Kubernetes ReplicaSet 设计与实现
2023-12-15 Cloud Native Kubernetes 读代码
概述
ReplicaSet 的目的是维护并保证一组的 Pod 在任何时候都处于运行状态,它通常用来保证给定数量的、完全相同的 Pod 的可用性。
ReplicaSet 的作用就是持续监听其关联的 Pod, 在 Pod 发生故障时立即启动新的 Pod, 在 Pod 数量多出定义数量时删除多余的 Pod, 保证 Pod 数量始终位于期望状态。
需要注意的是: ReplicaSet 控制器并不会主动创建并运行 Pod, 而是通过创建对应的 Pod 声明并发送到 API Server, 最后由调度器分配 Node 并由 Node 上面的 kubelet 创建并运行指定的 Pod。
示例
# 官方示例 controllers/frontend.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
replicas: 3 # 副本数量,可以根据实际情况修改
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
在 Kubernetes 中执行上面的代码后,会创建 1 个对应的 ReplicaSet 对象和 3 个 Pod 对象。
源码说明
本文着重从源代码的角度分析一下 ReplicaSet 的实现原理,ReplicaSet 功能对应的源代码位于 Kubernetes 项目的 pkg/controller/replicaset/ 目录,本文以 Kubernetes v1.28 版本源代码进行分析。
流程图
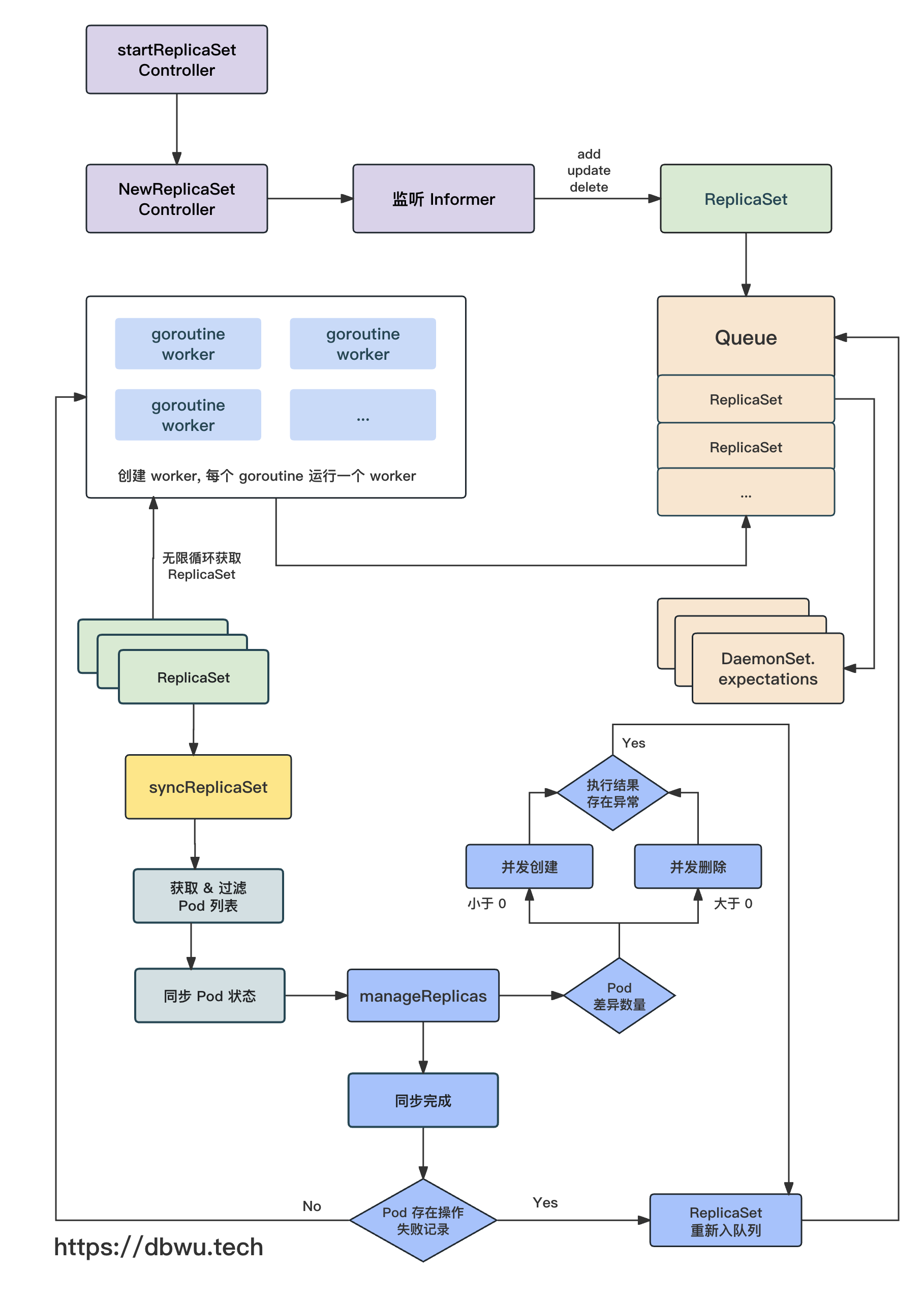
下面我们跟着流程图一起看下源代码的具体实现。
ReplicaSetController
首先来看看 ReplicaSetController 控制器对象,该对象是实现 ReplicaSet 功能的核心对象。
// ReplicaSetController 负责将 ReplicaSet 对应的 Pod 调整到定义的期望状态
type ReplicaSetController struct {
// kubelet 客户端对象
// 用于执行各项类似 "kubectl ..." 操作
kubeClient clientset.Interface
// Pod 操作对象
// 用于对 Pod 进行各项操作,例如创建/删除 等
podControl controller.PodControlInterface
// 在创建/删除指定数量的副本之后,ReplicaSet 将会临时挂起
// 在监听到指定事件后恢复正常
burstReplicas int
// 回调方法
// 同时方便在单元测试中注入 Mock
syncHandler func(ctx context.Context, rsKey string) error
// 缓存对象
// 记录每个 ReplicaSet 需要创建/删除的 Pod
// 每轮同步过程中,对于 创建/删除 操作失败的 Pod 数量,都会记录起来
// 等到下一轮同步时继续执行相关的操作
// 直到 Pod 数量副本达到期望状态
expectations *controller.UIDTrackingControllerExpectations
// ReplicaSet 列表
rsLister appslisters.ReplicaSetLister
rsListerSynced cache.InformerSynced
// Pod 列表
podLister corelisters.PodLister
podListerSynced cache.InformerSynced
// 队列中存储发生了变化 (需要同步) 的 ReplicaSet
queue workqueue.RateLimitingInterface
}
初始化
NewReplicaSetController 方法用于 ReplicaSetController 控制器对象的初始化工作,并返回一个实例化对象,作为一个基础方法,
其内部又调用了 NewBaseController 方法。
func NewReplicaSetController(...) *ReplicaSetController {
...
return NewBaseController(
...
)
}
func NewBaseController(...) *ReplicaSetController {
rsc := &ReplicaSetController{
...
}
// 增加 ReplicaSet informer 监听回调方法
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
rsc.addRS(logger, obj)
},
UpdateFunc: func(oldObj, newObj interface{}) {
rsc.updateRS(logger, oldObj, newObj)
},
DeleteFunc: func(obj interface{}) {
rsc.deleteRS(logger, obj)
},
})
...
// 增加 Pod informer 监听回调方法
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
rsc.addPod(logger, obj)
},
UpdateFunc: func(oldObj, newObj interface{}) {
rsc.updatePod(logger, oldObj, newObj)
},
DeleteFunc: func(obj interface{}) {
rsc.deletePod(logger, obj)
},
})
// 注册回调方法
// 默认为 ReplicaSetController 对象的 syncReplicaSet 方法
// 在单元测试中,也可以通过参数的注入,完成 Mock
rsc.syncHandler = rsc.syncReplicaSet
return rsc
}
启动控制器
根据控制器的初始化方法 NewReplicaSetController 的调用链路,可以找到控制器开始启动和执行的地方。
// cmd/kube-controller-manager/app/apps.go
func startReplicaSetController(ctx context.Context, ...) (controller.Interface, bool, error) {
// 启动一个单独的 goroutine 来完成 {初始化 && 运行}
go replicaset.NewReplicaSetController(
...
).Run(ctx, int(controllerContext.ComponentConfig.ReplicaSetController.ConcurrentRSSyncs))
return nil, true, nil
}
具体逻辑方法
ReplicaSetController.Run 方法执行具体的初始化逻辑。
func (rsc *ReplicaSetController) Run(ctx context.Context, workers int) {
...
// (根据参数配置) 启动多个 goroutine 处理逻辑 (默认为 5 个)
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, rsc.worker, time.Second)
}
<-ctx.Done()
}
ReplicaSetController.worker 方法本质上就是一个无限循环轮询器,不断从队列中取出 ReplicaSet 对象,然后进行对应的操作。
func (rsc *ReplicaSetController) worker(ctx context.Context) {
// 内部调用 processNextWorkItem 方法
for rsc.processNextWorkItem(ctx) {
}
}
func (rsc *ReplicaSetController) processNextWorkItem(ctx context.Context) bool {
// 从队列获取 ReplicaSet 对象
// 获取到的对象可以编码为一个字符串 key
key, quit := rsc.queue.Get()
...
// 调用回调方法,默认也就是 syncReplicaSet 方法
err := rsc.syncHandler(ctx, key.(string))
if err == nil {
// 创建/删除 Pod 时一切正常
// 将当前 ReplicaSet 踢出队列
rsc.queue.Forget(key)
return true
}
// 创建/删除 Pod 时出现失败的 ReplicaSet
// 将当前 ReplicaSet 重新放入队列
rsc.queue.AddRateLimited(key)
...
}
ReplicaSet 同步
ReplicaSetController 的回调处理方法默认就是 ReplicaSetController.syncReplicaSet 方法,也就是说,该方法是所有 ReplicaSet 操作的入口方法。
该方法会根据指定的参数 key 取出对应的 ReplicaSet 对象,并执行其配置执行一系列的同步操作,保证 ReplicaSet 的 Pod 副本数量始终位于期望状态。
func (rsc *ReplicaSetController) syncReplicaSet(ctx context.Context, key string) error {
...
// 通过 key 解析出 ReplicaSet 对象对应的 命名空间和名称
namespace, name, err := cache.SplitMetaNamespaceKey(key)
// 获取 ReplicaSet 对象
rs, err := rsc.rsLister.ReplicaSets(namespace).Get(name)
// 检测 ReplicaSet 是否需要同步
rsNeedsSync := rsc.expectations.SatisfiedExpectations(logger, key)
...
// 获取 ReplicaSet 对应的 Pod 列表
// 其中包含了已经终止的 Pod
allPods, err := rsc.podLister.Pods(rs.Namespace).List(labels.Everything())
// 过滤掉已经终止的 Pod
filteredPods := controller.FilterActivePods(logger, allPods)
filteredPods, err = rsc.claimPods(ctx, rs, selector, filteredPods)
...
// 深度拷贝一个对象
// 在方法内部作为局部变量使用
rs = rs.DeepCopy()
// 同步 Pod 副本到期望状态
var manageReplicasErr error
if rsNeedsSync && rs.DeletionTimestamp == nil {
manageReplicasErr = rsc.manageReplicas(ctx, filteredPods, rs)
}
// 计算 ReplicaSet 状态
newStatus := calculateStatus(rs, filteredPods, manageReplicasErr)
// 同步 ReplicaSet 的状态
updatedRS, err := updateReplicaSetStatus(logger, rsc.kubeClient.AppsV1().ReplicaSets(rs.Namespace), rs, newStatus)
...
}
通过 ReplicaSetController.syncReplicaSet 方法的源代码,我们可以看到: ReplicaSet 每次同步时,都会执行如下的操作,而且每个操作的顺序都是一致的:
- 根据参数 key 获取指定的 ReplicaSet 对象
- 检测 ReplicaSet 是否需要同步
- 获取 ReplicaSet 对应的 Pod 列表
- 同步 Pod 副本到期望状态
- 计算 ReplicaSet 状态
有了上面的这个大致的逻辑框架,接下来我们逐个分析对应的单个方法实现即可。
检测是否需要同步
SatisfiedExpectations 方法用于检测指定的 ReplicaSet 是否需要同步,如果给定的参数 ReplicaSet 需要执行 创建/删除 状态同步,返回 true, 否则返回 false。
创建/删除状态计数变化在 ReplicaSet 控制器同步时建立,并在 ReplicaSet 控制器观察到对应的对象变化时更新。
func (r *ControllerExpectations) SatisfiedExpectations(logger klog.Logger, controllerKey string) bool {
// 如果可以获取到 Expectations 对象
if exp, exists, err := r.GetExpectations(controllerKey); exists {
if exp.Fulfilled() {
// 这个逻辑没看懂!
// 既然 Expectations 满足期望,也就意味着此时运行的 Pod 数量和期望数量是一致的
// 那还同步什么 ?
return true
} else if exp.isExpired() {
// Expectations 上次同步时间已失效
// ReplicaSet 需要同步,直接返回
return true
} else {
// ReplicaSet 不需要同步,直接返回
return false
}
} else if err != nil {
// 如果发生错误,强制 ReplicaSet 同步
} else {
// 创建一个新的 ReplicaSet 控制器时,它没有对应的 Expectations 对象
// 或者
// 一个已有的 ReplicaSet 控制器距离上次同步的时间已经超过同步周期
// 这两种情况都需要进行同步
}
// 如果上面的条件全部没有触发到,则需要进行同步
return true
}
isExpired 方法用于检测 Expectations 对象当前是否处于有效的同步周期内,内部实现也很简单: 判断距离上次同步时间是否已经超过 5 分钟。
const (
ExpectationsTimeout = 5 * time.Minute
)
func (exp *ControlleeExpectations) isExpired() bool {
return clock.RealClock{}.Since(exp.timestamp) > ExpectationsTimeout
}
isExpired 方法用于检测此时运行的 Pod 数量和期望数量是一致的,内部实现也很简单: 判断需要创建的 Pod 数量和需要删除的 Pod 熟练是否小于等于 0。
func (e *ControlleeExpectations) Fulfilled() bool {
return atomic.LoadInt64(&e.add) <= 0 && atomic.LoadInt64(&e.del) <= 0
}
同步 (更新) Pod 状态
manageReplicas 方法用于检测并更新指定的 ReplicaSet 对象对应的 Pod 副本,当运行的 Pod 数量低于预期数量时,创建新的 Pod,
当运行的 Pod 数量高于预期数量时,删除多余的 Pod。
func (rsc *ReplicaSetController) manageReplicas(ctx context.Context, filteredPods []*v1.Pod, rs *apps.ReplicaSet) error {
// 差异数量 = 当前运行的 Pod 数量 - ReplicaSet 期望 Pod 数量
// 差异数量 > 0: 需要删除多余的 Pod
// 差异数量 < 0: 需要创建的 Pod
diff := len(filteredPods) - int(*(rs.Spec.Replicas))
...
if diff < 0 {
// 创建 diff 个新的 Pod
// 负负得正
diff *= -1
if diff > rsc.burstReplicas {
// 如果 diff 大于单次最大操作数量
// 修正 diff 数量
diff = rsc.burstReplicas
}
// 更新 ReplicaSet 关联的 Expectations 对象
rsc.expectations.ExpectCreations(logger, rsKey, diff)
// 批量创建 Pod
// 每次创建成功后,下一轮创建的 Pod 数量以指数级进行增长 (1, 2, 4, 8 ...)
// 参考了 TCP 的 “慢启动” 方式
successfulCreations, err := slowStartBatch(diff, controller.SlowStartInitialBatchSize, func() error {
err := rsc.podControl.CreatePods(ctx, rs.Namespace, &rs.Spec.Template, rs, metav1.NewControllerRef(rs, rsc.GroupVersionKind))
...
return err
})
// 创建失败的 Pod 数量 = diff - 创建成功的 Pod 数量
// 当然,创建失败的 Pod 会在当前的 ReplicaSet 下一次同步时再次创建
if skippedPods := diff - successfulCreations; skippedPods > 0 {
for i := 0; i < skippedPods; i++ {
// 记录更新 ReplicaSet 关联的 Expectations 对象字段: 需要创建的 Pod 数量
rsc.expectations.CreationObserved(logger, rsKey)
}
}
return err
} else if diff > 0 {
// 删除 diff 个多余的Pod
if diff > rsc.burstReplicas {
// 如果 diff 大于单次最大操作数量
// 修正 diff 数量
diff = rsc.burstReplicas
}
// 获取 (选择) 需要被删除的 Pod 列表
podsToDelete := getPodsToDelete(filteredPods, relatedPods, diff)
// 将需要被删除的 Pod 列表的快照记录到 Expectations 对象
// 这样我们就可以直接从该对象中获取到 Pod 的删除执行结果
rsc.expectations.ExpectDeletions(logger, rsKey, getPodKeys(podsToDelete))
// 这个 channel 设计得很巧妙,接收 error + 信号量 合二为一
errCh := make(chan error, diff)
// 开始并发删除 Pod, 朴素的实现 :-)
var wg sync.WaitGroup
wg.Add(diff)
for _, pod := range podsToDelete {
go func(targetPod *v1.Pod) {
defer wg.Done()
// 执行删除 Pod 操作
if err := rsc.podControl.DeletePod(ctx, rs.Namespace, targetPod.Name, rs); err != nil {
// 如果 Pod 删除失败了
// 就记录到 Expectations 对象中
podKey := controller.PodKey(targetPod)
rsc.expectations.DeletionObserved(logger, rsKey, podKey)
// 如果 Pod 存在并且删除失败了
// 将 error 发送到 channel
if !apierrors.IsNotFound(err) {
errCh <- err
}
}
}(pod)
}
// 等待并发删除 Pod 结束
wg.Wait()
select {
case err := <-errCh:
// 不管删除失败的 Pod 数量有多少,它们的 error 都是一致的
// 所以直接只需要返回一个 error 即可
if err != nil {
return err
}
default:
}
}
return nil
}
批量创建 Pod
真正实现 Pod 的批量创建是在方法 slowStartBatch, 每次创建的 Pod 数量会按照 “指数增长 (从 1 开始)” 规则并发进行,最后返回成功创建的 Pod 数量。
每轮创建过程中,如果所有的 Pod 都创建成功了,下一轮创建的 Pod 数量就会翻倍,如果其中任意一个 Pod 创建失败了,就直接返回了,
剩余的没有创建的 Pod 会在 ReplicaSet 下一次同步时再创建。
func slowStartBatch(count int, initialBatchSize int, fn func() error) (int, error) {
// 剩余需要创建的 Pod 数量
remaining := count
// 创建成功的 Pod 总数量
successes := 0
// 每轮指数增长 (1, 2, 4, 8 ...)
for batchSize := integer.IntMin(remaining, initialBatchSize); batchSize > 0; batchSize = integer.IntMin(2*batchSize, remaining) {
errCh := make(chan error, batchSize)
// 开始并发创建 Pod, 朴素的实现 :-)
var wg sync.WaitGroup
wg.Add(batchSize)
for i := 0; i < batchSize; i++ {
go func() {
defer wg.Done()
// 执行创建 Pod 的回调函数
if err := fn(); err != nil {
errCh <- err
}
}()
}
// 等待并发创建结束
wg.Wait()
// 当前这一轮创建成功的 Pod 数量
curSuccesses := batchSize - len(errCh)
// 累加总数量
successes += curSuccesses
if len(errCh) > 0 {
// 如果有任意一个 Pod 创建失败了,直接返回
return successes, <-errCh
}
// 更新剩余需要创建的 Pod 数量
remaining -= batchSize
}
return successes, nil
}
从上面的源代码可以看到,创建 Pod 的方法并不是固定的,而是通过参数中的 fn 回调参数决定的 (这非常便于单元测试),根据上下文的代码追踪,
我们可以看到其注入的回调方法是 RealPodControl.createPods 方法。
func (r RealPodControl) createPods(ctx context.Context, ...) error {
...
// 通过 KubeClient 创建 Pod
newPod, err := r.KubeClient.CoreV1().Pods(namespace).Create(ctx, pod, metav1.CreateOptions{})
...
}
选择需要删除的 Pod
删除多余的 Pod 之前,首先要筛选出来需要删除的 Pod 列表,该功能是由 getPodsToDelete 方法来实现的。
func getPodsToDelete(filteredPods, ...) []*v1.Pod {
// 如果要删除部分 Pod
// 那么就需要部分 Pod, 就先进行排序
// 最后排在前面的 Pod 就是需要删除的
if diff < len(filteredPods) {
// 对 Pod 列表进行预处理,返回包装好的列表
podsWithRanks := getPodsRankedByRelatedPodsOnSameNode(filteredPods, relatedPods)
// 对 Pod 列表进行排序
// 具体的排序规则请参考 [Pod 排序规则] 小节
sort.Sort(podsWithRanks)
}
// 如果要删除全部 Pod
// 直接删除就行
return filteredPods[:diff]
}
getPodsRankedByRelatedPodsOnSameNode 方法根据参数 Pod 列表进行排序,并返回包装后 (包含排序值) 的 Pod 列表。
其中,每个 Pod 对象和排序值对象索引一一对应,排序值表示该 Pod 所在节点上运行的 Pod 数量。
func getPodsRankedByRelatedPodsOnSameNode(podsToRank, relatedPods []*v1.Pod) controller.ActivePodsWithRanks {
podsOnNode := make(map[string]int)
for _, pod := range relatedPods {
if controller.IsPodActive(pod) {
// 累加同一节点下运行的 Pod 数量
podsOnNode[pod.Spec.NodeName]++
}
}
// 生成和 Pod 列表对应的排序值列表
ranks := make([]int, len(podsToRank))
for i, pod := range podsToRank {
ranks[i] = podsOnNode[pod.Spec.NodeName]
}
// 返回包装的对象
return controller.ActivePodsWithRanks{Pods: podsToRank, Rank: ranks, Now: metav1.Now()}
}
Pod 排序规则
通过前文的源代码可以看到,选择需要删除的 Pod 过程中,涉及到对指定 Pod 列表进行排序,那么排序规则是什么呢?
我们通过返回的 ActivePodsWithRanks 对象代码追踪一下。
ActivePodsWithRanks 实现了标准库的排序接口,其中 Len 和 Swap 方法都很简单,这里着重分析一下比较两个元素的 Less 方法。
type ActivePodsWithRanks struct {
// Pod 列表
Pods []*v1.Pod
// Pod 排序值列表
Rank []int
// 表示比较操作的时间戳
Now metav1.Time
}
func (s ActivePodsWithRanks) Len() int {
return len(s.Pods)
}
func (s ActivePodsWithRanks) Swap(i, j int) {
s.Pods[i], s.Pods[j] = s.Pods[j], s.Pods[i]
s.Rank[i], s.Rank[j] = s.Rank[j], s.Rank[i]
}
ActivePodsWithRanks.Less 方法用于比较列表中的两个元素大小,是实现排序的核心方法,方法内部比较两个元素时,会根据多条规则进行检测和对比。
如果第一个参数索引对应的元素应该被删除,返回 true, 否则返回 false。
func (s ActivePodsWithRanks) Less(i, j int) bool {
// 根据 Pod 是否已分配 Node 比较
// 未分配的 Pod < 已分配的 Pod
if s.Pods[i].Spec.NodeName != s.Pods[j].Spec.NodeName && (len(s.Pods[i].Spec.NodeName) == 0 || len(s.Pods[j].Spec.NodeName) == 0) {
...
}
// 根据 Pod 运行状态进行比较
// PodPending < PodUnknown < PodRunning
if podPhaseToOrdinal[s.Pods[i].Status.Phase] != podPhaseToOrdinal[s.Pods[j].Status.Phase] {
...
}
// 根据 Pod 就绪状态进行比较
// Not ready < ready
if podutil.IsPodReady(s.Pods[i]) != podutil.IsPodReady(s.Pods[j]) {
...
}
// 根据 Pod 删除时的操作成本进行比较
// 低成本 < 高成本
if utilfeature.DefaultFeatureGate.Enabled(features.PodDeletionCost) {
...
}
// 根据 Pod 分布在节点上的数量进行比较
// 数量多 < 数量少
// 例如:
// Pod A 有 3 个副本,分布在了 3 个节点上
// Pod B 有 3 个副本,分布在了 2 个节点上
// 那么此时应该优先删除 Pod B, 因为其在某个节点上面有重复的副本
if s.Rank[i] != s.Rank[j] {
...
}
// 根据 Pod 就绪时间进行比较
// empty time < less time < more time
if podutil.IsPodReady(s.Pods[i]) && podutil.IsPodReady(s.Pods[j]) {
...
}
// 根据 Pod 中容器的重启次数进行比较
// 优先删除容器重启次数高的 Pod
if maxContainerRestarts(s.Pods[i]) != maxContainerRestarts(s.Pods[j]) {
...
}
// 根据 Pod 创建时间进行比较
// 优先删除创建时间较新的 Pod
if !s.Pods[i].CreationTimestamp.Equal(&s.Pods[j].CreationTimestamp) {
...
}
return false
}
通过上面的排序规则可以看到,Kubernetes 在删除时会着重考虑 “稳定性更好” 的 Pod, 然后删除 “稳定性较差” 的 Pod。
删除 Pod
对 Pod 列表排序完成之后,就可以选择出要删除的 Pod 了,最后调用 DeletePod 方法删除即可。
func (r RealPodControl) DeletePod(ctx context.Context, ...) error {
...
// 通过 KubeClient 删除 Pod
if err := r.KubeClient.CoreV1().Pods(namespace).Delete(ctx, podID, metav1.DeleteOptions{}); err != nil {
...
}
...
}
小结
