Kubernetes HPA 设计与实现
2023-12-31 Cloud Native Kubernetes 读代码
概述
水平自动伸缩 (Horizontal Pod AutoScale) 简称 HPA, 目标是自动伸缩 Pod 的副本数量来满足应用服务负载。
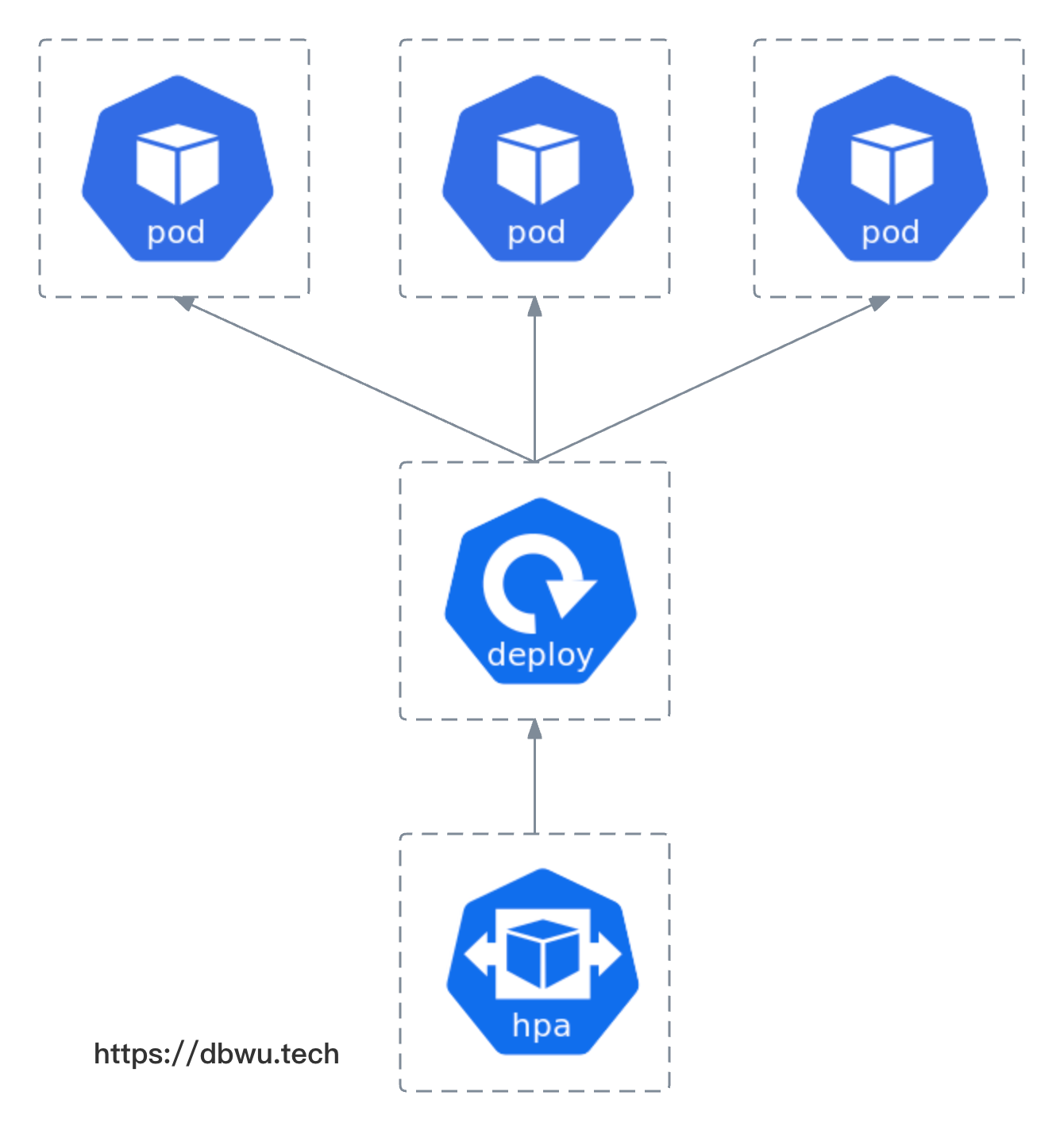
HPA 的使用方法和最佳实践在 这篇文章 中已经介绍过了,本文不再赘述,本文着重从源代码的角度分析一下 HPA 的实现原理。
HPA 功能对应的源代码位于 Kubernetes 项目的 pkg/controller/podautoscaler/ 目录,本文以 Kubernetes v1.28 版本源代码进行分析。
流程图
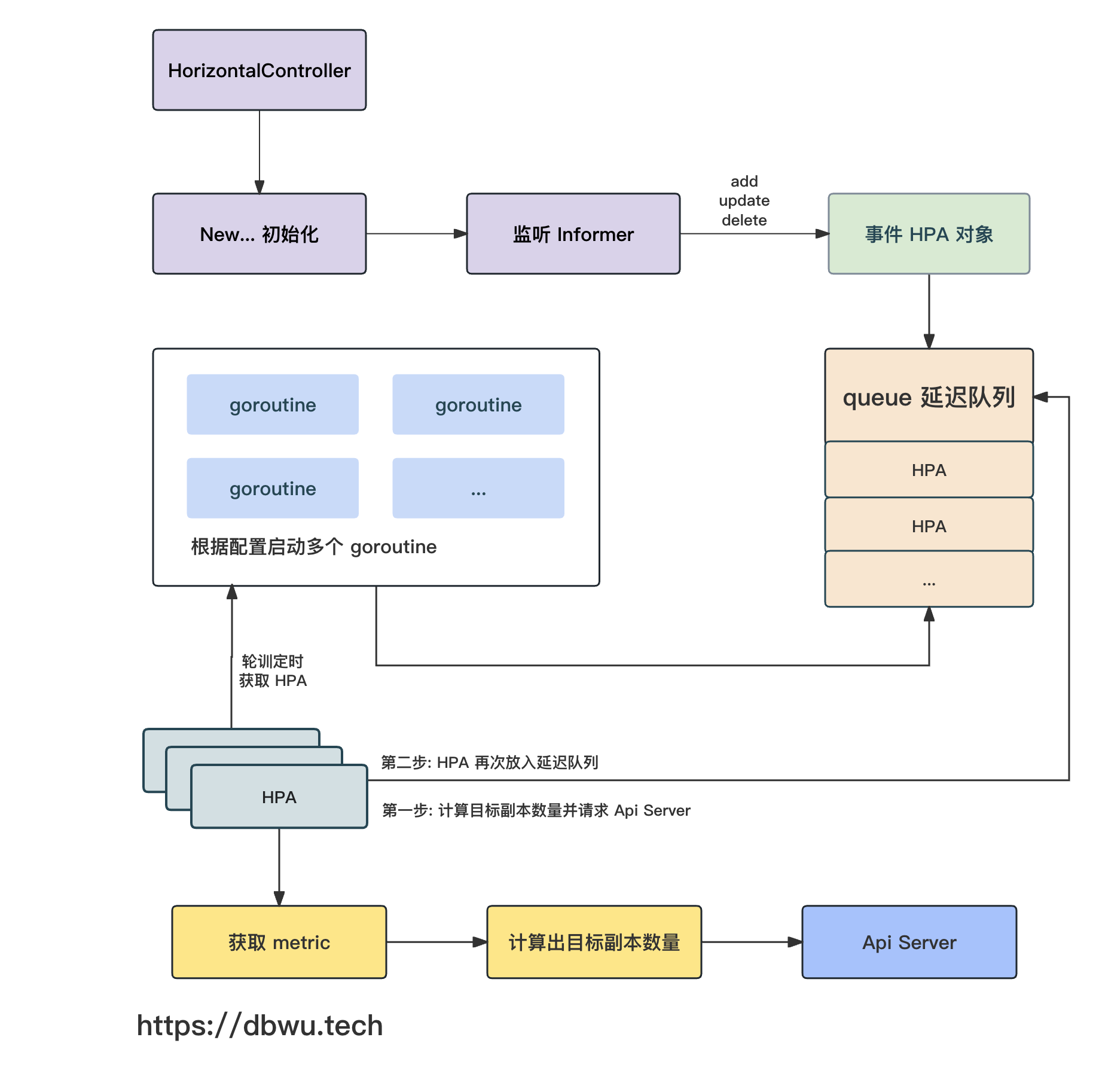
下面我们跟着流程图一起看下源代码的具体实现。
HorizontalController
首先来看看 HorizontalController 控制器对象,该对象是实现 HPA 功能的核心对象。
// HorizontalController 控制器负责将 Pod 的状态调整到对应的 HPA 期望状态
type HorizontalController struct {
...
// HPA 配置对象列表
hpaLister autoscalinglisters.HorizontalPodAutoscalerLister
hpaListerSynced cache.InformerSynced
// Pod 列表
podLister corelisters.PodLister
podListerSynced cache.InformerSynced
// HPA 对象延迟队列
// 如何理解这个延迟队列?
// 本质上就是内部除了队列数据结构外,还有一个专门的根据时间排序的 {最小堆} 数据结构
// 然后启动一个专门的 goroutine, 监听到期的对象并直接放入队列
// 队列中存储发生了变化的控制器
queue workqueue.RateLimitingInterface
...
}
配置信息
HPAControllerConfiguration 对象表示 HorizontalController 控制器的配置对象。
type HPAControllerConfiguration struct {
...
}
RecommendedDefaultHPAControllerConfiguration 方法用于设置配置对象的默认值。
func RecommendedDefaultHPAControllerConfiguration(obj *kubectrlmgrconfigv1alpha1.HPAControllerConfiguration) {
zero := metav1.Duration{}
// 用于并发处理 HPA 逻辑的 goroutine 数量
// 默认为 5 个
if obj.ConcurrentHorizontalPodAutoscalerSyncs == 0 {
obj.ConcurrentHorizontalPodAutoscalerSyncs = 5
}
// 控制器队列 - 延迟入队时间
// 默认为 15 秒
if obj.HorizontalPodAutoscalerSyncPeriod == zero {
obj.HorizontalPodAutoscalerSyncPeriod = metav1.Duration{Duration: 15 * time.Second}
}
// 两次扩容的间隔时间
// 默认为 3 分钟
if obj.HorizontalPodAutoscalerUpscaleForbiddenWindow == zero {
obj.HorizontalPodAutoscalerUpscaleForbiddenWindow = metav1.Duration{Duration: 3 * time.Minute}
}
// 两次缩容的间隔时间
// 默认为 5 分钟
if obj.HorizontalPodAutoscalerDownscaleStabilizationWindow == zero {
obj.HorizontalPodAutoscalerDownscaleStabilizationWindow = metav1.Duration{Duration: 5 * time.Minute}
}
...
}
初始化
NewHorizontalController 方法用于 HorizontalController 控制器对象的初始化工作,并返回一个实例化对象。
func NewHorizontalController(...) *HorizontalController {
...
hpaController := &HorizontalController{
queue: workqueue.NewNamedRateLimitingQueue(NewDefaultHPARateLimiter(resyncPeriod), "horizontalpodautoscaler"),
}
// 增加 informer 监听事件
hpaInformer.Informer().AddEventHandlerWithResyncPeriod(
cache.ResourceEventHandlerFuncs{
// 新增 HPA 回调方法
AddFunc: hpaController.enqueueHPA,
// 修改 HPA 回调方法
UpdateFunc: hpaController.updateHPA,
// 删除 HPA 回调方法
DeleteFunc: hpaController.deleteHPA,
},
// 监听事件的定时周期
resyncPeriod,
)
...
// 创建一个新的副本计算器
// 这样就可以计算出 Pod 的目标数量,然后在此基础上扩容或者缩容
replicaCalc := NewReplicaCalculator(
...
)
hpaController.replicaCalc = replicaCalc
...
return hpaController
}
注册事件通知
初始化 HorizontalController 控制器对象时会注册 informer 监听事件,后续当对应的事件被触发时,就会执行的对应的事件回调方法。
新增 HPA 回调
func (a *HorizontalController) enqueueHPA(obj interface{}) {
...
}
修改 HPA 回调
func (a *HorizontalController) updateHPA(old, cur interface{}) {
...
}
删除 HPA 回调
func (a *HorizontalController) deleteHPA(obj interface{}) {
...
}
启动 HPA
NewHorizontalController 方法返回对象示例之后,立即调用对象的 Run 方法开始运行自动伸缩的逻辑。
// cmd/kube-controller-manager/app/autoscaling.go
func startHPAControllerWithMetricsClient(ctx context.Context, ...) (controller.Interface, bool, error) {
...
// 启动一个独立的 goroutine 来完成 {初始化 && 运行}
go podautoscaler.NewHorizontalController(
...
).Run(ctx, int(controllerContext.ComponentConfig.HPAController.ConcurrentHorizontalPodAutoscalerSyncs))
...
}
HorizontalController.Run 方法执行具体的自动伸缩操作。
func (a *HorizontalController) Run(ctx context.Context, workers int) {
...
// (根据配置) 启动多个 goroutine 处理逻辑
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, a.worker, time.Second)
}
...
}
HorizontalController.worker 方法本质上就是一个无限循环轮询器,通过定时检测所有资源使用率,并进行对应的扩容|缩容操作。
func (a *HorizontalController) worker(ctx context.Context) {
for a.processNextWorkItem(ctx) {
}
}
func (a *HorizontalController) processNextWorkItem(ctx context.Context) bool {
// 从队列中取出一个 HPA 对象
key, quit := a.queue.Get()
...
// 实现扩容|缩容
// 这里调用了 reconcileKey 方法
deleted, err := a.reconcileKey(ctx, key.(string))
// HPA 对象再次放入队列,方便后续可以持续检测
if !deleted {
a.queue.AddRateLimited(key)
}
return true
}
HorizontalController.reconcileKey 方法,最后返回参数对应的 HPA 对象是否已经被删除。
func (a *HorizontalController) reconcileKey(ctx context.Context, key string) (deleted bool, err error) {
...
hpa, err := a.hpaLister.HorizontalPodAutoscalers(namespace).Get(name)
if k8serrors.IsNotFound(err) {
// 如果参数对应的 HPA 对象已经被删除了,返回 true
...
return true, nil
}
// 接下来,就可以进入扩容|缩容的主要逻辑
return false, a.reconcileAutoscaler(ctx, hpa, key)
}
计算副本数量
HorizontalController.reconcileAutoscaler 方法会根据当前副本数量和 HPA 对象中定义的期望副本数量计算出调整后的数量,并进行对应的扩容|缩容操作,
这是 HPA 中的核心方法。
func (a *HorizontalController) reconcileAutoscaler(ctx context.Context, ...) (...) {
...
// 初始化本次期望副本数量
desiredReplicas := int32(0)
// 初始化最小副本数量
var minReplicas int32
if hpa.Spec.MinReplicas != nil {
minReplicas = *hpa.Spec.MinReplicas
} else {
minReplicas = 1
}
// 是否需要扩容|缩容
rescale := true
// 如果当前副本数量为 0,关闭自动扩容
if currentReplicas == 0 && minReplicas != 0 {
desiredReplicas = 0
rescale = false
} else if currentReplicas > hpa.Spec.MaxReplicas {
// 如果当前副本数量 大于 HPA 配置的副本最大数量
// 设置本次期望副本数量为 HPA 配置的副本最大数量
desiredReplicas = hpa.Spec.MaxReplicas
} else if currentReplicas < minReplicas {
// 如果当前副本数量 小于 HPA 配置的副本最小数量
// 设置本次期望副本数量为 HPA 配置的副本最小数量
desiredReplicas = minReplicas
} else {
// 如果当前副本数量位于 {HPA 配置的副本最小数量 -> 最大数量} 区间内
// 根据 metric 计算期望的副本数量
metricDesiredReplicas, ... = a.computeReplicasForMetrics(ctx, ...)
...
// 根据计算出来的期望副本数量
// 再次对本次期望副本数量进行调整
rescaleMetric := ""
if metricDesiredReplicas > desiredReplicas {
desiredReplicas = metricDesiredReplicas
}
if hpa.Spec.Behavior == nil {
desiredReplicas = a.normalizeDesiredReplicas(hpa, key, currentReplicas, desiredReplicas, minReplicas)
} else {
desiredReplicas = a.normalizeDesiredReplicasWithBehaviors(hpa, key, currentReplicas, desiredReplicas, minReplicas)
}
// 如果当前副本数量不等于期望副本数量
// 标记本次需要扩容|缩容
rescale = desiredReplicas != currentReplicas
}
// 如果本次需要执行扩容|缩容操作
if rescale {
...
// 执行扩容|缩容操作
// 向 API Server 发送扩容|缩容请求
_, err = a.scaleNamespacer.Scales(hpa.Namespace).Update(ctx, ...)
...
}
...
}
根据 metric 计算期望的副本数量
HorizontalController.computeReplicasForMetrics 方法会根据 HPA 配置对象中的所有 metric 计算出需要的副本数量,
方法内部会遍历 HPA 配置对象的所有 metric, 然后以多个 metric 中的最大值为准,例如根据 CPU metric 计算出来的副本数量是 10 个,
根据内存 metric 计算出来的副本数量是 15 个,则最终返回的副本数量为 15 个。
func (a *HorizontalController) computeReplicasForMetrics(ctx context.Context, ...) (...) {
...
// 遍历 HAP 配置对象中的 metric (例如 CPU, 内存 等)
for i, metricSpec := range metricSpecs {
// 通过当前 metric 计算需要的副本数量
replicaCountProposal, ..., err := a.computeReplicasForMetric(ctx, ...)
...
// 如果通过当前 metric 计算出来的副本数量 大于 已有的副本数量
// 就以大的副本数量为准
if replicas == 0 || replicaCountProposal > replicas {
replicas = replicaCountProposal
}
}
...
return replicas, ...
}
HorizontalController.computeReplicasForMetric 方法会根据单个 metric 计算出需要的副本数量。
func (a *HorizontalController) computeReplicasForMetric(ctx context.Context, ...) (...) {
// 根据不同的 metric 类型执行不同的计算方式
switch spec.Type {
case autoscalingv2.ObjectMetricSourceType:
// 根据 Kubernetes 对象 metric 进行计算
...
case autoscalingv2.PodsMetricSourceType:
// 根据 Pod metric 进行计算
...
case autoscalingv2.ResourceMetricSourceType:
// 根据 Pod 资源 metric 进行计算
// 例如 CPU, 内存使用量
...
case autoscalingv2.ContainerResourceMetricSourceType:
// 根据 Pod 内容器资源 metric 进行计算
// 例如容器的 CPU, 内存使用量
case autoscalingv2.ExternalMetricSourceType:
// 根据外部 metric 进行计算
default:
// 无效的 metric 类型
...
}
return replicaCountProposal, ...
}
根据 Pod 资源 metric 计算副本数量
HorizontalController.computeStatusForResourceMetric 方法会根据 Pod 当前的资源使用量 (例如 CPU, 内存) 计算出需要的副本数量。
func (a *HorizontalController) computeStatusForResourceMetric(ctx context.Context, ...) (...) {
replicaCountProposal, ... := a.computeStatusForResourceMetricGeneric(ctx, ...)
...
return replicaCountProposal, ...
}
HorizontalController.computeStatusForResourceMetricGeneric 方法会根据当前副本数量和期望副本数量计算出一个合适的目标副本数量,
其内部最终调用的是 ReplicaCalculator.GetResourceReplicas 方法。
func (a *HorizontalController) computeStatusForResourceMetricGeneric(ctx context.Context, ...) (...) {
...
replicaCountProposal, ... := a.replicaCalc.GetResourceReplicas(ctx, ...)
...
return replicaCountProposal, ...
}
func (c *ReplicaCalculator) GetResourceReplicas(ctx context.Context, ...) (...) {
// 获取与指定选择器匹配的所有 Pod 的 metric 数据
metrics, ... := c.metricsClient.GetResourceMetric(ctx, ...)
// 获取 Pod 列表
podList, err := c.podLister.Pods(namespace).List(selector)
// 将 Pod 列表进行分组为
// [就绪列表,未就绪列表,未设置 metric 的列表,标记为删除的列表]
readyPodCount, unreadyPods, missingPods, ignoredPods := groupPods(podList, ...)
// 清除 {标记为删除的} Pod
removeMetricsForPods(metrics, ignoredPods)
// 清除未就绪的 Pod
removeMetricsForPods(metrics, unreadyPods)
// 获取每个 Pod 的资源请求配置信息
requests, err := calculatePodRequests(podList, container, resource)
// 获取 metric 对应的资源利用率
usageRatio, ... := metricsclient.GetResourceUtilizationRatio(metrics, ...)
// 扩容时是否需要考虑未就绪 Pod 的数量
scaleUpWithUnready := len(unreadyPods) > 0 && usageRatio > 1.0
// 如果没有未就绪的 Pod 列表并且 metric 资源的利用率没有超过负载 (1)
// 并且
// 不存在未设置 metric 的 Pod
// 那么就可以直接计算目标副本数量了
if !scaleUpWithUnready && len(missingPods) == 0 {
// Pod 目标副本数量 = ceil(metric 资源利用率 * 已就绪 Pod 数量)
// 举几个例子:
// 1. 扩容: 当前已就绪 Pod 数量为 10, 资源利用率为 1.5, Pod 目标副本数量 = 15
// 2. 缩容: 当前已就绪 Pod 数量为 10, 资源利用率为 0.8, Pod 目标副本数量 = 8
// 3. 不变: 当前已就绪 Pod 数量为 10, 资源利用率为 1, Pod 目标副本数量 = 10
return int32(math.Ceil(usageRatio * float64(readyPodCount))), ...
}
// 如果存在未设置 metric 的 Pod
if len(missingPods) > 0 {
// 如果资源利用率没有达到 1 (负载不严重)
if usageRatio < 1.0 {
// 缩容模式
// 直接假设 Pod 的 metric 资源利用为 100%
// 如果资源利用目标高于 100%,就以目标利用为准
fallbackUtilization := int64(max(100, targetUtilization))
for podName := range missingPods {
metrics[podName] = metricsclient.PodMetric{Value: requests[podName] * fallbackUtilization / 100}
}
} else if usageRatio > 1.0 {
// 扩容模式
// 直接假设 Pod 的 metric 资源利用为 0%
for podName := range missingPods {
metrics[podName] = metricsclient.PodMetric{Value: 0}
}
}
}
// 如果扩容时是否需要考虑未就绪 Pod 的数量
if scaleUpWithUnready {
// 直接将未就绪的 Pod 的 metric 资源利用为 0%
for podName := range unreadyPods {
metrics[podName] = metricsclient.PodMetric{Value: 0}
}
}
// 因为上面更新了一些 Pod 的 metric
// 所以这里需要重新计算一下资源利用率
newUsageRatio, ... := metricsclient.GetResourceUtilizationRatio(metrics, ...)
if math.Abs(1.0-newUsageRatio) <= c.tolerance || (usageRatio < 1.0 && newUsageRatio > 1.0) || (usageRatio > 1.0 && newUsageRatio < 1.0) {
// 如果重新计算后的资源利用率不高
// 或者
// 重新计算后的资源利用率会引起逆向伸缩操作 (扩容 -> 缩容,缩容 -> 扩容)
// 那么直接返回当前副本数量即可
return currentReplicas, ...
}
// Pod 目标副本数量 = ceil(metric 资源利用率 * metric 个数)
newReplicas := int32(math.Ceil(newUsageRatio * float64(len(metrics))))
if (newUsageRatio < 1.0 && newReplicas > currentReplicas) || (newUsageRatio > 1.0 && newReplicas < currentReplicas) {
// 如果重新计算后的资源利用率不高
// 或者
// 重新计算后的资源利用率会引起逆向伸缩操作 (扩容 -> 缩容,缩容 -> 扩容)
// 那么直接返回当前副本数量即可
return currentReplicas, ...
}
return newReplicas, ...
}
计算资源利用率
在 ReplicaCalculator.GetResourceReplicas 方法内部,调用了两次 GetResourceUtilizationRatio 方法来获取 metric 的资源使用率。
func GetResourceUtilizationRatio(metrics PodMetricsInfo, ...) (...) {
metricsTotal := int64(0)
requestsTotal := int64(0)
numEntries := 0
// 计算所有 Pod 的 metric 总值和 request 总值
for podName, metric := range metrics {
request, hasRequest := requests[podName]
metricsTotal += metric.Value
requestsTotal += request
numEntries++
}
// 计算资源利用率
// 资源利用率 = metric 总值 * 100 / request 总值
// 例如 内存 request 为 1 GB, 但是 metric (实际使用量) 为 4 GB, 那么资源使用率 = 200%
currentUtilization = int32((metricsTotal * 100) / requestsTotal)
return ...
}
后续操作
计算出目标副本数量后,HPA 控制器 会向 API Server 发送关联 Deployment 对应的扩容|缩容操作请求,然后 Deployment 控制器会通过接收 informer 监听事件,
触发执行对应的操作。篇幅所限,这部分源代码内容本文不做分析,感兴趣的读者可以参考 Deployment实现原理。
小结
自动伸缩过程中,Pod 的期望 (目标) 副本数量的计算公式为:
Pod 期望副本数 = ceil[Pod 当前副本数 * (当前指标 / 期望指标)]
假设使用 CPU 使用量作为自动伸缩的度量指标,如果当前 CPU 的使用量指标为 200m, 期望指标为 100m, 当前副本数量为 5,则副本数量等于:
ceil [5 * (200m / 100m)] = 10
如果当前 CPU 的使用量指标为 50m, 期望指标为 100m, 当前副本数量为 10,则副本数量等于:
ceil [10 * (50m / 100m)] = 5
源代码计算公式
根据前文中的源代码分析可以看到,Kubernetes 将上述公式分为两步计算,第一步先调用 GetResourceUtilizationRatio 方法计算出资源利用率 usageRatio;
资源利用率 = 当前指标 / 期望指标
然后第二步根据资源利用率求出 Pod 的期望副本数量。
Pod 期望副本数 = ceil[Pod 当前副本数 * 资源利用率]
if !scaleUpWithUnready && len(missingPods) == 0 {
// 1. 计算出资源利用率
// 2. 计算 Pod 期望副本数量
return int32(math.Ceil(usageRatio * float64(readyPodCount))), ...
}
HPA 控制器执行流程图
