TCP 可靠传输实现原理 - 2.滑动窗口 (流量控制)
2018-12-25 计算机网络
概述
TCP 实现可靠传输层的核心有三点:
- 确认与重传 (已经可以满足 “可靠性”,但是可能存在性能问题)
- 滑动窗口 (也就是流量控制,为了提高吞吐量,充分利用链路带宽,避免发送方发的太慢)
- 拥塞控制 (防止网络链路过载造成丢包,避免发送方发的太快)
滑动窗口和拥塞控制相互制约,使发送方可以从网络链路的全局角度来自动调整发送速率,从这个角度来看,TCP 对于整个网络的意义已经超过 “传输层”。
本文主要讲解三个核心中的第二点: 滑动窗口。
滑动窗口主要关注发送方到接收方的流量控制
拥塞控制更多地关注整个网络 (链路) 层面的流量控制
前置知识点
在讲解 TCP 的确认与重传之前,先来复习几个基本知识点。
所谓发送方和接收方,只是一个相对的概念。
- 客户端向服务端发送数据时,客户端是发送方,服务端是接收方
- 服务端向客户端发送数据时,客户端是接收方,服务端是发送方
1. 发送窗口
发送方已经发送但是还未收到确认的最大数据量,由接收方的接收窗口大小 和 网络上的拥塞窗口大小 (cwnd, 后面专门写一篇文章写拥塞控制) 限制。
发送窗口是发送方维护的一个数据结构,并根据接收方的通知动态调整。
如图所示,发送窗口为 1 个 MSS 和 2 个 MSS时 的差别,在相同的往返时间里,右边比左边多发了两倍的数据量。
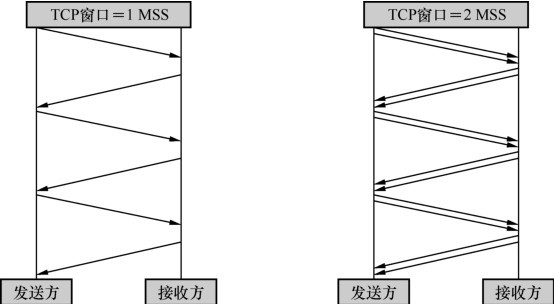
发送窗口和 MSS 有什么关系?
发送窗口决定了一口气能发送多少字节,而 MSS 决定了这些字节需要分多少个数据包发送完。
在发送窗口为 16000 字节的情况下:
- 如果 MSS 等于 1000 字节,需要发送 16000/1000=16 个数据包
- 如果 MSS 等于 8000 字节,需要发送 16000/8000=2 个数据包
将网络链路/带宽比做高速公路,发送窗口大小就是货车的数量,只要窗口足够大 (货车足够多),TCP 可以不受往返时间的约束而源源不断地传输数据,所以无论在局域网还是广域网,TCP 依然是最受欢迎的传输层协议。
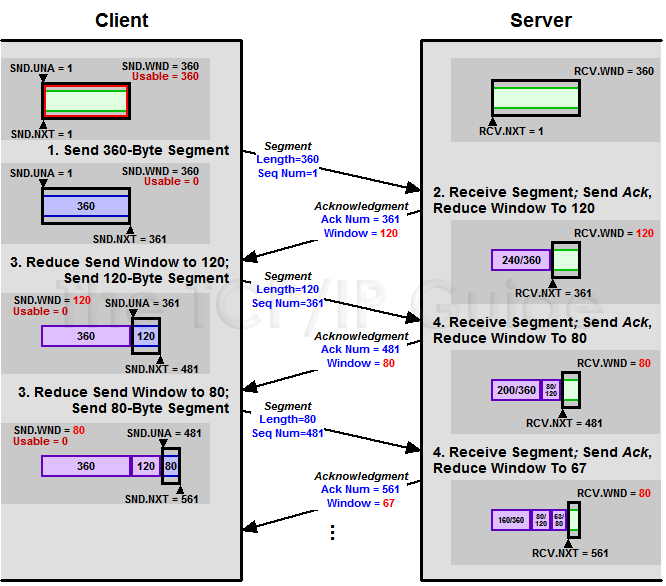
2. 接收窗口
接收方可以接收但是未确认的最大数据量,由接收方根据自身接收能力和缓冲区大小来决定。
接收窗口会通过 Ack 报文通知发送方,防止发送方发送过多数据导致缓冲区溢出而丢包。也就是说,当接收方收到接收窗口范围之外 (包括延时到达) 的数据包,会直接丢弃。
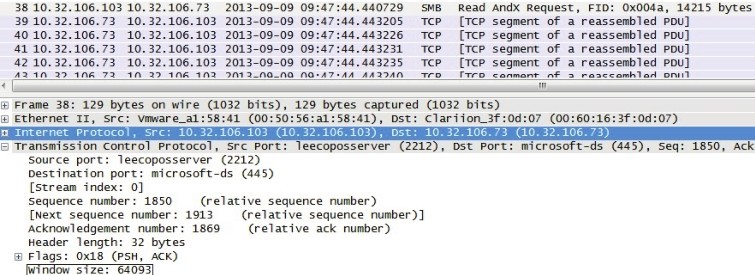
如图所示,10.32.106.103 告诉 10.32.106.73 自己的接收窗口是 64093 字节,10.32.106.73 收到之后,就会把自己的发送窗口限制在 64093 字节内。
接收窗口变为 0 之后,发送方就不再发送数据了,但是等接收方处理了缓冲区数据后,又可以再次接收数据了,此时如何通知发送方呢?
TCP 使用了 零窗口探测 (ZWP, Zero Window Probe) 来解决这个问题,发送方在接收窗口为 0 之后,周期性地发送一个字节的数据包(通常是已经发送过但未被确认的最后一个字节),这些小的数据包用于检测接收方的接收窗口是否已经变为非零大小,如果接收窗口变为非零,发送方就可以继续发送数据了。
滑动窗口
在 上篇文章 中,我们详细讲解了 TCP 的数据确认和重传机制,这是 TCP 实现可靠传输的基础。
但是在实现可靠传输的同时,是否可以在不造成网络拥堵、数据丢包的前提下,尽可能提高吞吐量,充分利用链路带宽呢?要实现这个目标,TCP 必须了解网络链路实际的传输带宽、处理速率、瓶颈节点等关键因素,为此,TCP 引入了 滑动窗口 机制。
有了前文中的 发送窗口 和 接收窗口 基础之后,滑动窗口理解起来就简单多了。
发送方的滑动窗口基于发送窗口,由接收方的接收窗口大小和拥塞窗口 (后面专门写一篇文章讲拥塞控制) 大小来决定。
$$ 发送窗口大小 (swnd) = min(接收窗口大小 (rwnd), 拥塞窗口大小(cwnd) ) $$
通过动态调整 滑动窗口 大小,实现了 (发送方到接收方的) 流量控制:
- 窗口缩小: 如果接收方缓冲区不足,会减小接收窗口大小,通知发送方减缓发送速率
- 窗口扩大: 如果接收方缓冲区充足,会增大接收窗口大小,通知发送方提升发送速率
下面是两个典型的滑动窗口过程示例:
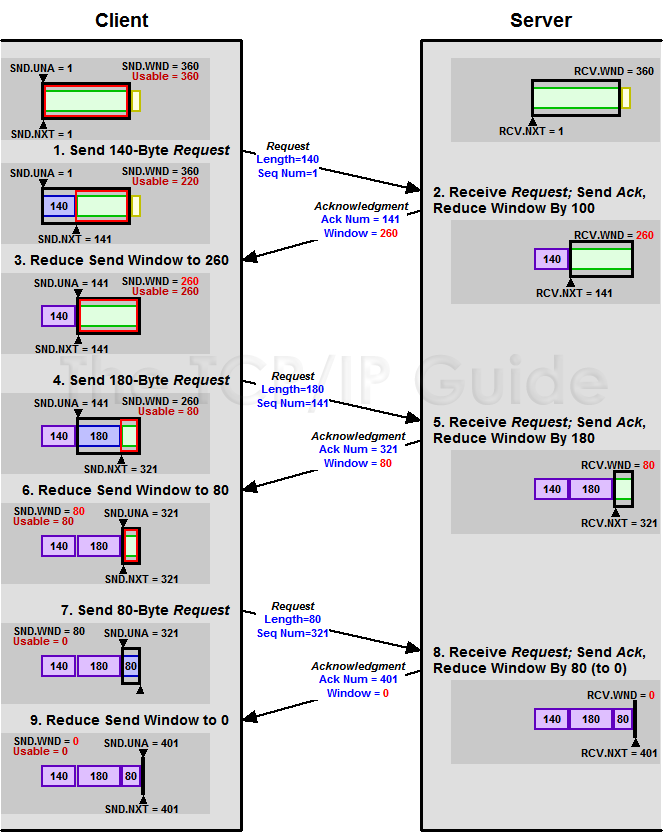
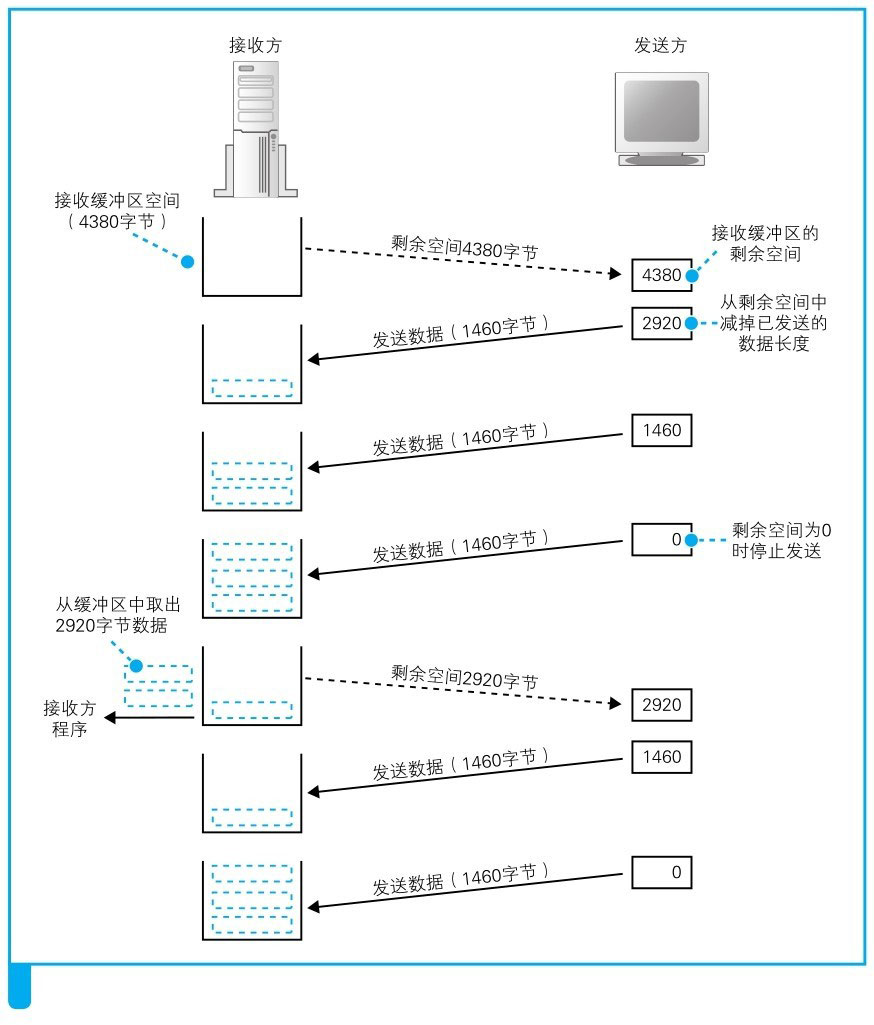
示例
当发送方收到接收方的 Ack 应答后,发送窗口会向前滑动,释放已经被 Ack 的数据段,允许新的数据段进入发送窗口。
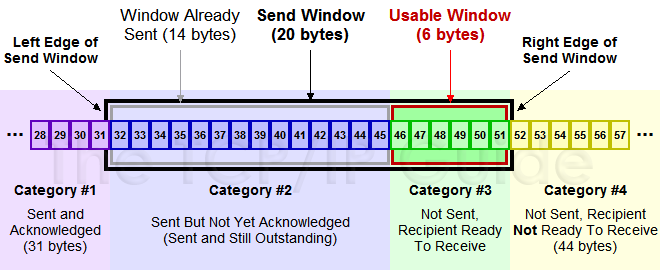
如图所示是一个典型的窗口示例,主要分成了 4 个部分:
- Category #1: 接收方已经确认的数据
- Category #2: 已经发送,但是接收方还未确认的数据 (属于发送窗口)
- Category #3: 发送窗口中已经可以发送、但是还未发送的数据 (属于发送窗口)
- Category #4: 发送窗口之外的数据
其中,黑色方框部分就是 发送窗口,每确认一部分数据后,窗口就会向前移动,添加一部分新数据,然后准备发送。
例如,当接收方确认了 32, 33, 34 号数据包之后,发送方就可以发送 46, 47, 48 号数据包,然后窗口向前移动 3 个,将 52, 53, 54 号数据包加入到窗口中。
示例 2
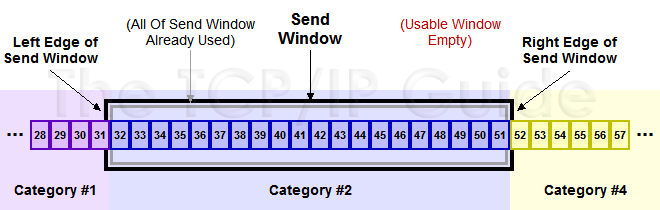
如图所示,发送窗口中的数据已经全部发送,但是没有收到接收方的任何 Ack 确认,所以窗口无法向前滑动,只能等待接收方的 Ack。
示例 3
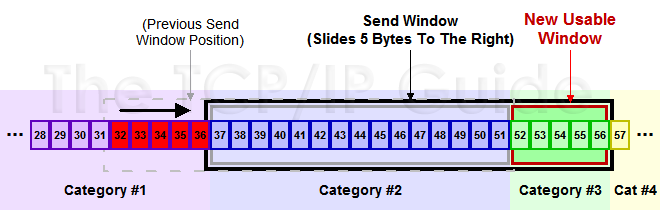
如图所示,收到接收方对 32 - 36 的 5 个数据包的 Ack 之后,窗口向前滑动 5 个数据包,发送了 46 - 51 的 5 个数据包,同时将 52 - 56 的 5 个数据包加入到窗口中准备发送。
Zero Window
如果接收方处理数据包的速度落后发送方发送数据的速度,接收方缓冲区就会占满,然后通知发送方接收窗口为 0。

如图所示的 Wireshark 抓包截图,89.0.0.85 持续向 89.0.0.210 声明自己的接收窗口 win=0,所以 89.0.0.210 的发送窗口就被限制为0,也就是暂停发送数据。Wireshark 会智能地给数据包打上 TCP Zero Window 标签。
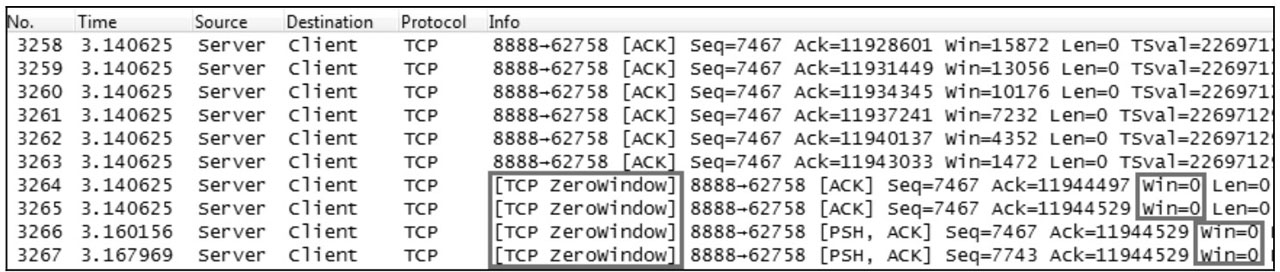
如图所示的 Wireshark 抓包截图,可以看到接收窗口逐渐减少的过程,直到最后接收方缓存区已满,通知发送方接收窗口为 0。
Window Full
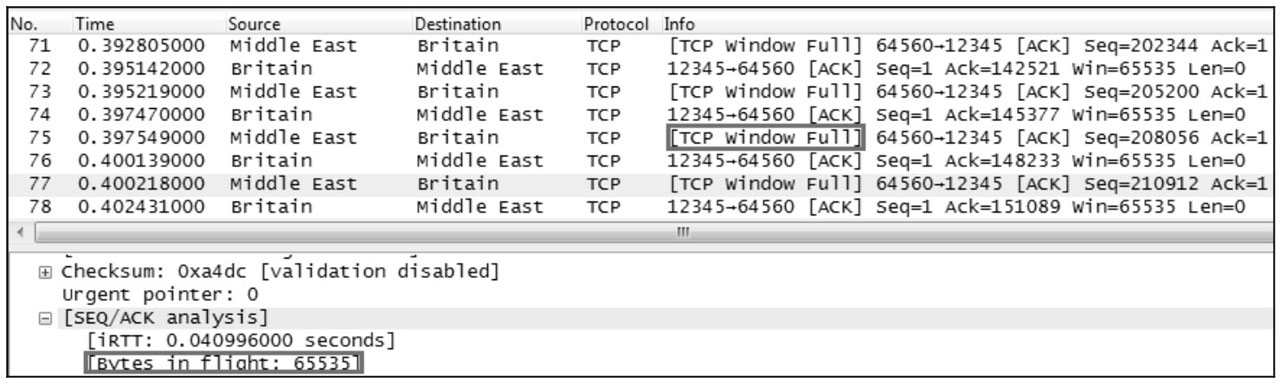
如图所示的 Wireshark 抓包截图,当一个数据包被打上 TCP Window Full 标签时,表示数据包的发送方已经将发送窗口中的数据包全部发送完了,但是还未收到任何确认。
Britain 一直声明它的接收窗口只有 65535,意味着 Middle East 最多能给它发送 65535 字节的数据而无需确认,当 Wireshark 在数据包中计算出 Middle East 已经有 65535 字节未被 Britain 确认时,就会出现 TCP Window Full, 此时 Middle East 应该暂停发送数据。
Window Full 很容易和 Zero Window 混淆,两者之间有一定相似之处:
- Window Full 表示这个 数据包的发送方 告诉接收方,暂时不会再发送数据了
- Zero Window 表示这个 数据包的发送方 告诉接收方,暂时不能再接收数据了
也就是说两者都意味着数据传输暂停,同样需要引起重视。
Nagle 算法
算法原理:发送方已经发送数据还未被接收方确认之前,期间如果又有小数据生成,先把小数据收集起来,凑满一个 MSS (最大报文段大小) 或者收到接收方 Ack 后再一起发送。通过将小数据包积累成较大的数据包后再发送,从而提高网络效率。
详细规则:
- 如果发送方有数据需要发送且数据量超过 MSS, 或者发送窗口中没有未确认的数据包,那么立即发送该数据包
- 如果发送方有数据需要发送且发送窗口中有未确认的数据包,将新的数据包积累到发送缓冲区,直到收到接收方的数据包确认 Ack, 或者发送缓冲区的数据量达到 MSS,再发送数据包
下面是对应的伪代码:
if 有新数据要发送
if 数据量超过 MSS
立即发送
else
if 之前发出去的数据尚未确认
把新数据缓存起来,凑够 MSS 或等 Ack 到达再发送
else
立即发送
end if
end if
end if
Nagle 算法和延迟确认一样,并没有直接提高性能,只是减少了部分确认包,减轻了网络负担。
示例
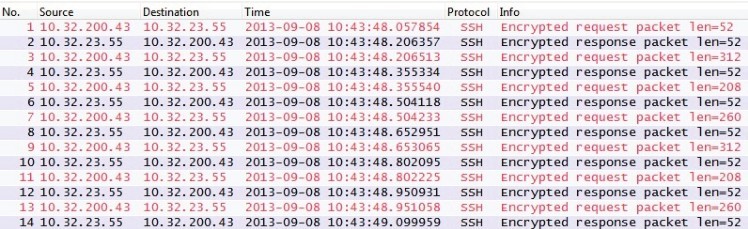
如图所示,第一个数据包把输入的第一个字符发出去了,在收到确认包之前的 150 毫秒里,又输入 6 个字符,这 6 个字符并没有被逐个发送,而是被累计缓存起来,等收到 2 号数据包 (Ack) 之后,和 3 号数据包一起发送,所以 3 号数据包的数据长度是 312 字节。
不足 (局限性)
Nagle 算法和延迟确认一样,不适合需要快速响应的小数据包通信场景,因为会导致发送延迟,影响性能与应用体验。
此外,Nagle 算法和延迟确认是冲突的,如果接收方启用了延迟确认,Nagle 算法可能导致发送方的数据包积压,从而增加通信延迟,这种情况下,Nagle 算法和延迟确认的结合可能会引起队列头部阻塞(head-of-line blocking), 增加网络延迟。
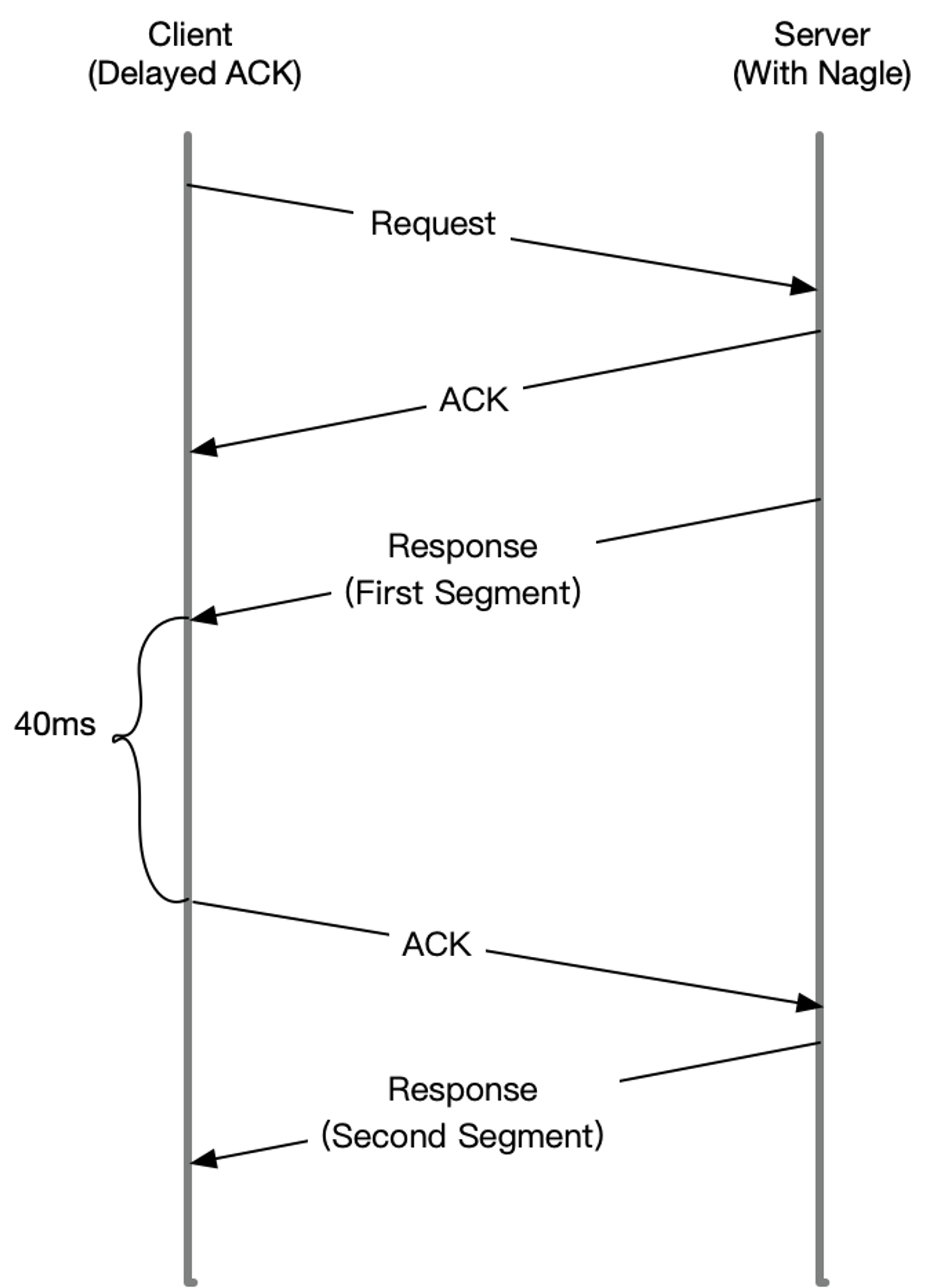
- 当 服务端 发送了第一个分组后,由于 客户端 开启了延迟确认,就需要等待 40ms 后才会回复 ACK
- 同时,由于 服务端 开启了 Nagle 算法,这时还没收到第一个分组的 ACK,服务端 也会在这里一直等着
- 直到 40ms 超时后,客户端 才会回复 ACK,然后 服务端 才会继续发送第二个分组
TCP_CORK
TCP_CORK 算法是比 Nagle 算法更加激进的优化方式,因为它完全禁止了小数据包的发送,直到数据积累到足够大 (能够填充一个完整的 TCP 段),或者被明确指示发送 (如关闭 TCP_CORK 选项)。
相对来说, Nagle 算法只是禁止了大量的小数据包的发送。
糊涂窗口综合症
糊涂窗口综合症 (Silly Window Syndrome) 是指在 TCP 网络通信中,发送方或接收方以 不合理的小块数据 进行通信,从而导致低效的数据传输和网络带宽浪费。
SWS 主要由以下两种情况引发:
- 发送方以小数据块发送数据 (当发送方生成数据的速度过慢或者每次生成的数据量过小时)
- 接收方以小数据块更新其接收窗口 (接收方缓冲区较小或者处理数据速度较慢时)
当接收方通知给发送方的接收窗口越来越小时 (例如只有几个字节),此时发送方再发送几个字节的数据,就完全没必要了,为什么呢?
因为传输层的 TCP 头部 + 网络层的 IP 头部,最少有 40 个字节,为了发送几个字节的数据包,而额外组装了 40 个字节的头部,这就本末倒置了。所以,糊涂窗口综合症 这个命名方式也挺合理的 :-)
举个例子,当有效负载只有 1 字节时,再加上 TCP 头部和 IP 头部各占用的 20 字节,整个网络包就是 41 字节,这样实际带宽的利用率只有 2.4%(1/41)。如果整个网络带宽都被这种小包占满,那整个网络的有效利用率就太低了。
解决方案
如果问题是由于发送方引起的,那么就会使用前文中提到 Nagle 算法 来 缓解。
如果问题是由于接收方引起的,那么就会使用 Clark’s 算法 来解决,该算法主要思路如下: 接收方在发送窗口更新时,只有当接收窗口的增加量达到一定的阈值(如 MSS 大小), 或者接收缓冲区空闲超过一半大小时,再发送窗口更新报文。这样就可以避免接收方频繁发送小窗口更新报文,确保发送方等到数据包较大时再发送。
附录
什么情况下会发送数据?
- 可以发送一个完整的 MSS 大小的数据段
- 连接空闲,并且可以清空发送缓冲区
- Nagle 算法被禁止,并且可以清空发送缓冲区
- 紧急数据
- 重传数据
- 确认 Ack
- 接收窗口更新
TCP Window Scale
Window Scale 的作用是向对方声明一个 Shift count,我们把它作为 2 的指数,再乘以 TCP 头中定义的接收窗口,就得到真正的 TCP 接收窗口了。
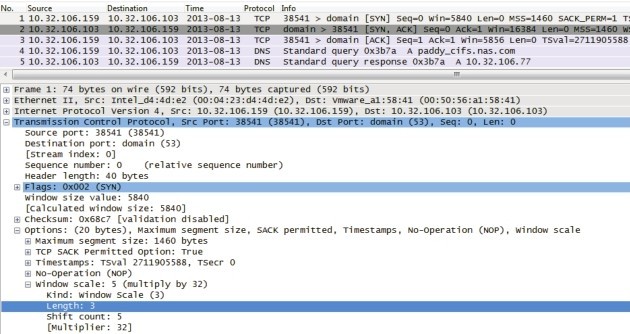
如图所示,从底部可以看到 10.32.106.159 告诉 10.32.106.103 说它的 Shift count 是 5, 2^5 等于 32,这就意味着后续通信中,10.32.106.159 声明的接收窗口大小,需要乘以 32 才是真正的接收窗口值。
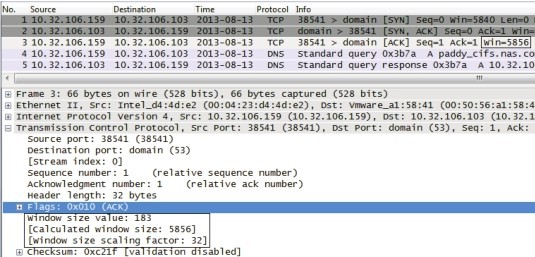
如图所示,10.32.106.159 声明它的接收窗口为 “Window size value: 183”,183 乘以 32 得到 5856,所以 Wireshark 就显示出“Win=5856”了。
需要注意的是, Wireshark 是根据 Shift count 计算出这个结果的,如果抓包时没有抓到三次握手,Wireshark 就不知道该如何计算,所以有时候会很莫名地看到一些极小的接收窗口值,还有的场景中,防火墙识别不了 Window Scale,因此对方无法获得 Shift count,最终导致严重的 TCP 性能问题。
为什么延迟过高会影响性能?
因为高延迟会造成长时间的空等待,发完一个窗口的数据后,发送方必须停下来等待接收方确认,延迟越高,发送方等待的时间越长。
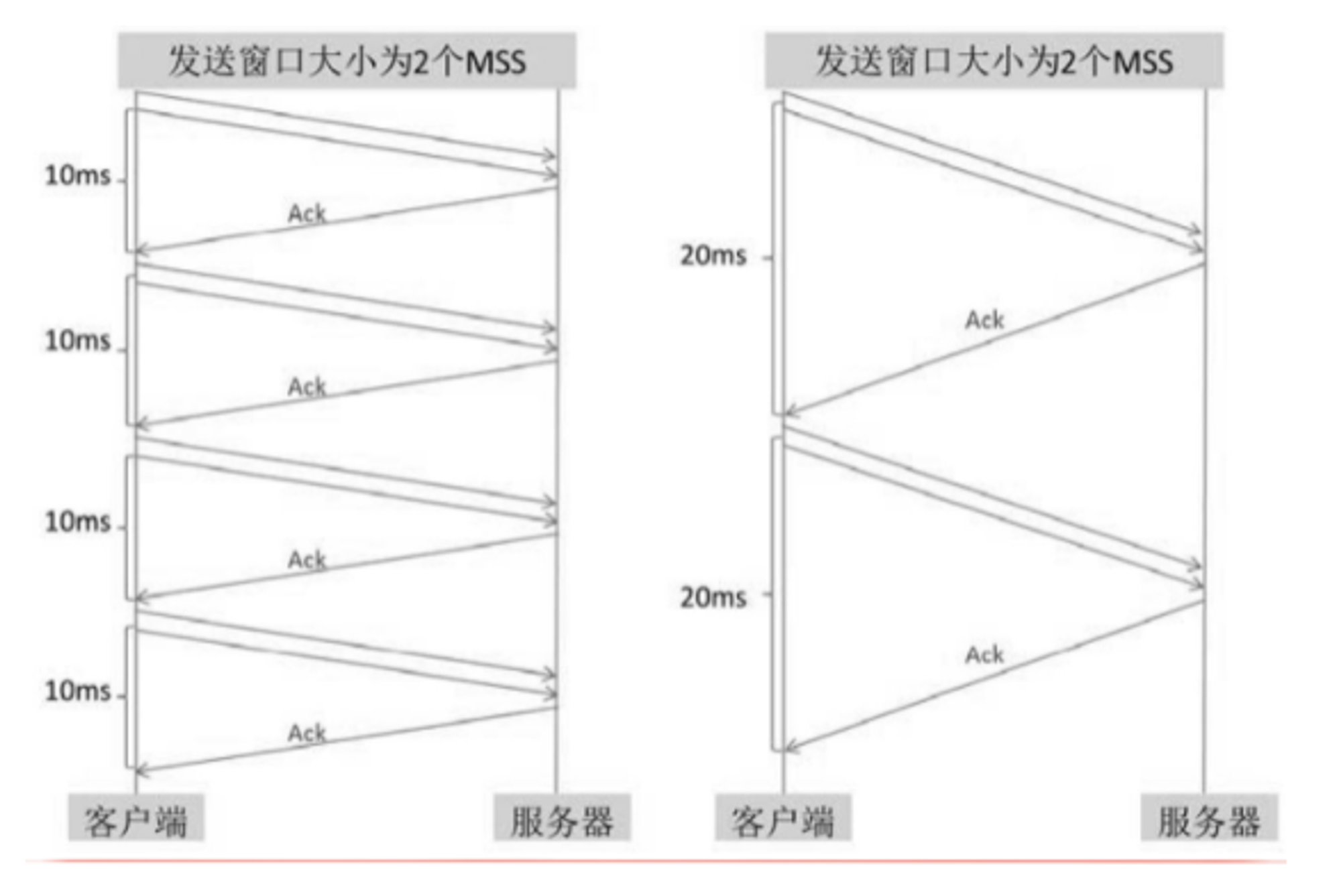
发送窗口相同的情况下,延迟越低,发送的数据量越多。
❓ 更多思考
每个 TCP 连接都是独立的,如果一个服务器中运行多个网络应用,而且每个应用不知道其他应用的存在,那么如何统筹规划对于网卡带宽的高效利用?
