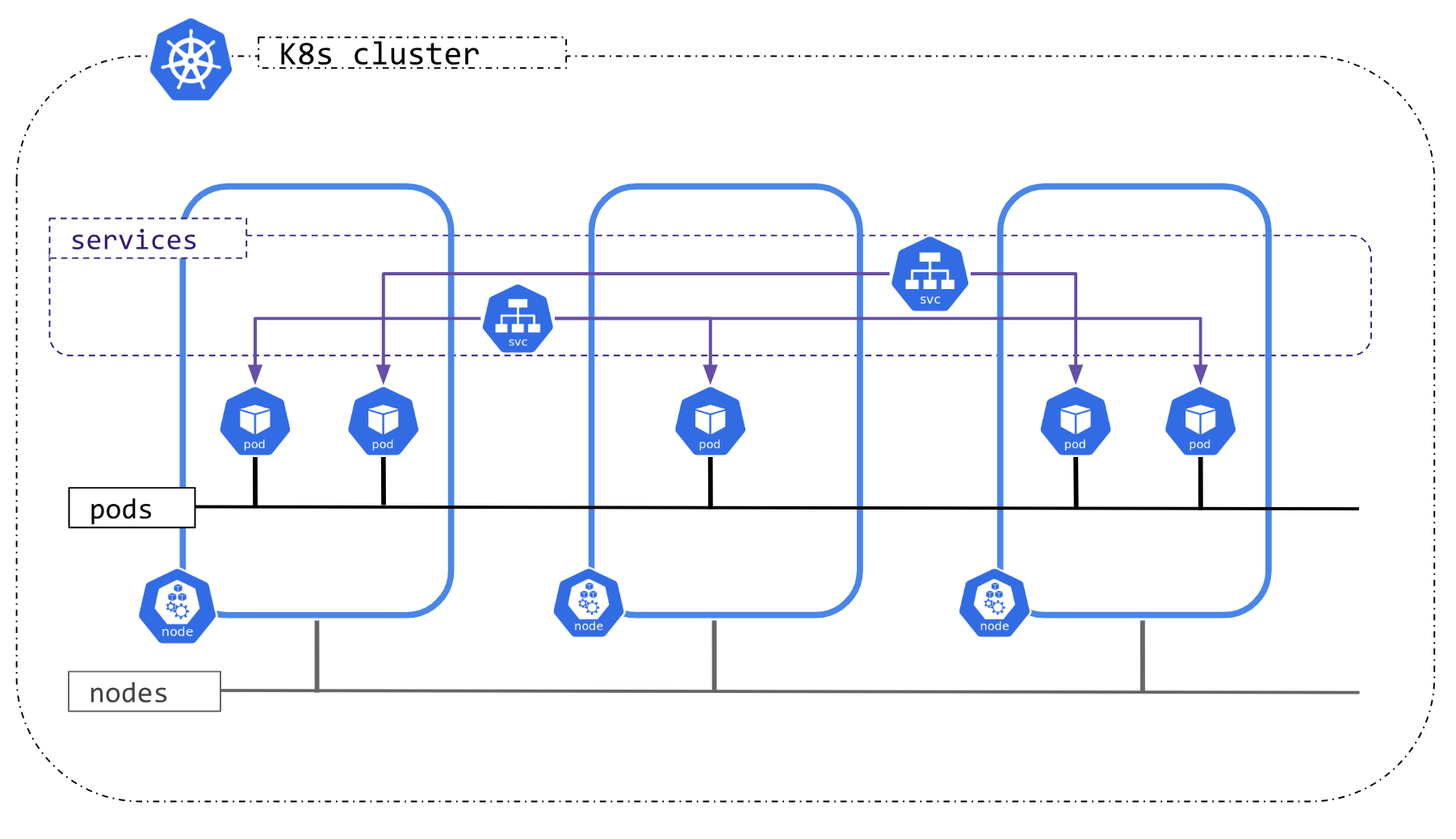
Kubernetes 提出了一个简单且简洁的网络模型: “IP - per - Pod”, 可以很好地满足集群中跨主机通信和从传统虚拟机向容器云原生平滑迁移的功能需求。 根据 Kubernetes 的网络模型语义设计,每一个 Pod 可以被认为是一个物理机或虚拟机。
模型语义
- 集群中每个 Pod 都有独立的一个 IP 地址
- 每个 Pod 中的所有容器共享该 Pod 的 IP 地址,每个容器通过 localhost + 端口 访问其他容器 (所以这也就是为什么 Pod 内部容器端口会冲突的原因)
- 集群中任意两个 Pod 可以直接通信,而且无需 NAT (网络地址转换)
- 每个 Node 上的代理(例如: 系统守护进程、kubelet)可以和该 Node 上的所有 Pod 直接通信
- 集群中的所有 Pod 都处于同一 IP 网段
模型网络问题
要实现上述的网络模型语义,Kubernetes 要解决 4 个方面的问题:
- 每个 Pod 中的所有容器直接通信 (通过每个 Pod 内部的 Pause 容器实现)
- Pod 和 Pod 通信 (通过 CNI 接口插件解决,所有 Pod 处于一个没有 NAT 转换的扁平地址空间中,例如 172.16.0.0/24 网段中)
- Pod 和 Service 通信,通过为 Service 定义 Cluster IP (虚拟 IP), 然后在每个 Node 运行一个 kube-proxy 进程,该进程会编写对应的流量重定向规则 (例如 iptables, ipvs),将访问流量重定向到正确的 Pod 中
- 集群外部到内部的通信,典型的方式是通过集群外部的 LoadBalancer (负载均衡) 来实现的
IP 地址分配
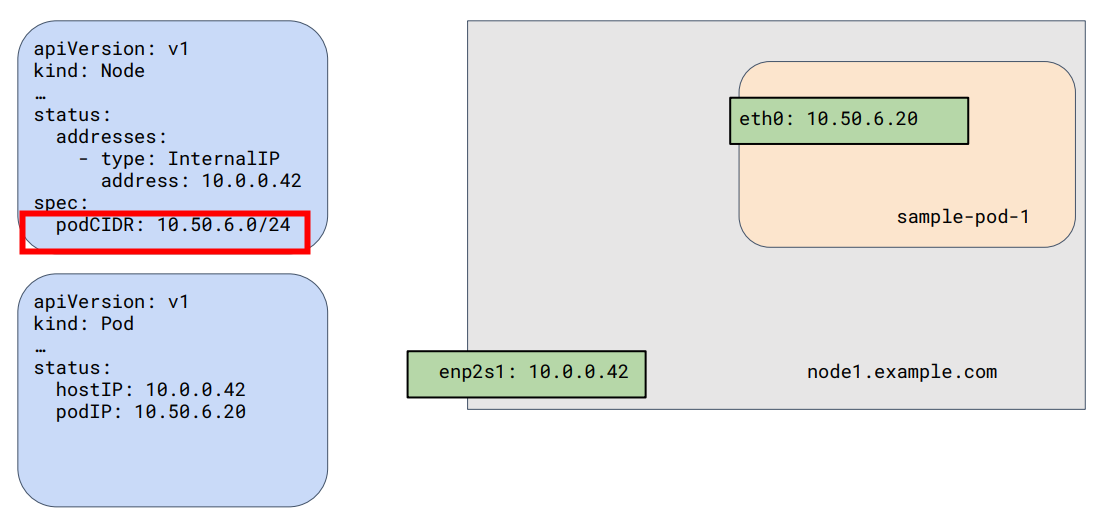
根据 Kubernetes 网络模型的语义,整个集群都处于同一 IP 网段,所以 Kubernetes 还定义了 CIDR(Classless Inter-Domain Routing)网络寻址方案,用于定义和划分 IP 地址范围。 每个集群都有一个 CIDR 地址范围,通过指定一个 IP 地址和子网掩码来定义的,例如 10.0.0.0/16 表示一个 CIDR 范围,其中 10.0.0.0 是起始 IP 地址,/16 表示使用了 16 位的子网掩码。
通过 CIDR 地址范围,Kubernetes 可以管理集群中需要 IP 地址的所有对象资源,具体来说:
- CNI (容器网络接口) 为 Pod 分配 IP 地址
- kube-apiserver 为 Service 分配 IP 地址
- kubelet 或 cloud-controller-manager 为 Node 分配 IP 地址
下面展示一个 CIDR 为 10.50.6.0/24 的 Node 和一个 IP 为 10.50.6.20 的 Pod。
CNI
如何实现上文中提到的 Kubernetes 网络模型中和 Pod 相关的部分呢?
最常见的方式是 CRI (容器运行时接口) 使用 CNI (容器网络接口) 插件来管理其网络和安全能力, CNI 定义了一系列协议接口,用来管理网络插件,开发者只需实现接口就可以接入 Kubernetes 网络管理能力,实现为 Pod 创建虚拟网卡、为 Pod 分配 IP 地址等网络功能,实现 “IP - per - Pod” 网络模型。

根据接口的定义可以看到,CNI 的主要工作是从 CRI 获取容器运行时相关信息,再从容器网络配置文件中获取配置信息,然后将信息传递给对应的插件,由插件执行具体的配置工作并将结果返回到 CRI。
为什么需要 CNI ?
容器和容器网络方案都在不断更新和发展当中,同时还有新的开源方案不断涌现,如果每出现新的容器网络方案时,都需要将其和已有容器兼容适配,那么必然存在大量的重复和无必要工作, 这时候就需要一个标准化的协议接口,用来约束不断发展衍生的容器网络方案,不管后者如何变化,只要其实现并满足 CNI 接口,也就可以兼容已有的所有容器。
CNI 网络类型
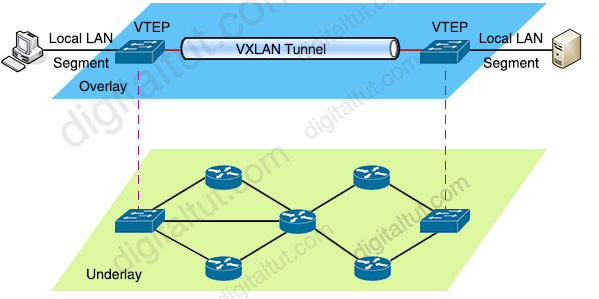
Overlay
构建在另一个真实的计算机网络上面的 “虚拟网络”,在数据包的传输过程中,发送方的底层网络会进行封包操作,接收方的底层网络会进行拆包操作,当然,这些操作对通信双方来说都是透明的。
Overlay 网络的优点在于对网络环境没有特殊要求,利用底层网络组成 “虚拟网络” 有很好的适配性,缺点是封包和拆包会带来额外的开销,所以性能较低。
Route
基于路由的容器网络类型,不会创建任何 “虚拟网络” 或桥接设备,而是直接在底层网络配置容器的路由规则。Route 网络类型利用操作系统的网络命名空间和路由表功能, 为每个容器创建一个独立的网络命名空间,使容器可以直接访问节点上的其他容器,也可以通过路由表转发到其他节点的容器。
Route 优点是不存在封包和拆包会带来额外的开销,性能比 Overlay 模式要高,缺点是是依赖于底层网络。
Underlay
直接使用底层网络技术 (物理网络或虚拟化基础设施的网络) 来实现 CNI, 也就是说 Pod 和宿主机都处于同一个网络中,两者之间是平等的,优点是性能很高,缺点是依赖于底层网络和基础设施。
CNI 功能组件分类
CNI 插件可以分类以下三种类型,每种插件负责完成不同的工作。
IPAM (IP address allocation)
负责为 Pod 分配 IP 地址,支持以下分配方式:
- DHCP : 发起 DHCP 协议请求为容器申请 IP 地址
- host-local: 在本地维护已分配的 IP 数据库,使用预先配置的 IP 地址段来进行分配
- static: 申请静态 IP 地址
Meta: other plugins
由 CNI 社区维护的内置 CNI 插件,不能作为独立的插件使用,需要调用其他插件。
- tuning: 基于 sysctl 调整网络设备参数的二进制文件
- portmap: 基于 iptables 配置端口映射的二进制文件,将端口从主机地址空间映射到容器
- bandwidth: 基于 Token Bucket Filter (TBF) 来进行限流的二进制文件
- firewall: 防火墙插件,使用 iptables 或 firewalld 添加规则来管理容器的出入流量
Main: interface-creating
负责创建具体网络设备的二进制文件,支持创建如下类型的设备:
- bridge: 创建一个网桥,向其中添加主机和容器 (例如 Flannel 创建的名称为 cni0, 类似 Docker 创建的 docker0 虚拟网桥)
- ipvlan: 向容器中添加 ipvlan 接口
- loopback: 设置本地虚拟环回设备 (通常指 127.0.0.1)
- macvlan: 创建一个 MAC 地址,将所有流量转发到容器
- ptp: 创建一对 veth pair
- vlan: 分配 vlan 设备
- host-device: 将已有设备移动到容器中
- dummy: 在容器中创建一个新的虚拟设备
CNI 开源实现
开源社区主流的 CNI 实现包括:Flannel、Calico、Weave、Cilium 等,每个插件都有不同的网络拓扑和特性,选择时需要考虑集群的资源需求和运维限制。
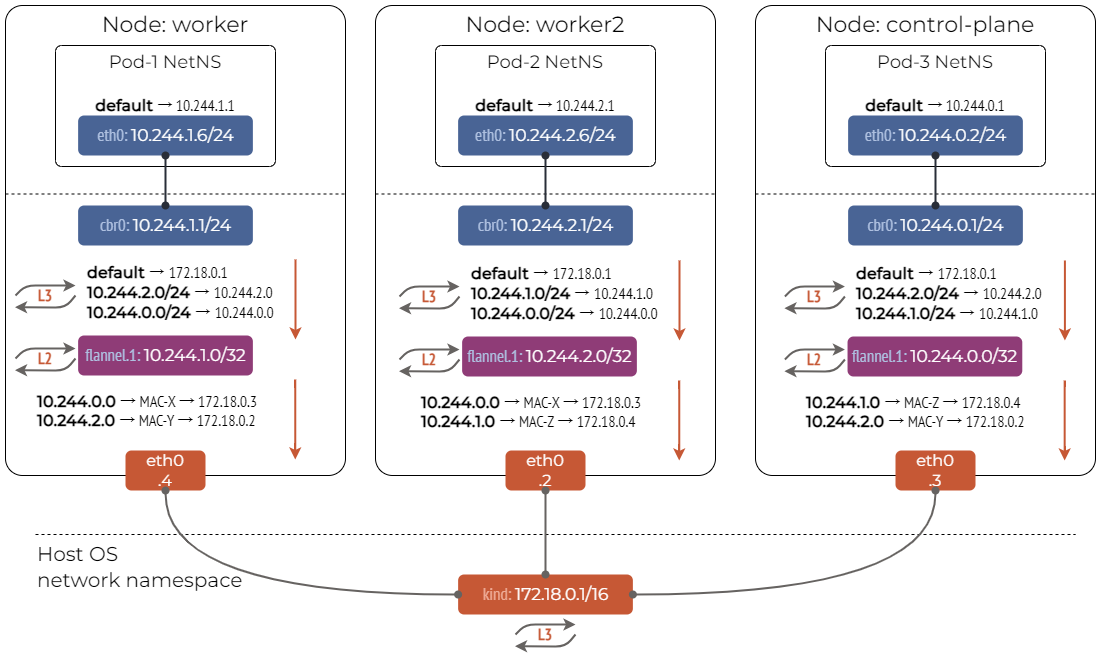
Flannel
Flannel 简单易用,是 Kubernetes 里最流行的 CNI 插件,通过 VXLAN (也可以通过 UDP 替换) 实现了 Overlay 网络模式,通过 Host-Gateway 实现了 Route 网络模式。 Flannel 仅控制流量如何在各个主机之间传输,且性能要低于 Calico 和 Cilium。
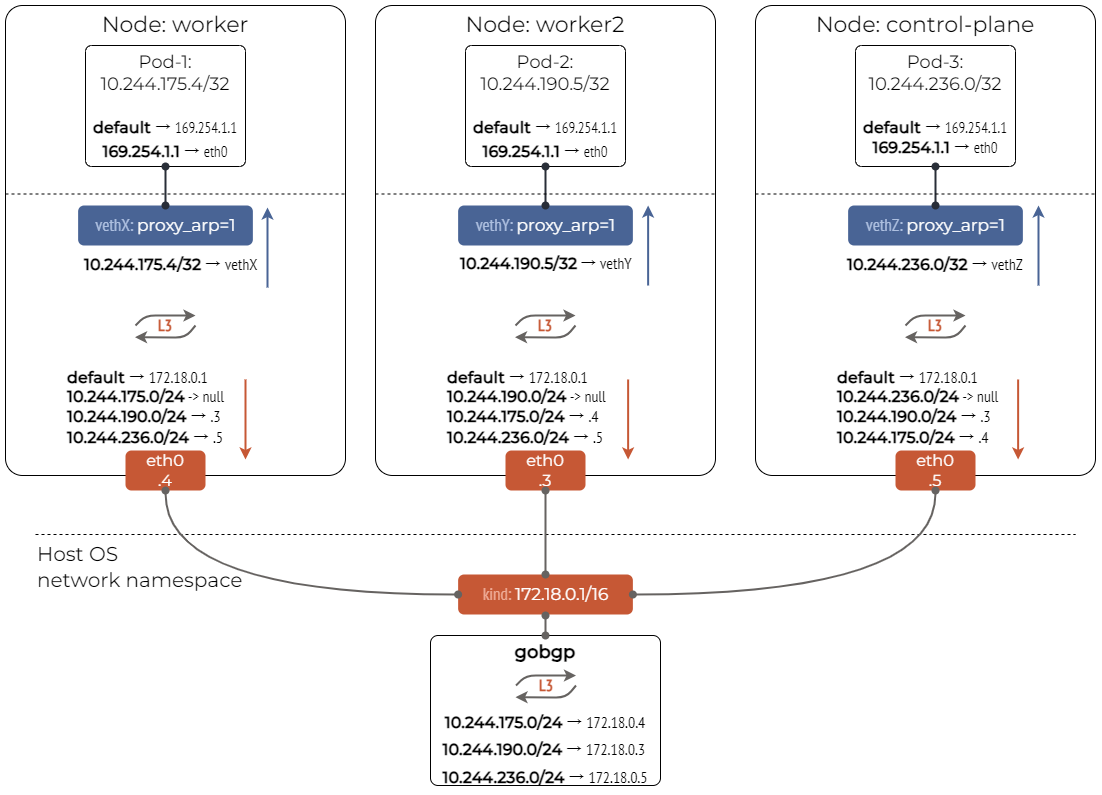
Calico
Calico 是一个基于 BGP 的纯三层的数据中心网络方案,实现了 Route 网络模式 (不需要 Overlay),支持多种网络策略,kube-proxy 替换、网络安全策略、网络流量可观测性等功能。
实现方式: 通过创建 veth 链接并将该链接的一侧连接到 Pod 的命名空间中,另一侧连接到节点的根命名空间中 (例如 bridge)。这样对于节点的每个 Pod,Calico 都会针对 Pod IP 设置一条指向 veth 链路的路由。
Cilium
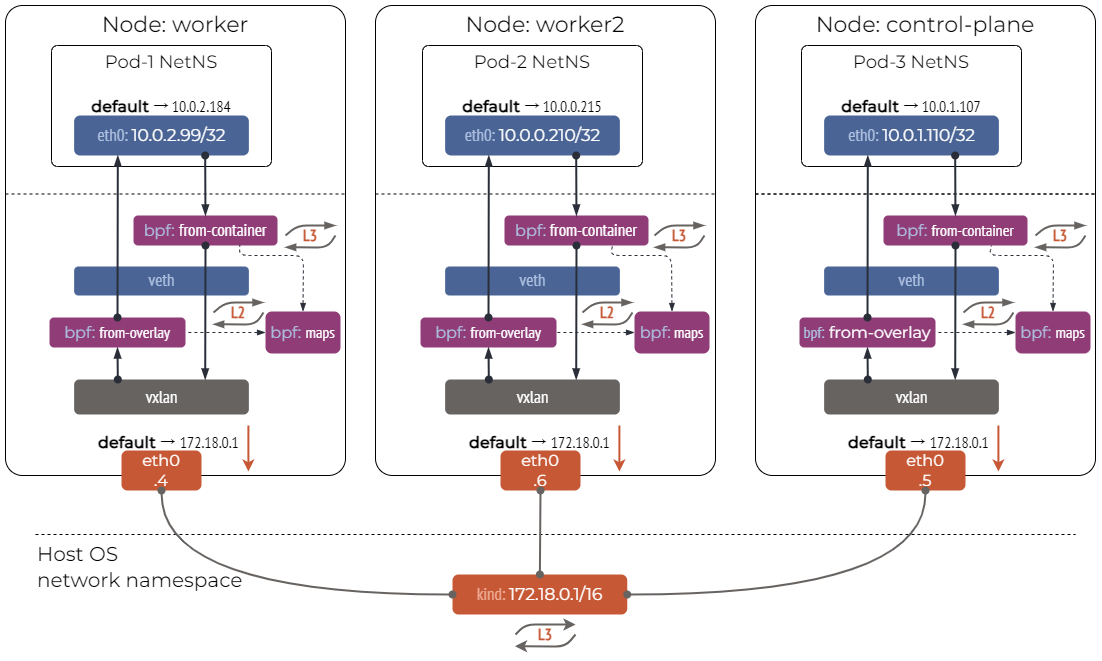
Cilium 是性能最高的 CNI 插件,通过使用 Linux eBPF 直接在内核操作网络数据,可以灵活实现各种功能,同时支持 Overlay 网络模式和 Route 网络模式。
Cilium 可以实现基于各种网络策略的流量过滤、CNI、kube-proxy 替换等功能,相比其他功能,CNI 反而是 Cilium 最不重要的功能。
实现方式: 通过创建 veth 链接并将该链接的一侧连接到 Pod 的命名空间中,另一侧连接到位于节点的根命名空间中 (例如 bridge)。Cilium 将 eBPF 程序附加到这些链路的入口 TC 钩子函数,以拦截所有传入的数据包并进行处理, 大部分网络连接和转发是在 eBPF 程序内执行的。
Reference
- Kubernetes Networking
- Container Network Interface (CNI) Specification
- CNI - the Container Network Interface
- Plugins
