Kubernetes Pod 驱逐 - 设计与实现
2023-12-21 Cloud Native Kubernetes 读代码
概述
kubelet 是每个工作节点上运行的 “代理”,本质上就是一个运行的进程,通过和 API Server 进行通信并进行节点的一系列资源管理,例如常见的管理功能如下。
- 节点管理与 Metric 上传
- Pod 管理
- 资源监控
- 内存控制
- 资源压力驱逐
- CRI
- 探针管理
- 其他
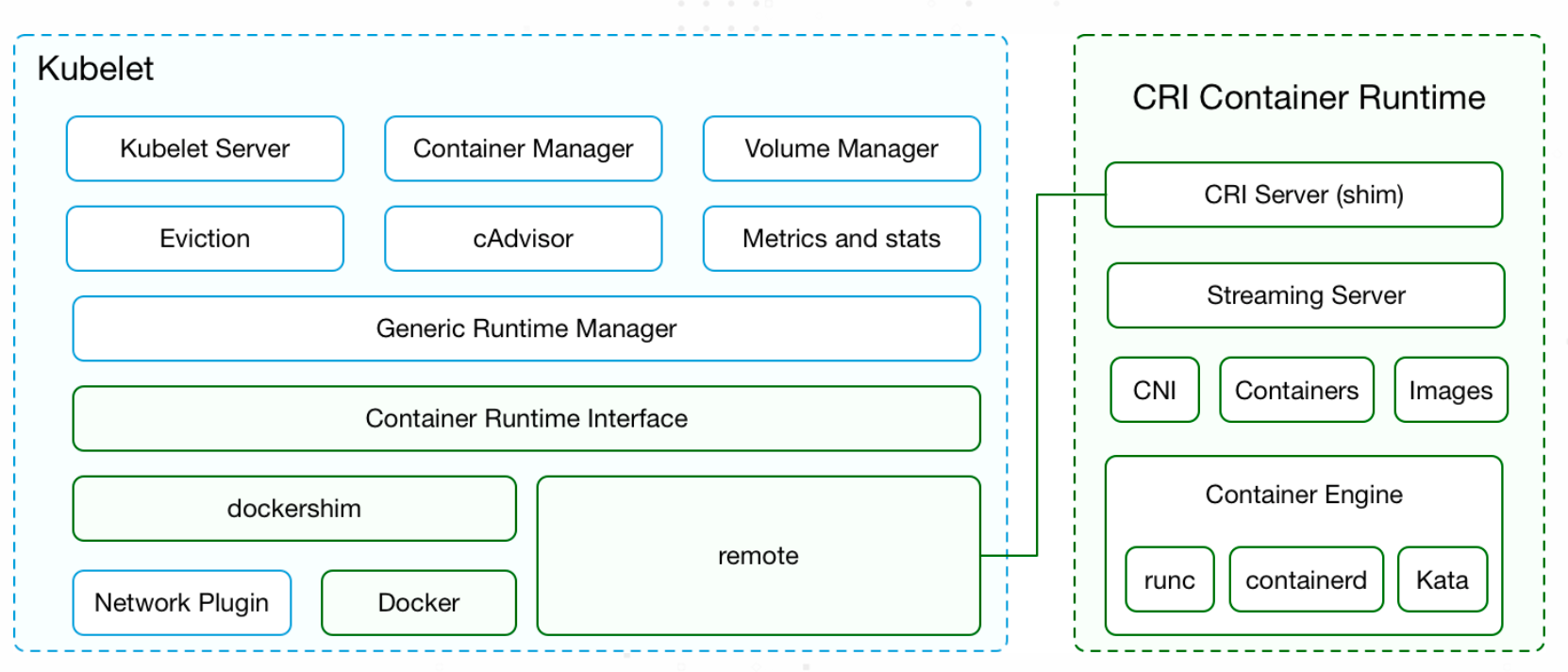
kubelet 功能对应的源代码位于 Kubernetes 项目的 pkg/kubelet/ 目录,从 kubelet 子目录可以看到,kubelet 管理的功能也都是以单个模块目录的形式进行划分的,
例如图中标记出来的 CRI 容器运行时、网络、资源驱逐、容器镜像、探针等管理模块。
Pod 驱逐
节点压力驱逐是 kubelet 主动终止 Pod 以回收节点上资源的过程。
kubelet 监控节点的各项资源 (如内存、磁盘空间 等),当资源的使用超过指定阈值之后,kubelet 会主动驱逐 (Kill) 相关资源关联的 Pod, 避免节点负载过重和资源争用。
源码说明
本文着重从源代码的角度分析一下 kubelet 驱逐 Pod 的实现过程和原理,功能对应的源代码位于 Kubernetes 项目的 pkg/kubelet/eviction 目录,本文以 Kubernetes v1.28 版本源代码进行分析。
Kubelet
Kubelet 表示具体的 kubelet 管理功能实现对象,因为对象内部的字段太多,这里只保留部分字段。
type Kubelet struct {
// 配置对象
kubeletConfiguration kubeletconfiginternal.KubeletConfiguration
// 节点名称 (指代运行所在 Node)
nodeName types.NodeName
// 运行时缓存信息 (管理 CRI 相关状态和信息)
runtimeCache kubecontainer.RuntimeCache
// 客户端
kubeClient clientset.Interface
// 处理并同步 Pod 的相关事件 (Add/Update/Delete 等)
podWorkers PodWorkers
// 节点上面的 Pod 同步周期
resyncInterval time.Duration
// Pod 存储和状态管理
podManager kubepod.Manager
// Pod 驱逐管理
evictionManager eviction.Manager
// 容器信息收集
cadvisor cadvisor.Interface
// Informer 相关字段
serviceLister serviceLister
serviceHasSynced cache.InformerSynced
nodeLister corelisters.NodeLister
nodeHasSynced cache.InformerSynced
// 节点标签
nodeLabels map[string]string
// 探针管理
// 探针的实现原理: https://dbwu.tech/posts/k8s/source_code/prober/
probeManager prober.Manager
livenessManager proberesults.Manager
startupManager proberesults.Manager
// 资源垃圾回收管理
containerGC kubecontainer.GC
// 容器镜像管理
imageManager images.ImageGCManager
// 容器日志管理
containerLogManager logs.ContainerLogManager
// 容器运行时
// Container runtime.
containerRuntime kubecontainer.Runtime
// 节点 IP
nodeIPs []net.IP
}
初始化 & 启动
NewMainKubelet 方法负责初始化一个 Kubelet 对象并返回。
func NewMainKubelet(...) (*Kubelet, error) {
...
klet := &Kubelet{
...
}
// 初始化驱逐管理器
evictionManager, evictionAdmitHandler := eviction.NewManager(...)
klet.evictionManager = evictionManager
...
return klet, nil
}
Kubelet 对象初始化完成后,调用 Run 方法开始运行。
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
...
if kl.kubeClient != nil {
// 启动异步同步节点状态
go wait.Until(kl.syncNodeStatus, kl.nodeStatusUpdateFrequency, wait.NeverStop)
go kl.fastStatusUpdateOnce()
}
// 阻塞初始化&设置 iptables 规则
if kl.makeIPTablesUtilChains {
kl.initNetworkUtil()
}
...
// 启动探针管理
kl.probeManager.Start()
// 核心调度方法
kl.syncLoop(updates, kl)
}
这里直接省略掉中间冗长的调用链,跳转到驱逐管理器初始化的地方:
func (kl *Kubelet) initializeRuntimeDependentModules() {
...
// 启动驱逐管理器,执行驱逐操作
kl.evictionManager.Start(kl.StatsProvider, ...)
...
}
驱逐管理对象
managerImpl 对象表示 kubelet 驱逐功能的实现对象。
type managerImpl struct {
// Pod 驱逐 (Kill) 方法
// 典型的 DI (依赖注入) 设计
killPodFunc KillPodFunc
// 镜像 GC 实现
imageGC ImageGC
// 容器 GC 实现
containerGC ContainerGC
...
// 资源类型和对应排序方法的映射关系
// 比如 CPU 资源的排序方法为 A
// 内存 资源的排序方法为 B
signalToRankFunc map[evictionapi.Signal]rankFunc
// 回收资源的方法列表
signalToNodeReclaimFuncs map[evictionapi.Signal]nodeReclaimFuncs
// 最后同步资源状态时间
lastObservations signalObservations
// 内存资源阈值实现 列表
thresholdNotifiers []ThresholdNotifier
// 内存资源阈值实现 列表 最后更新时间
thresholdsLastUpdated time.Time
}
// 公开包内私有类型
var _ Manager = &managerImpl{}
资源类型
Signal 定义了资源类型,每种资源类型都有对应的排序方法,在 Pod 被驱逐之前会先进行一轮排序来决定最终被驱逐的 Pod。
type Signal string
通过源代码的定义可以看到,资源的大类可以分为 内存型 和 存储型 (磁盘使用),内存型有内存使用情况、进程 ID 可分配数量,存储型有镜像使用空间、容器使用空间等。
const (
// 节点可用内存
// 使用 CGroup 资源限制来计算
// 而不是类似 free -m 的命令,因为 free -m 在容器中不起作用
// 相同的机制原理可以参考之前的文章: https://dbwu.tech/posts/golang_automaxprocs/
// 具体的计算方式可以参考
// CGroup : https://kubernetes.io/examples/admin/resource/memory-available.sh
// CGroup V2 版本: https://kubernetes.io/examples/admin/resource/memory-available-cgroupv2.sh
SignalMemoryAvailable Signal = "memory.available"
...
// 进程 ID 最大上限
// $ cat /proc/sys/kernel/pid_max
SignalPIDAvailable Signal = "pid.available"
)
启动入口
managerImpl.Start 方法是驱逐管理对象的启动入口方法,内部会启动异步 goroutine 来实现驱逐管理。
func (m *managerImpl) Start(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc, podCleanedUpFunc PodCleanedUpFunc, monitoringInterval time.Duration) {
thresholdHandler := func(message string) {
// 将驱逐核心方法 synchronize 包装为参数
m.synchronize(diskInfoProvider, podFunc)
}
// 如果使用内核级别的通知机制 (例如 CGroup 资源限制)
if m.config.KernelMemcgNotification {
for _, threshold := range m.config.Thresholds {
// 仅处理内存通知
if threshold.Signal == evictionapi.SignalMemoryAvailable || threshold.Signal == evictionapi.SignalAllocatableMemoryAvailable {
notifier, err := NewMemoryThresholdNotifier(threshold, m.config.PodCgroupRoot, &CgroupNotifierFactory{}, thresholdHandler)
if err != nil {
klog.InfoS("Eviction manager: failed to create memory threshold notifier", "err", err)
} else {
// 为每个通知实现单独启动一个 goroutine
go notifier.Start()
m.thresholdNotifiers = append(m.thresholdNotifiers, notifier)
}
}
}
}
// 启动单独的的 goroutine 负责驱逐管理
// start the eviction manager monitoring
go func() {
// 内部是一个无限循环
for {
// 定期执行 synchronize 方法来完成驱逐过程
evictedPods, err := m.synchronize(diskInfoProvider, podFunc)
if evictedPods != nil && err == nil {
// 阻塞执行 Pod 驱逐 (Kill) 操作
m.waitForPodsCleanup(podCleanedUpFunc, evictedPods)
} else {
// 如果发生错误,进入休眠
time.Sleep(monitoringInterval)
}
}
}()
}
核心方法
managerImpl.synchronize 方法是驱逐管理实现的核心方法,内部通过一系列的资源状态对比和判断,最终返回需要被驱逐 (Kill) 的 Pod 列表。
func (m *managerImpl) synchronize(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc) []*v1.Pod {
...
// 获取节点上运行的 Pod 列表
activePods := podFunc()
updateStats := true
// 获取节点的各项资源 (CPU, 内存 ...) 使用情况
summary, err := m.summaryProvider.Get(updateStats)
// 最后资源阈值的最后更新时间超过 10 秒
// 更新一下各项资源的阈值
if m.clock.Since(m.thresholdsLastUpdated) > notifierRefreshInterval {
...
}
// 解析各项资源的总量、已使用量 等等 Metric
observations, statsFunc := makeSignalObservations(summary)
// 检测各项资源的使用情况是否已经超过阈值
thresholds = thresholdsMet(thresholds, observations, false)
// 检测满足驱逐条件的 Pods
thresholds = thresholdsMetGracePeriod(thresholdsFirstObservedAt, now)
// 加锁更新对象的相关状态字段
m.Lock()
...
m.Unlock()
// 没有需要驱逐的 Pod 时直接返回
if len(thresholds) == 0 {
return nil
}
// 根据驱逐优先级对 Pod 进行排序
sort.Sort(byEvictionPriority(thresholds))
// 计算接下来要驱逐的具体资源对应的 Pod
thresholdToReclaim, resourceToReclaim, foundAny := getReclaimableThreshold(thresholds)
...
// 使用资源对应的排序方法对要驱逐的资源 Pod 进行排序
// 比如根据内存进行排序,使用最多内存的 Pod 先被驱逐掉
rank(activePods, statsFunc)
// 每次最多驱逐一个 Pod
for i := range activePods {
pod := activePods[i]
...
// 调用 evictPod 方法驱逐 Pod
if m.evictPod(pod, gracePeriodOverride, message, annotations) {
return []*v1.Pod{pod}
}
}
return nil
}
通过 managerImpl.synchronize 方法的源代码可以看到: 每次同步时都有一个固定的工作流:
- 获取节点上运行的 Pod 列表
- 获取节点的各项资源 (CPU, 内存 …) 使用情况
- 获取各项资源的使用阈值
- 检测各项资源使用是否已经超过阈值
- 检测满足驱逐条件的 Pod 列表
- 根据驱逐优先级对要被驱逐的 Pod 进行排序
- 调用 evictPod 方法执行 Pod 驱逐操作
驱逐 Pod
managerImpl.evictPod 方法负责驱逐 Pod。
func (m *managerImpl) evictPod(pod *v1.Pod, ...) bool {
...
// 通过调用 managerImpl 对象初始化时 注入的 Pod 驱逐方法,阻塞式驱逐 Pod
err := m.killPodFunc(pod, status, &gracePeriodOverride)
...
}
内存状态通知
上文中提到,驱逐管理对象启动时,可能会采用内核级别的通知机制,这样可以保证 Metric 精度和性能最大化,从源代码文件中看到,目前只实现了内存事件通知。
通知对象
linuxCgroupNotifier 作为事件通知对象,通过命名方式可以看到,该对象只实现了 Linux 上面的事件通知,并且内部使用的是 CGroup 来获取相应的事件。
type linuxCgroupNotifier struct {
eventfd int
epfd int
stop chan struct{}
stopLock sync.Mutex
}
// 公开包内私有类型
var _ CgroupNotifier = &linuxCgroupNotifier{}
创建通知对象
NewCgroupNotifier 方法返回一个完成初始化的 linuxCgroupNotifier 对象,通过执行 CGroup 资源限制操作,以便在资源超过阈值时接收到来自系统的通知。
func NewCgroupNotifier(path, attribute string, threshold int64) (CgroupNotifier, error) {
var watchfd, eventfd, epfd, controlfd int
var err error
// 创建监听文件描述符
watchfd, err = unix.Open(fmt.Sprintf("%s/%s", path, attribute), unix.O_RDONLY|unix.O_CLOEXEC, 0)
// 创建控制文件描述符
controlfd, err = unix.Open(fmt.Sprintf("%s/cgroup.event_control", path), unix.O_WRONLY|unix.O_CLOEXEC, 0)
// 创建事件描述符
eventfd, err = unix.Eventfd(0, unix.EFD_CLOEXEC)
// 创建 epoll 文件描述符
epfd, err = unix.EpollCreate1(unix.EPOLL_CLOEXEC)
// 关联各文件描述符和资源限制阈值触发通知
config := fmt.Sprintf("%d %d %d", eventfd, watchfd, threshold)
_, err = unix.Write(controlfd, []byte(config))
// 根据已有的文件描述符构建一个新的事件通知对象
return &linuxCgroupNotifier{
eventfd: eventfd,
epfd: epfd,
stop: make(chan struct{}),
}, nil
}
监听 & 读取事件
linuxCgroupNotifier.Start 方法负责开始监听事件,并在内部启动一个无限循环不断读取监听到的事件,方法内部并不会处理事件数据,读取到数据之后会立即丢弃。
func (n *linuxCgroupNotifier) Start(eventCh chan<- struct{}) {
// 将 epoll 文件描述符加入到 Linux epoll 机制,监听读取
err := unix.EpollCtl(n.epfd, unix.EPOLL_CTL_ADD, n.eventfd, &unix.EpollEvent{
Fd: int32(n.eventfd),
Events: unix.EPOLLIN,
})
for {
...
// 调用 wait 等待事件到达
event, err := wait(n.epfd, n.eventfd, notifierRefreshInterval)
buf := make([]byte, eventSize)
_, err = unix.Read(n.eventfd, buf)
...
eventCh <- struct{}{}
}
}
wait 方法和 epoll 中的 wait 方法一致,用于等待事件,为了避免没有事件时引起调用方长时间阻塞,方法内部设置了超时机制 (10 秒),
当接收到事件数据时,返回 true, 否则返回 false。
func wait(epfd, eventfd int, timeout time.Duration) (bool, error) {
events := make([]unix.EpollEvent, numFdEvents+1)
timeoutMS := int(timeout / time.Millisecond)
n, err := unix.EpollWait(epfd, events, timeoutMS)
..
for _, event := range events[:n] {
if event.Fd == int32(eventfd) {
if event.Events&unix.EPOLLHUP != 0 || event.Events&unix.EPOLLERR != 0 || event.Events&unix.EPOLLIN != 0 {
// 三个标识符含义如下
// EPOLLHUP: 正常情况下不会出现这种情况,如果正好发生了,由调用方处理
// EPOLLERR: 就算读取到了 Error, 也可以认为是读取到了事件数据,同样也是由调用方处理
// EPOLLIN: 读取到了事件数据
return true, nil
}
}
}
return false, nil
}
