Kubernetes 调度器 - 核心流程
2024-01-20 Cloud Native Kubernetes 读代码
概述
在 Kubernetes 中,调度过程 是指将 Pod 绑定到合适的 Node (节点) 上,以便对应 Node 上的 Kubelet 能够运行这些 Pod,而实现调度过程的就是本文的主角 - 调度器。
调度器通过 Kubernetes 的监测(Watch)机制来发现集群中新创建且尚未被调度的 Pod,然后为每一个 Pod 选择一个适合运行的 Node 进行绑定和运行。
调度时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局部性、负载间的干扰等等。
需要注意的是: 调度器本身并不会直接和 Node 节点进行交互去运行指定的 Pod, 根据 Kubernetes 的声明式语义哲学,调度器只需要通过 API Server 更新 Pod 的定义, 然后由 API Server 向 Node (kubelet) 发送请求,当目标 Node 上的 kubelet 发现有 Pod 调度到本节点时,它就会创建并运行指定 Pod 的容器。
源码说明
本文着重从源代码的角度分析一下 调度器 的实现原理,默认的调度器功能对应的源代码位于 Kubernetes 项目的 cmd/kube-scheduler 目录,本文以 Kubernetes v1.28 版本源代码进行分析。
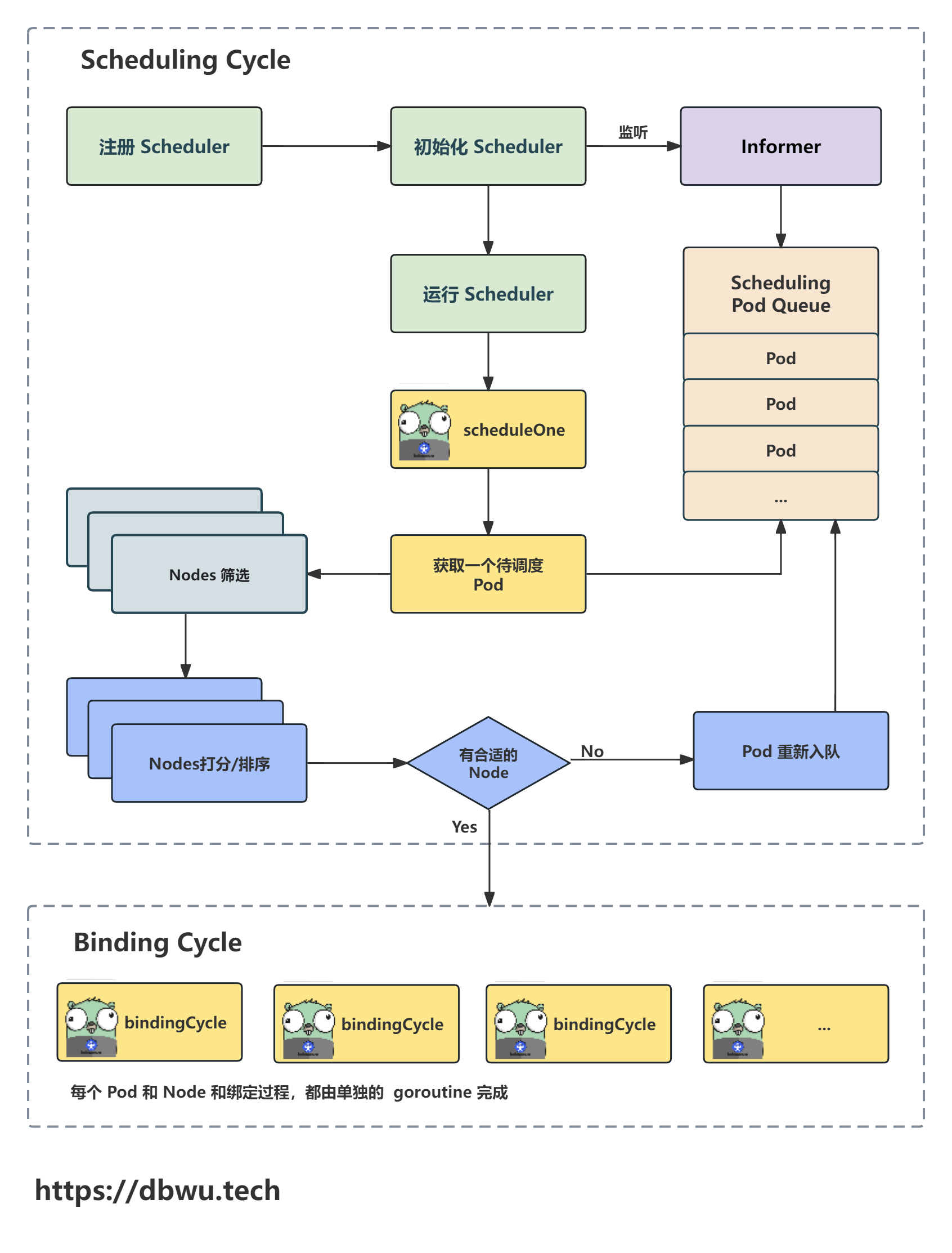
核心流程
Kubernetes 中的调度过程主要分为两个大的步骤:
- 调度周期: 调度器从多个候选的 Nodes 中 (执行各种过滤操作) 为 Pod 选择一个最适合的
- 绑定周期: 绑定 Pod 和 Node
过滤节点
调度过程中会使用 [插件 + 扩展点] 来实现过滤机制,以此来决定哪些 Node 对 Pod 是可用的,例如常见的过滤条件有:
- Node 是否满足 Pod 的资源请求
- Node 是否负载过重
- Pod 是否指定了 Node 名称
- Pod 是否指定了标签和污点容忍度
- 等等
假设调度器要为一个 Pod 寻找合适的 Node, 该 Pod 的资源请求如下:
| 资源名称 | 请求量 |
|---|---|
| CPU | 2000 m |
| 内存 | 4096 MB |
| 存储 | SSD |
调度器会对参与调度的节点进行筛选过滤,并为 Pod 选择一个最合适的 Node 运行,假设本地参与调度的 Nodes 数量为 8 个,并且最终调度器选中 4 号 Node 为目标 Node, 下面是一个简化的调度流程过滤示例图:
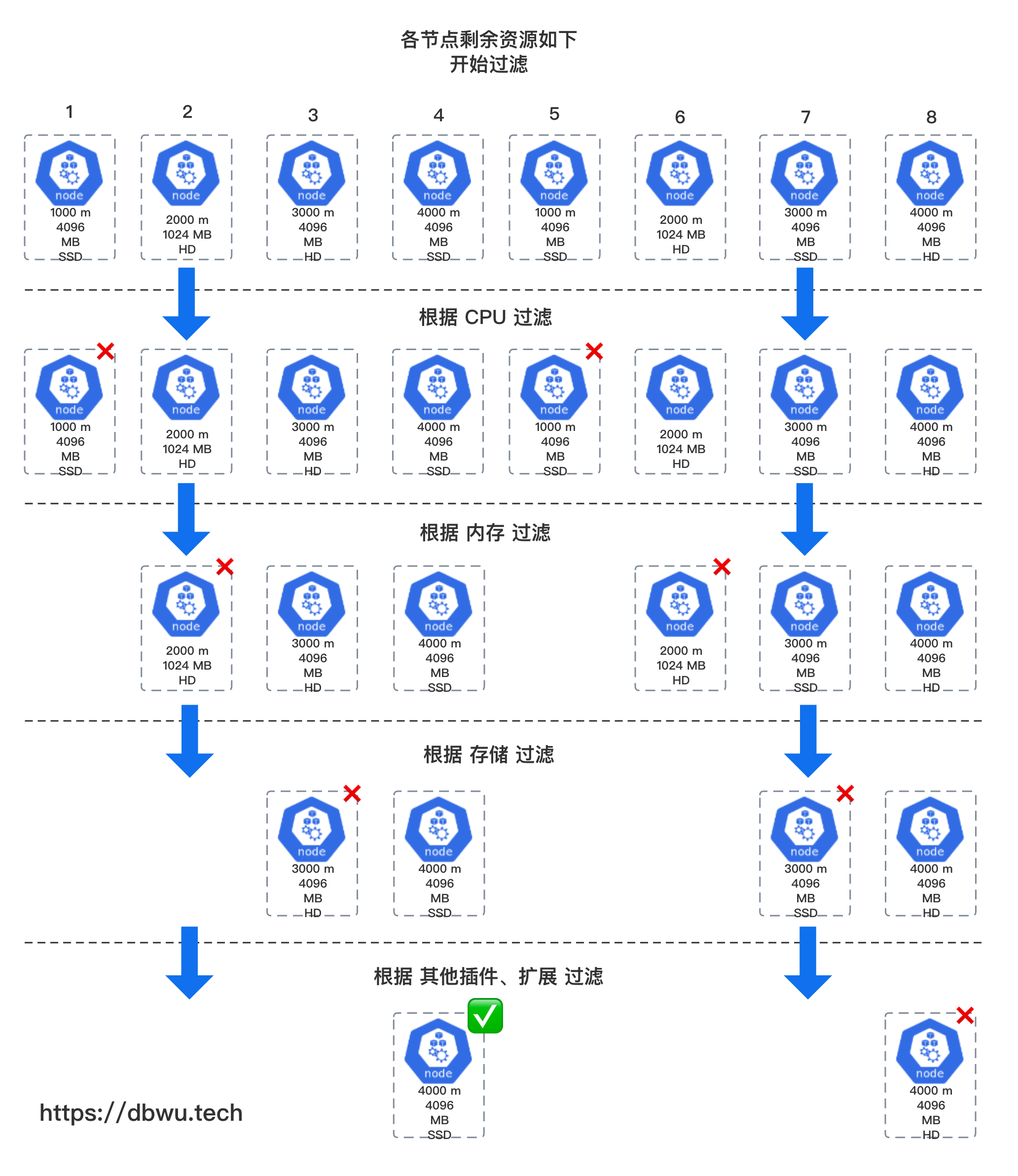
从上面的示例图中可以可以看到,经过各种条件的层层筛选,最终调度器确定的目标为 4 号 Node。
插件
插件可以简单地理解为 “一个调用方法”,通过注册的方式注册到一个或多个 “扩展点” 被调用,插件只需要实现 “插件接口” 即可,具体功能不做限制。 一个插件可以改变调度的决策结果,也可以仅仅提供一些数据,还可以实现别的其他自定义功能。
常见的插件:
- NodeName: 筛选出和 Pod 指定的 Node 名称一样的 Node 列表
- TaintToleration: 筛选出符合 Pod 污点容忍度的 Node 列表
- NodeAffinity: 筛选出符合 Pod 亲和性的 Node 列表
- NodeResourcesFit: 筛选出符合 Pod 请求资源的 Node 列表
- 等等
调度周期内的扩展点 (事件) 列表
| 事件名称 | 事件作用 |
|---|---|
| PreFilter | 预处理 Pod |
| Filter | 过滤 Nodes |
| PostFilter | 仅在该 Pod 没有可行的 Node 时调用 |
| PreScore | 打分预处理 |
| Score | 对 Nodes 进行打分 |
| NormalizeScore | 在调度器计算 Node 排名之前修改分数 |
| Reserve | 调度器实际将一个 Pod 绑定到其指定节点之前,调用该扩展点 |
| Permit | 每个 Pod 调度周期的最后调用,用于防止或延迟 Pod 的绑定 |
| PreBind | 执行 Pod 绑定前所需的所有工作 |
| Bind | 将 Pod 绑定到 Node 上 |
| PostBind | 在 Pod 成功绑定后被调用 |
| Unreserve | 如果 Pod 被保留,然后在后面的阶段中被拒绝,则 Unreserve 将被通知 |
单个扩展点可以配合插件机制来改变调度决策,例如在执行 Filter 扩展点时,可以使用一批插件来过滤掉不符合当前 Pod 运行条件的 Nodes。
限于篇幅,上述表格中的事件,本文不一定都能分析到,感兴趣的读者可以在读完本文之后,根据兴趣自行阅读相关源代码。
调度整体流程图
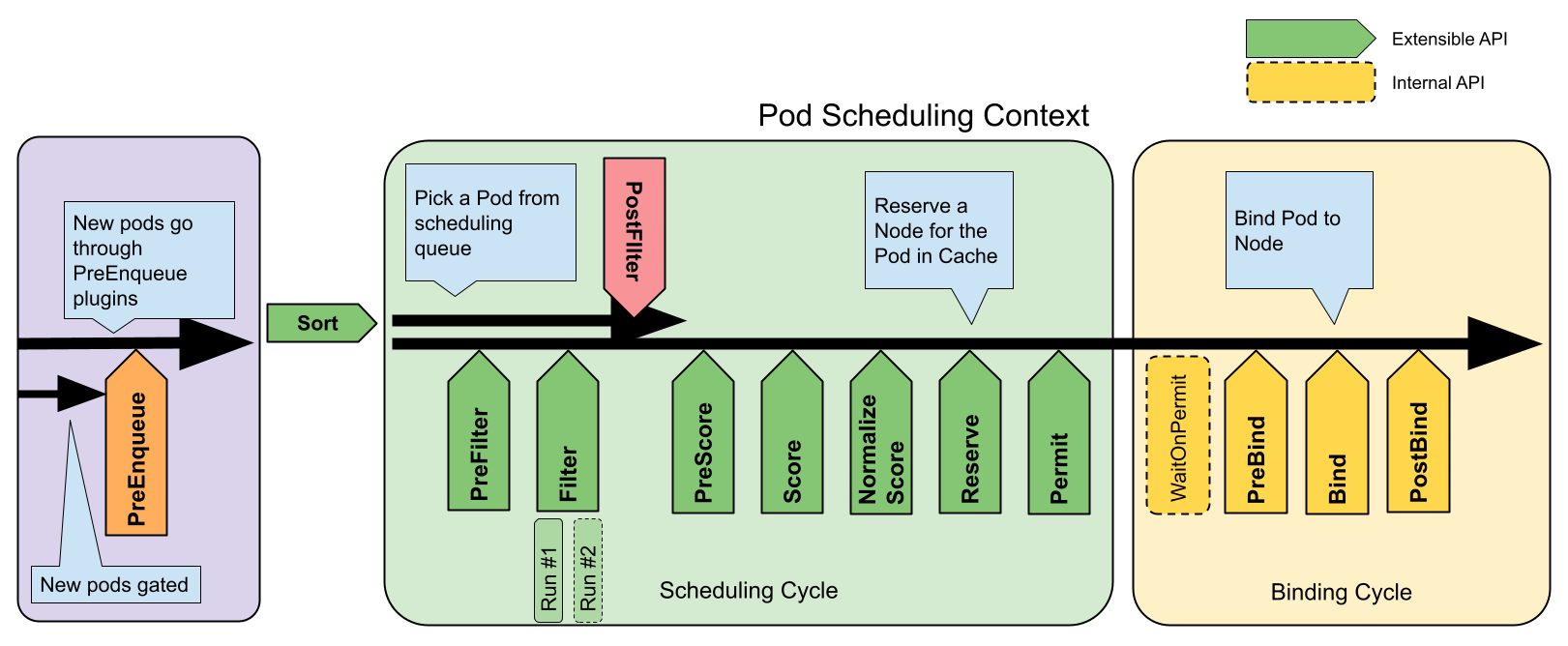
下面我们跟着流程图一起看下源代码的具体实现。
Scheduler 对象
Scheduler (调度器) 对象负责检测未被调度的 Pods, 并尝试为每个 Pod 寻找一个合适的 Node (节点) 运行,然后将 Pod + Node 的绑定关系更新到 ApiServer。
type Scheduler struct {
// 调度器相关的数据缓存对象
Cache internalcache.Cache
// NextPod 方法返回下一个调度的 Pod, 调用方式为阻塞调用
NextPod func(logger klog.Logger) (*framework.QueuedPodInfo, error)
// 调度失败回调方法
// 初始化 Scheduler 对象时
// 使用 Scheduler.handleSchedulingFailure 方法作为默认回调方法
FailureHandler FailureHandlerFn
// SchedulePod 方法尝试从参数 Nodes 列表中为参数 Pod 选择一个合适的 Node
SchedulePod func(ctx context.Context, ...) (ScheduleResult, error)
// 调度器停止 channel
StopEverything <-chan struct{}
// 等待被调度的 Pod 队列
SchedulingQueue internalqueue.SchedulingQueue
// 调度时筛选的 Node 比例 (默认为 50%)
percentageOfNodesToScore int32
// Node 队列索引
nextStartNodeIndex int
// 事件回调方法集合
// 主要用来检测在调度器开始调取之前,所有的回调方法是否已经全部完成初始化
registeredHandlers []cache.ResourceEventHandlerRegistration
}
创建 & 初始化
New 方法用于实例化一个 Scheduler (调度器) 对象并返回。
func New(ctx context.Context, ...) (*Scheduler, error) {
...
// 通过 informer 获取所有 Pods
podLister := informerFactory.Core().V1().Pods().Lister()
// 通过 informer 获取所有 Nodes
nodeLister := informerFactory.Core().V1().Nodes().Lister()
...
// 初始化优先级队列 (PriorityQueue 数据结构)
podQueue := internalqueue.NewSchedulingQueue(
// 将 Pods 加入到队列中
internalqueue.WithPodLister(podLister),
...
)
// 初始化调度器数据缓存
schedulerCache := internalcache.New(ctx, durationToExpireAssumedPod)
// 初始化调度器对象
sched := &Scheduler{
Cache: schedulerCache,
SchedulingQueue: podQueue,
}
// 将队列第一个 Pod 出队
// 作为第一个调度的 Pod
sched.NextPod = podQueue.Pop
// 定义调度失败回调方法
sched.applyDefaultHandlers()
// 注册自定义事件回调处理
if err = addAllEventHandlers(sched, ...); err != nil {
return nil, fmt.Errorf("adding event handlers: %w", err)
}
return sched, nil
}
监听 Node/Pod 变化
addAllEventHandlers 方法主要将各种不同的事件回调处理方法添加到 Scheduler (调度器) 对象上面,这里着重展示监听 Node/Pod 变化的源代码,
func addAllEventHandlers(sched *Scheduler, ...) error {
var (
handlerRegistration cache.ResourceEventHandlerRegistration
err error
// 回调事件处理方法队列
handlers []cache.ResourceEventHandlerRegistration
)
// Pods 变化时的回调处理
if handlerRegistration, err = informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
// Pod 过滤器
FilterFunc: func(obj interface{}) bool {
...
},
// Pod 新增/更新/删除时,更新调度器的对应的缓存
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToCache,
UpdateFunc: sched.updatePodInCache,
DeleteFunc: sched.deletePodFromCache,
},
},
)
// Pods 回调函数方法添加到队列
handlers = append(handlers, handlerRegistration)
// 未调度的 Pods 的回调处理
if handlerRegistration, err = informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
// Pod 过滤器
FilterFunc: func(obj interface{}) bool {
...
},
// 未调度的 Pod 创建/更新/删除时,更新调度器的调度队列
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToSchedulingQueue,
UpdateFunc: sched.updatePodInSchedulingQueue,
DeleteFunc: sched.deletePodFromSchedulingQueue,
},
},
)
// Pods 回调函数方法添加到队列
handlers = append(handlers, handlerRegistration)
// Nodes 变化时的回调处理
if handlerRegistration, err = informerFactory.Core().V1().Nodes().Informer().AddEventHandler(
// Node 新增/更新/删除时,更新调度器的对应的缓存
cache.ResourceEventHandlerFuncs{
AddFunc: sched.addNodeToCache,
UpdateFunc: sched.updateNodeInCache,
DeleteFunc: sched.deleteNodeFromCache,
},
)
// Nodes 回调函数方法添加到队列
handlers = append(handlers, handlerRegistration)
...
// 将事件回调函数集合绑定到调度器对象
sched.registeredHandlers = handlers
return nil
}
注册调度器
目录根路径下面的 scheduler.go 文件中包含调度器的启动入口方法,内部使用 cobra 命令行脚手架注册了具体的初始化执行对象。
func main() {
command := app.NewSchedulerCommand()
code := cli.Run(command)
os.Exit(code)
}
NewSchedulerCommand 方法是脚手架的具体注册方法,其中需要执行的具体的方法为 runCommand。
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
opts := options.NewOptions()
cmd := &cobra.Command{
// 默认调度器名称
Use: "kube-scheduler",
RunE: func(cmd *cobra.Command, args []string) error {
return runCommand(cmd, opts, registryOptions...)
},
}
...
return cmd
}
func runCommand(cmd *cobra.Command, ...) error {
...
// 调用 Setup 方法初始化调度器对象
cc, sched, err := Setup(ctx, opts, registryOptions...)
// 调用 Run 方法启动调度器
return Run(ctx, cc, sched)
}
func Setup(ctx context.Context, ...) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
// 获取调度器的默认配置
if cfg, err := latest.Default(); err != nil {
return nil, nil, err
} else {
opts.ComponentConfig = cfg
}
...
// 创建调度器对象
sched, err := scheduler.New(ctx,
...
)
return &cc, sched, nil
}
启动调度器
Run 方法根据参数配置和调度器对象运行调度过程,方法内部会执行一系列必要的初始化和检测工作,最后调用参数 Scheduler.Run 方法真正执行调度过程。
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
startInformersAndWaitForSync := func(ctx context.Context) {
// 启动所有 Informer
cc.InformerFactory.Start(ctx.Done())
// 开始调度过程之前等待所有缓存数据初始化完成
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// 开始调度过程之前等待所有事件回调方法注册完成
if err := sched.WaitForHandlersSync(ctx); err != nil {
}
}
...
// 调用 Scheduler.Run 方法
sched.Run(ctx)
...
}
func (sched *Scheduler) Run(ctx context.Context) {
// 启动调度队列
// 默认的实现是一个优先队列,该队列了实现了 Pod 的 添加/更新/删除/获取 等操作
// 为了节省篇幅,这里先不对队列源代码实现展开分析
sched.SchedulingQueue.Run(logger)
// 单独启动一个 goroutine 用于处理调度逻辑
// 因为每次获取要调度的 Pod 时,获取操作本身是阻塞式的
// 如果没有新的 Pod 需要调度,操作就会阻塞
// 同时启动新的 goroutine 可以防止在 context 收到信号时发生死锁
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
// 等待 context 结束
<-ctx.Done()
// 关闭调度队列
sched.SchedulingQueue.Close()
}
执行调度
Scheduler.scheduleOne 是实现调度逻辑 (工作流) 的具体方法,每次调用该方法时,会从 调度队列 中取出一个等待调度的 Pod, 然后为该 Pod 选择一个合适的 Node 执行。
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// 从调度队列中获取等待调度的 Pod
podInfo, err := sched.NextPod(logger)
pod := podInfo.Pod
// 各种异常状态检测
...
// 计算 & 选择一个适合 Pod 运行的 Node
scheduleResult, assumedPodInfo, status := sched.schedulingCycle(schedulingCycleCtx, ...)
if !status.IsSuccess() {
// 调度失败回调
sched.FailureHandler(schedulingCycleCtx, ...)
return
}
// 绑定 Pod 和 Node 的关系
// 注意这里的绑定操作是异步执行的
go func() {
...
// 绑定 Pod 和 Node
status := sched.bindingCycle(bindingCycleCtx, ...)
if !status.IsSuccess() {
// 绑定关系操作失败
sched.handleBindingCycleError(bindingCycleCtx, ...)
return
}
// 将 Pod 标记为已完成调度
sched.SchedulingQueue.Done(assumedPodInfo.Pod.UID)
}()
}
选择 Node 节点
Scheduler.schedulingCycle 方法是 Pod 选取 Node 节点过程的调用入口。
func (sched *Scheduler) schedulingCycle(ctx context.Context, ...) (...) {
pod := podInfo.Pod
// 为 Pod 筛选适合运行的 Node
scheduleResult, err := sched.SchedulePod(ctx, fwk, state, pod)
// 如果发生了错误,说明没有合适的 Node
if err != nil {
// 如果已经没有可用的 Nodes 了,直接返回
...
// 运行过滤插件 {执行后的钩子方法} ...
...
return ...
}
// 记录筛选 Node 过程的 Metric
...
}
Scheduler.schedulePod 方法尝试从参数 Nodes 列表中为参数 Pod 选择一个合适的 Node, 如果能匹配到合适的 Node 就直接返回,如果匹配不到就返回具体的匹配失败原因。
节点选择的过程主要分为两步:
- [预筛选] 筛选出符合条件的 Nodes
- [打分排序] 对筛选出来的 Nodes 进行打分,最后得分最高的 Node 就是 Pod 要调度的目标 Node
func (sched *Scheduler) schedulePod(ctx context.Context, ..., pod *v1.Pod) (result ScheduleResult, err error) {
...
// [预筛选] 先筛选出符合条件的 Nodes
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
// 如果没有符合条件的 Node, 直接返回失败原因
if len(feasibleNodes) == 0 {
return result, &framework.FitError{
...
}
}
// 如果符合条件的 Node 只有 1 个
// 嫁鸡随鸡,嫁狗随狗了 :-)
if len(feasibleNodes) == 1 {
return ScheduleResult{
...
}, nil
}
// 再来一波优先级打分排序
priorityList, err := prioritizeNodes(ctx, ...)
// [打分排序] 从打分排序完成的列表中择优录取 Node 返回
host, _, err := selectHost(priorityList, numberOfHighestScoredNodesToReport)
return ScheduleResult{
...
}, err
}
预筛选过程
Scheduler.findNodesThatFitPod 方法根据过滤插件和过滤扩展,筛选出适合 Pod 运行的 Node 列表。
func (sched *Scheduler) findNodesThatFitPod(ctx context.Context, ..., pod *v1.Pod) ([]*v1.Node, ...) {
// 获取所有的 Nodes
allNodes, err := sched.nodeInfoSnapshot.NodeInfos().List()
// 运行预处理插件过滤 Nodes
preRes, s := fwk.RunPreFilterPlugins(ctx, state, pod)
...
nodes := allNodes
if !preRes.AllNodes() {
nodes = make([]*framework.NodeInfo, 0, len(preRes.NodeNames))
// 遍历预处理插件过滤完的 Nodes
// 逐个获取 Node 对象并追加到 Nodes 列表中
for n := range preRes.NodeNames {
nInfo, err := sched.nodeInfoSnapshot.NodeInfos().Get(n)
if err != nil {
return nil, diagnosis, err
}
nodes = append(nodes, nInfo)
}
}
// 运行过滤插件过滤 Nodes
feasibleNodes, err := sched.findNodesThatPassFilters(ctx, ..., nodes)
// 更新调度器的 Nodes 列表读取索引
// 保证每个 Node 都有机会被选取 & 调度
processedNodes := len(feasibleNodes) + len(diagnosis.NodeToStatusMap)
sched.nextStartNodeIndex = (sched.nextStartNodeIndex + processedNodes) % len(nodes)
// 运行过滤扩展再次过滤 Nodes
feasibleNodes, err = findNodesThatPassExtenders(ctx, ...)
return feasibleNodes, diagnosis, nil
}
计算参与过滤的 Nodes 数量
一个 Kubernetes 集群中少则几十个 Nodes, 多则好几千 Nodes, 如果每次过滤时所有的 Nodes 都参与,那么这个计算量就太耗时了,严重甚至会影响 Pod 的调度性能。
为了避免这个问题,每次过滤时都会调用 Scheduler.numFeasibleNodesToFind 方法计算出一个数量值,作为参与过滤的 Nodes 数量。
const (
minFeasibleNodesToFind = 100
minFeasibleNodesPercentageToFind = 5
)
func (sched *Scheduler) numFeasibleNodesToFind(percentageOfNodesToScore *int32, numAllNodes int32) (numNodes int32) {
// 如果节点数量少于 100 个
// 几乎没什么性能影响,直接返回
if numAllNodes < minFeasibleNodesToFind {
return numAllNodes
}
// 计算要参与过滤的 Pos 比例
// 如果参数中没有设置,就以调度器对象的配置字段为准 (50%)
var percentage int32
if percentageOfNodesToScore != nil {
percentage = *percentageOfNodesToScore
} else {
percentage = sched.percentageOfNodesToScore
}
if percentage == 0 {
percentage = int32(50) - numAllNodes/125
// 参与过滤的 Nodes 数量最少为 5 个
if percentage < minFeasibleNodesPercentageToFind {
percentage = minFeasibleNodesPercentageToFind
}
}
numNodes = numAllNodes * percentage / 100
if numNodes < minFeasibleNodesToFind {
// 参与过滤的 Nodes 数量最少为 100 个
return minFeasibleNodesToFind
}
return numNodes
}
过滤插件
Scheduler.findNodesThatPassFilters 方法运行过滤插件,筛选出适合 Pod 运行的 Nodes。
从数据结构的角度来看,整个 “执行插件过滤 -> 筛选 Nodes” 的过程就是一个典型的 MapReduce 计算,然后结合源代码中的多个 goroutine 并行计算,
最后的流程图如下所示。
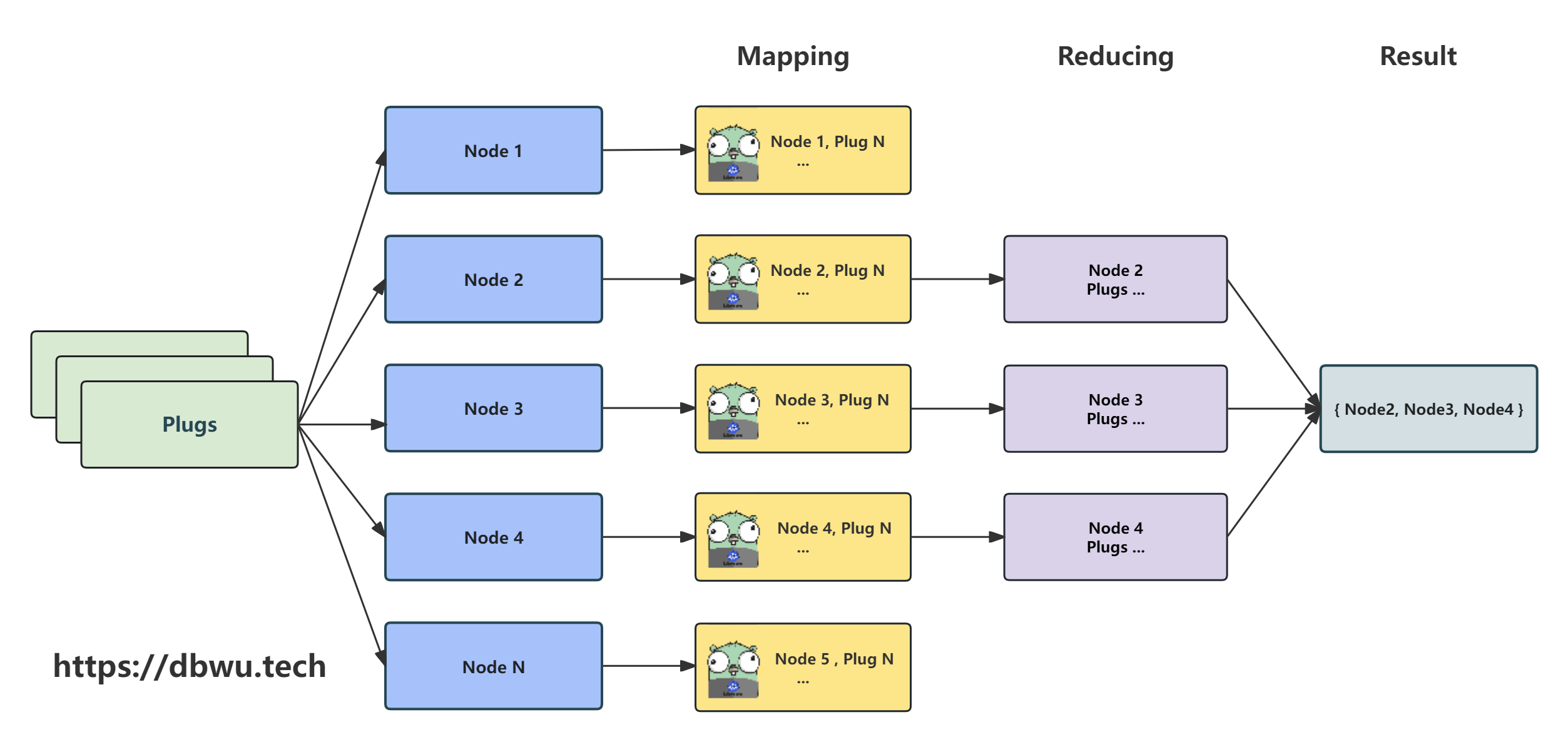
func (sched *Scheduler) findNodesThatPassFilters(ctx context.Context, pod *v1.Pod, ... nodes []*framework.NodeInfo) ([]*v1.Node, error) {
// 计算参数 Nodes 的数量
numAllNodes := len(nodes)
// 计算参与过滤条件的 Nodes 数量
numNodesToFind := sched.numFeasibleNodesToFind(fwk.PercentageOfNodesToScore(), int32(numAllNodes))
// 初始化返回结果 Nodes 列表
feasibleNodes := make([]*v1.Node, numNodesToFind)
// 如果没有注册过滤插件
// 事情就变得简单了,直接从调度器的 Nodes 队列中根据索引,返回具体数量的 Nodes 即可
if !fwk.HasFilterPlugins() {
for i := range feasibleNodes {
feasibleNodes[i] = nodes[(sched.nextStartNodeIndex+i)%numAllNodes].Node()
}
return feasibleNodes, nil
}
...
// 并行过滤中,单个 goroutine 中的执行 (回调) 方法
// 参数 i 就是调度器的 Nodes 队列中的索引
// 起始索引就是上一轮调度结束的索引 “偏移量”
checkNode := func(i int) {
// 根据参数 i 获取队列中对应的 Node 对象
nodeInfo := nodes[(sched.nextStartNodeIndex+i)%numAllNodes]
// 运行过滤插件检测 Node 是否合适
status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
if status.IsSuccess() {
// 每当有一个 Node 通过检测时
// 计数器原子操作 + 1
length := atomic.AddInt32(&feasibleNodesLen, 1)
if length > numNodesToFind {
// 如果通过检测的 Node 数量大于 {参与过滤条件的 Nodes 数量}
// 说明当前这轮调度需要的 Node 数量已经足够了
// 此时并行任务退出即可
// 执行 cancel() 通知其他并行的 goroutine 结束 (所有并行的 goroutine 共享一个 Context 对象)
cancel()
atomic.AddInt32(&feasibleNodesLen, -1)
} else {
// 为对应的 Nodes 结果列表中对应的索引赋值
feasibleNodes[length-1] = nodeInfo.Node()
}
}
...
}
// 调度过程记录 Metric
// 启动并行过滤
fwk.Parallelizer().Until(ctx, numAllNodes, checkNode, metrics.Filter)
feasibleNodes = feasibleNodes[:feasibleNodesLen]
return feasibleNodes, nil
}
打分排序过程
prioritizeNodes 方法通过一系列打分插件和扩展对参数 Nodes 进行打分,来确定 Node 的优先级,返回的结果 Nodes 列表中的每个 Node 都有一个对应的权重 (分数)。
func prioritizeNodes(ctx context.Context, ..., pod *v1.Pod, nodes []*v1.Node) ([]framework.NodePluginScores, error) {
// 如果打分插件和扩展都为空
// 那么所有的 Nodes 的权重都是 1
// 直接返回即可
if len(extenders) == 0 && !fwk.HasScorePlugins() {
result := make([]framework.NodePluginScores, 0, len(nodes))
for i := range nodes {
result = append(result, framework.NodePluginScores{
Name: nodes[i].Name,
TotalScore: 1,
})
}
return result, nil
}
// 运行打分前的预处理插件
preScoreStatus := fwk.RunPreScorePlugins(ctx, state, pod, nodes)
// 运行打分插件
nodesScores, scoreStatus := fwk.RunScorePlugins(ctx, state, pod, nodes)
// 记录 Nodes 分数日志
...
// 运行打分扩展,继续打分
if len(extenders) != 0 && nodes != nil {
...
for i := range extenders {
...
}
...
}
...
return nodesScores, nil
}
根据打分结果选取 Node
selectHost 方法根据打完分数的 Nodes 列表,选取一个最适合 Pod 运行的 Node 并返回。
注意: 如果存在多个 Nodes 分数一样时,会将多个 Nodes 列表一起返回,但是会进行简单的随机处理 (提升负载均衡), 这样最后返回结果中 Pod 的目标 Node 仍然是列表中的第一个元素。
func selectHost(nodeScoreList []framework.NodePluginScores, count int) (string, []framework.NodePluginScores, error) {
var h nodeScoreHeap = nodeScoreList
// 使用堆排序
heap.Init(&h)
// 初始化返回结果 Nodes 列表
sortedNodeScoreList := make([]framework.NodePluginScores, 0, count)
// 现将堆中的最高分 Node 加入到返回结果列表中
sortedNodeScoreList = append(sortedNodeScoreList, heap.Pop(&h).(framework.NodePluginScores))
// 寻找和最高分数值相同的所有 Nodes
for ns := heap.Pop(&h).(framework.NodePluginScores); ; ns = heap.Pop(&h).(framework.NodePluginScores) {
if ns.TotalScore != sortedNodeScoreList[0].TotalScore && len(sortedNodeScoreList) == count {
break
}
// 如果当前元素 Node 和最高分 Node 分数值一样
// 从两个 Node 中随机选择一个作为返回结果中的目标 Node,提升负载均衡
if ns.TotalScore == sortedNodeScoreList[0].TotalScore {
cntOfMaxScore++
if rand.Intn(cntOfMaxScore) == 0 {
selectedIndex = cntOfMaxScore - 1
}
}
sortedNodeScoreList = append(sortedNodeScoreList, ns)
if h.Len() == 0 {
break
}
}
if selectedIndex != 0 {
// 存在和最高分 Node 分数值一样的 Node
// 直接交换两者
// 感觉代码作者对 Go 语言语法不熟悉?
// 下面的 3 行代码可以缩减为 1 行
previous := sortedNodeScoreList[0]
sortedNodeScoreList[0] = sortedNodeScoreList[selectedIndex]
sortedNodeScoreList[selectedIndex] = previous
}
return sortedNodeScoreList[0].Name, sortedNodeScoreList, nil
}
调度失败
Scheduler.handleSchedulingFailure 方法是调取失败时的回调方法,方法内部主要做两件事情:
- 记录调度失败的 Pod 对象信息、失败原因、失败日志
- 将调度失败的 Pod 重新加入调度器的队列
func (sched *Scheduler) handleSchedulingFailure(ctx context.Context, ...) {
// 记录日志
...
// 尝试通过 informer 的缓存获取 Pod 列表
podLister := fwk.SharedInformerFactory().Core().V1().Pods().Lister()
// 从 Pod 列表中根据名字获取对应的 Pod
cachedPod, e := podLister.Pods(pod.Namespace).Get(pod.Name)
if e != nil {
...
} else {
...
if len(cachedPod.Spec.NodeName) != 0 {
// Pod 已经分配到 Node 了
} else {
// 将 Pod 加入到调度器的队列中
podInfo.PodInfo, _ = framework.NewPodInfo(cachedPod.DeepCopy())
if err := sched.SchedulingQueue.AddUnschedulableIfNotPresent(logger, podInfo, ...); err != nil {
...
}
}
}
...
}
小结
本文从源代码的角度,分析了 Kubernetes 中默认调度器的核心调度流程,并对流程中的扩展点 (事件)、过滤插件、打分机制做了简答的概述,限于篇幅,
有几个重要的知识点没有展开分析,例如 调度器队列、 扩展点 + 插件过滤机制、 调度过程中的串行/并行执行机制 这些重要的设计,接下来,
笔者会在本文的基础上进一步分析这几个重要功能的实现,并输出单独的文章。希望可以帮助读者了解并熟悉调度器的主体流程,并在此基础上根据自己的兴趣深入研究。
FAQ
1. 为什么 绑定周期 可以并行执行,而 调度周期 只能串行执行?
因为根据当前调度器的设计,通过预筛选过程和打分排序过程筛选出来的 Node, 无法保证并发安全,例如筛选出来的 Node 在并发场景下可能被多个 Pod 绑定。
2. 调度器的核心并发数量居然为 1 ?
从前文中的 scheduleOne 方法的源代码可以看到,整个调度只有一个 goroutine 用于调用 scheduleOne 方法。而针对这个问题,
云原生社区中有人使用 kubemark
模拟 2000 个节点的规模来压测 调度器 的处理性能及时延, 测试结果是 30s 内完成了 15000 个 Pod 调度任务。
此外,虽然 调度器 是单并发模型, 但由于预筛选过程和打分排序过程都属于计算型任务非阻塞 IO,
最重要的是绝大部分场景中创建 Pod 的操作通常不会太频繁. 综上所述,即使调度器的的并发数量为 1, 从性能方面来说也是可以接受的。
3. Pod 处于 pending 状态且事件信息显示 failedScheduling ?
如果调度器找不到任何可以运行该 Pod 的节点,会将该 Pod 标记为不可调度状态,直到出现一个可以被调度到的节点。
出现这种情况时,可以尝试进行如下操作:
- 检查节点容量和已分配的资源数量 (kubectl describe nodes)
- 向集群添加更多节点
- 终止不需要的 Pod,为不可调度的 Pod 节省出运行资源
- 考虑是否可以降低 Pod 所需的申请运行资源
- 检查节点上的污点和 Pod 容忍度是否存在冲突
Reference
- Kubernetes Scheduling Framework
- Scheduler
- Scheduling Framework
- Scheduler code hierarchy overview
- 源码分析 kubernetes scheduler 核心调度器的实现原理
