I/O 模型的阻塞/非阻塞, 同步/异步
I/O 模型
Unix 有五种 I/O 模型
- 阻塞式 I/O
- 非阻塞式 I/O
- I/O 多路复用(select, poll, epoll)
- 信号驱动式 I/O
- 异步 I/O(AIO)
1. 阻塞式 I/O
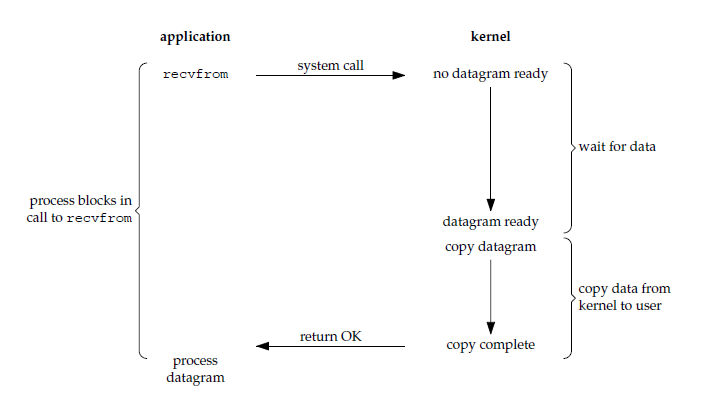
应用进程执行系统调用时被阻塞,直到数据从内核缓冲区复制到应用进程缓冲区中才返回。
阻塞不意味着整个操作系统都被阻塞,在阻塞的过程中,其它应用进程还可以执行,所以阻塞本身不消耗 CPU 时间,这种模型的 CPU 利用率会比较高。
下面将 阻塞式 I/O 工作流程翻译为简单的伪代码。
while True:
# 阻塞等待客户端连接
connection, client_address = sock.accept()
try:
while True:
# 阻塞等待数据
# 读取数据
data = connection.recv(16)
# 执行其他操作
2. 非阻塞式 I/O
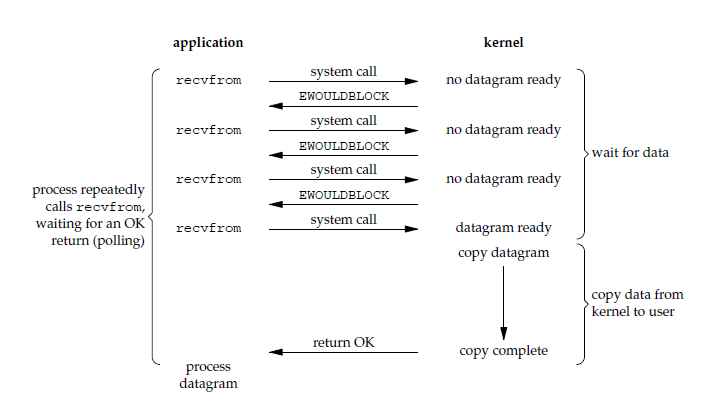
应用进程执行系统调用时,内核直接返回一个错误码,然后应用进程可以继续向下运行,但是需要不断的执行系统调用来获取 I/O 操作是否完成,也称为轮询(polling)。
由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低。
下面将 非阻塞式 I/O 工作流程翻译为简单的伪代码。
while True:
try:
# 内核直接返回一个错误吗
connection, client_address = sock.accept()
# 继续向下执行
connection.setblocking(0)
except BlockingIOError:
# 处理错误
...
try:
# 读取数据
data = connection.recv(16)
# 执行其他操作
...
except BlockingIOError:
# 处理错误
...
3. I/O 多路复用
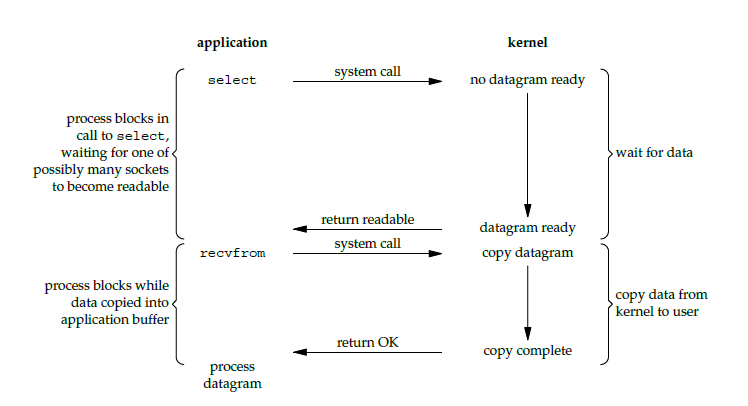
使用 select, poll, epoll 等待多个套接字 (文件描述符) 中的任何一个或多个变为就绪,等待过程会阻塞,当某一个套接字就绪后,再把数据从内核空间 (缓冲期) 复制数据到用户空间 (进程) 。当然,epoll 的工作方式和 select, poll 有些差异,不过这里先不做细节上的深究,统一当作 I/O 多路复用的实现来看待。
这种模型可以让单个 进程/线程 具有处理多个 I/O 事件的能力,也称为事件驱动 I/O。
如果一个 Web Server 没有 I/O 多路复用,那么每一个 Socket 连接都需要创建一个线程去处理,如果同时有几万个连接,那么就需要创建相同数量的线程 (可能导致的后果就是操作系统直接崩溃),相比之下,I/O 多路复用不需要多个进程/线程创建、上下文切换的开销,系统负载更小。
下面将 I/O 多路复用 工作流程翻译为简单的伪代码。
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = ('localhost', 8080)
...
inputs = [sock]
outputs = []
while inputs:
# 阻塞等待套接字就绪
readable, writable, exceptional = select.select(inputs, outputs, inputs)
# 获取到已经就绪的套接字
# 遍历处理读事件
for s in readable:
...
# 遍历处理写事件
for s in writable:
...
# 遍历处理其他事件
for s in exceptional:
...
4. 信号驱动 I/O
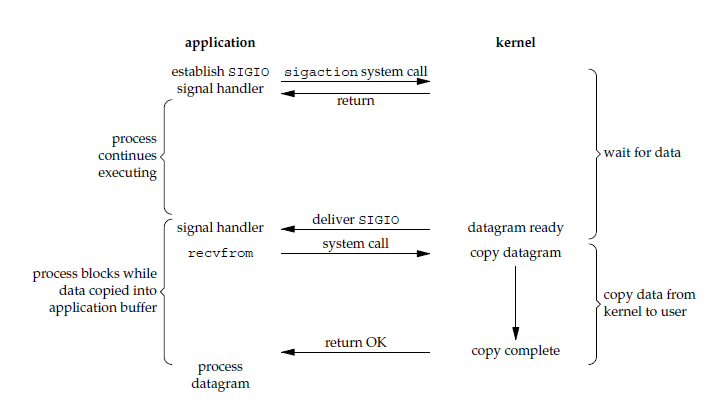
应用进程执行系统调用时,内核直接返回,然后应用进程可以继续向下运行,也就是说等待数据阶段应用进程是非阻塞的。
内核在数据到达时向应用进程发送信号,应用进程收到信号之后,在信号处理程序中执行系统调用,将数据从内核空间 (缓冲期) 复制数据到用户空间 (进程),这种模型的 CPU 利用率会比较高。
# 信号回调函数
def handler(signum, frame):
# 读取数据
data, addr = sock.recvfrom(1024)
# 执行其他操作
...
# 初始化 socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('localhost', 8080))
...
# 注册信号回调函数
signal.signal(signal.SIGIO, handler)
...
while True:
# 等待信号通知
signal.pause()
5. 异步 I/O
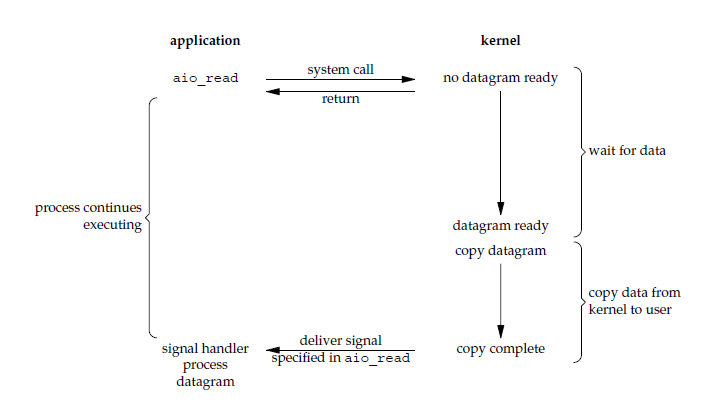
应用进程执行系统调用时,内核直接返回,然后应用进程可以继续向下运行,不会被阻塞,内核会在所有操作 (包括从内核空间复制数据到用户空间) 完成之后向应用进程发送信号。
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O (数据复制) 已经完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O (数据复制) 。
# 异步回调函数
# 通知应用进程 I/O (数据复制) 已经完成
async def handle_client(reader, writer):
while True:
# 直接读取数据即可
data = await reader.read(100)
# 执行其他操作
...
writer.close()
async def main():
# 监听端口并注册异步回调函数
server = await asyncio.start_server(handle_client, 'localhost', 10000)
阻塞/非阻塞,同步/异步
如何判断一个 I/O 模型是同步还是异步?
I/O 事件数据在内核空间和用户空间来回复制时,是否会阻塞当前线程?
如果会阻塞当前线程,则为同步 I/O, 否则就是异步 I/O。
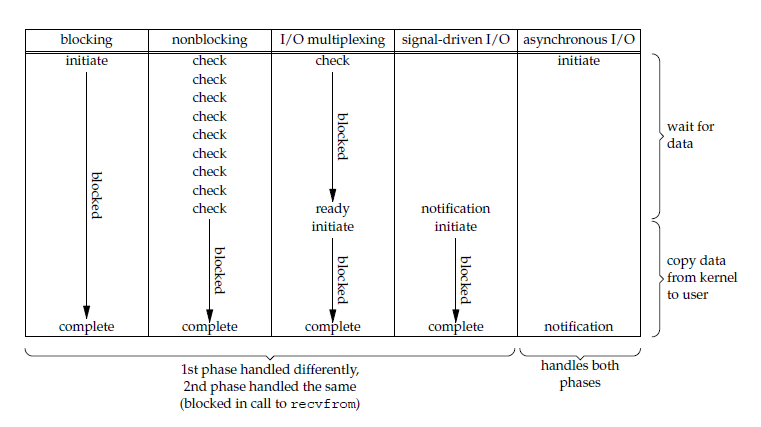
所以前文中提到的 5 种 I/O 模型中,只有最后 1 种 异步 I/O 模型 是真正的异步 I/O, 其他 4 种都是同步 I/O。
一个 I/O 读取操作通常包括两个步骤:
- 等待网络数据到达网卡(读就绪) -> 等待网卡可写(写就绪) –> 读取/写入到内核缓冲区
- 从内核空间缓冲区复制数据 –> 用户空间(读), 或者 从用户空间 (进程) 复制数据 -> 内核缓冲区(写)
4 种同步 I/O 模型的主要区别在 I/O 操作的第一步: 等待网络数据到达网卡(读就绪) -> 等待网卡可写(写就绪) –> 读取/写入到内核缓冲区,除了 阻塞式 I/O 模型外,其他 3 种同步 I/O 模型在第一步不会发生阻塞。
换句话说,只有 阻塞式 I/O 模型是阻塞的,其他 3 种模型都是非阻塞的。
小结
阻塞 / 非阻塞的主语是 I/O 操作调用者(应用进程),而同步 / 异步的主语是 I/O 操作执行者(操作系统)。
| I/O 模型 | 是否阻塞 | 是否同步 |
|---|---|---|
| 阻塞式 I/O | ✅ | ❌ |
| 非阻塞式 I/O | ❌ | ❌ |
| I/O 多路复用 | ❌ | ❌ |
| 信号驱动式 I/O | ❌ | ❌ |
| 异步 I/O | ❌ | ✅ |
