TCP 到底有什么性能问题?
2022-10-10 计算机网络
概述
TCP 的性能问题本质是公平与效率的取舍问题。
TCP 实现可靠传输层的核心有三点:
- 确认与重传 (已经可以满足 “可靠性”,但是可能存在性能问题)
- 滑动窗口 (也就是流量控制,为了提高吞吐量,充分利用链路带宽,避免发送方发的太慢)
- 拥塞控制 (防止网络链路过载造成丢包,避免发送方发的太快)
滑动窗口主要关注发送方到接收方的流量控制
拥塞控制更多地关注整个网络 (链路) 层面的流量控制
滑动窗口和拥塞控制相互制约,使发送方可以从网络链路的全局角度来自动调整发送速率,从这个角度来看,TCP 对于整个网络的意义已经超过 “传输层”。
拥塞控制
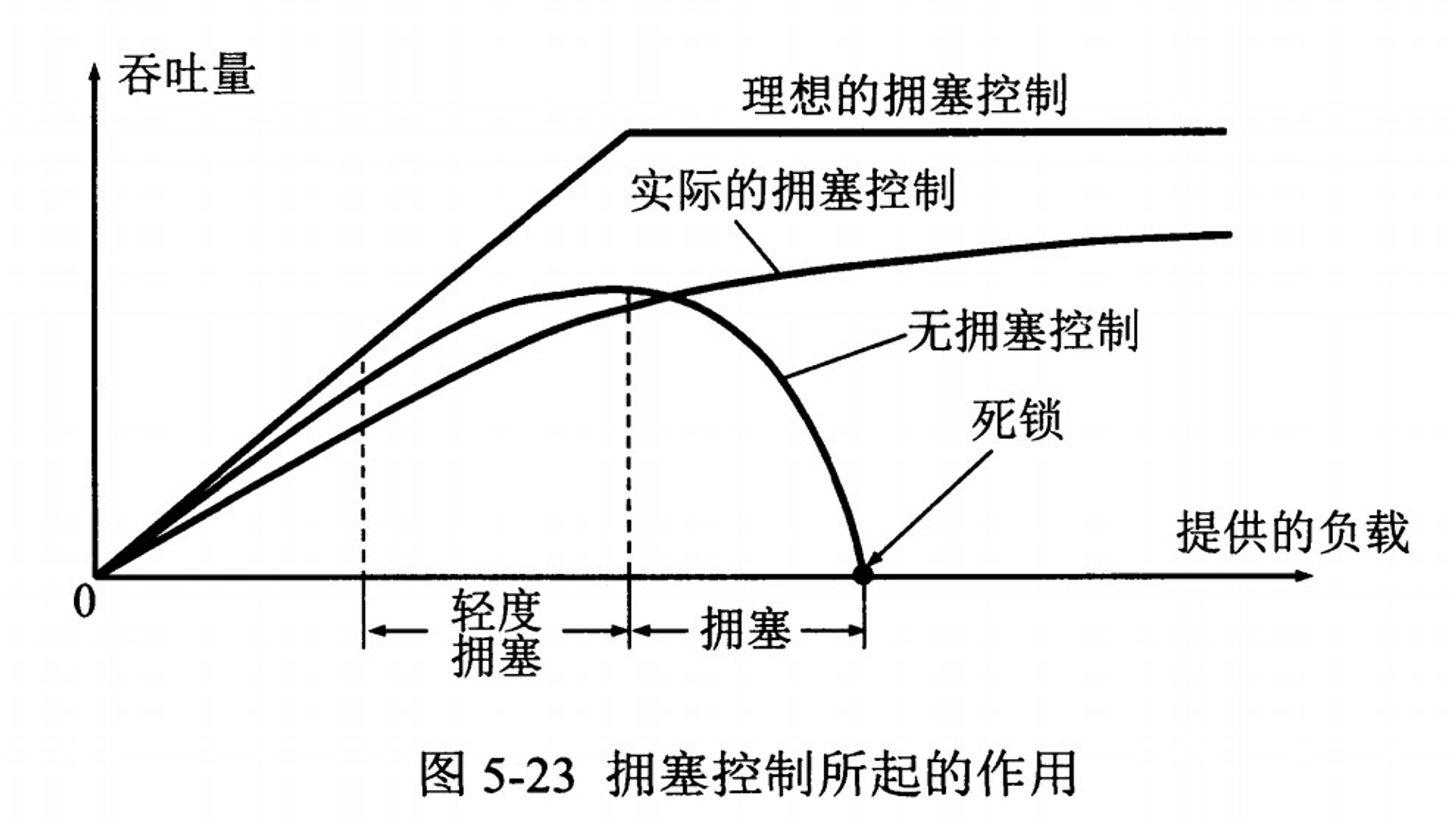
相比滑动窗口,拥塞控制的视角更为全面,会对整个网络链路中的所有主机、路由器,以及降低网络传输性能的有关因素进行综合考量。
既然拥塞控制要考虑这么多因素,那就不可避免地会在某些场景下存在所谓 “性能问题”,下面来具体分析下。
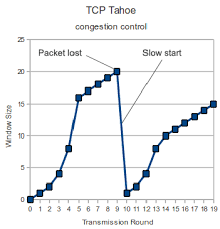
1. 慢启动
慢启动本身不会造成性能问题,因为慢启动时,cwnd (拥塞窗口大小值) 是指数级增长,所以 “慢启动” 其实并不慢,这一点我们在之前的 TCP 拥塞控制实现原理 文章中已经讲过了。
但是在特定场景下 (如 HTTP),慢启动会增加数据传输的 往返次数。
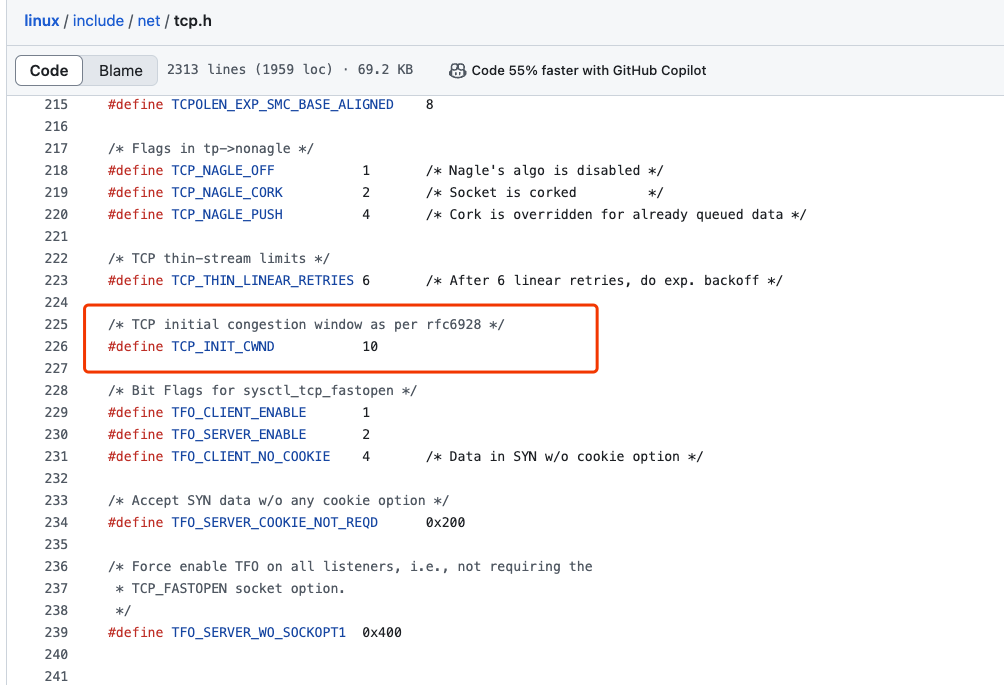
这里以 Linux 为例,内核在 3.0 之后,采用了 Google 的建议,将 cwnd 初始化为 10 个 MSS,默认的 MTU 为 1500, MSS 为 1460, 那么,第一次发送的 TCP 数据 (Segment) 总量为:
$$ 1460 * 10 = 14600 ≈ 14 KB $$
默认情况下,ssthresh 值为 65 KB,也就是从 慢启动阶段 进入到 拥塞避免阶段 的阈值。
我们随便访问一个网站的主页 (例如 stackoverflow.com), 这里就以其首页 html 文本数据大小 (68.8 KB) 为例,说明一下慢启动对于服务端发送响应数据,带来了哪些性能影响。
- 第 1 次发送的数据总量为:
14 KB - 经过 1 个 RTT,
cwnd翻倍 - 第 2 次发送的数据总量为:
28 KB - 经过 1 个 RTT,
cwnd再次翻倍 - 第 3 次发送的数据总量为:
56 KB
经过 3 次发送后,14 + 28 + 56 = 98 KB, 首页 html 文本数据传输完成,一共经历了 3 个往返次数。
当网页资源加载完成后,一般很少再去加载其他资源/数据,但是此时,cwnd 也才刚刚接近 ssthresh 阈值大小。
假设现在我们消除掉慢启动阶段,直接火力全开,第 1 次就发送数据总量: 65 KB, 那么就只需要经历 2 个往返次数,就可以完成数据传输。
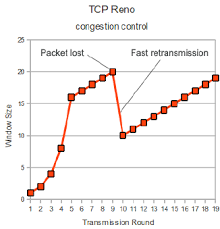
2. 拥塞发生 (丢包)
在基于丢包的拥塞控制算法中 (例如 Reno、Cubic、NewReno), 认为一旦发生丢包,就是网络链路发生了拥塞,所以发送方会急剧地减小发送窗口,甚至进入短暂的等待状态(超时重传)。
1% 的丢包率并不只是降低 1% 的传输性能,而是可能降低 50% 甚至更多 (取决于具体的 TCP 实现),此时就可能出现极端情况: 网络花在重传被丢掉的数据包的时间比发送新的数据包的时间还要多,所以这是造成 所谓 TCP 性能问题 的最大元凶。
丢包同时会加重网络链路拥塞,假设 1 个 TCP 数据段转发到第 N 个路由器,前 N-1 个路由器已经完成转发,但是第 N 个路由器转发时丢失了数据段,最终导致丢失的数据段浪费了前面所有路由器的带宽。
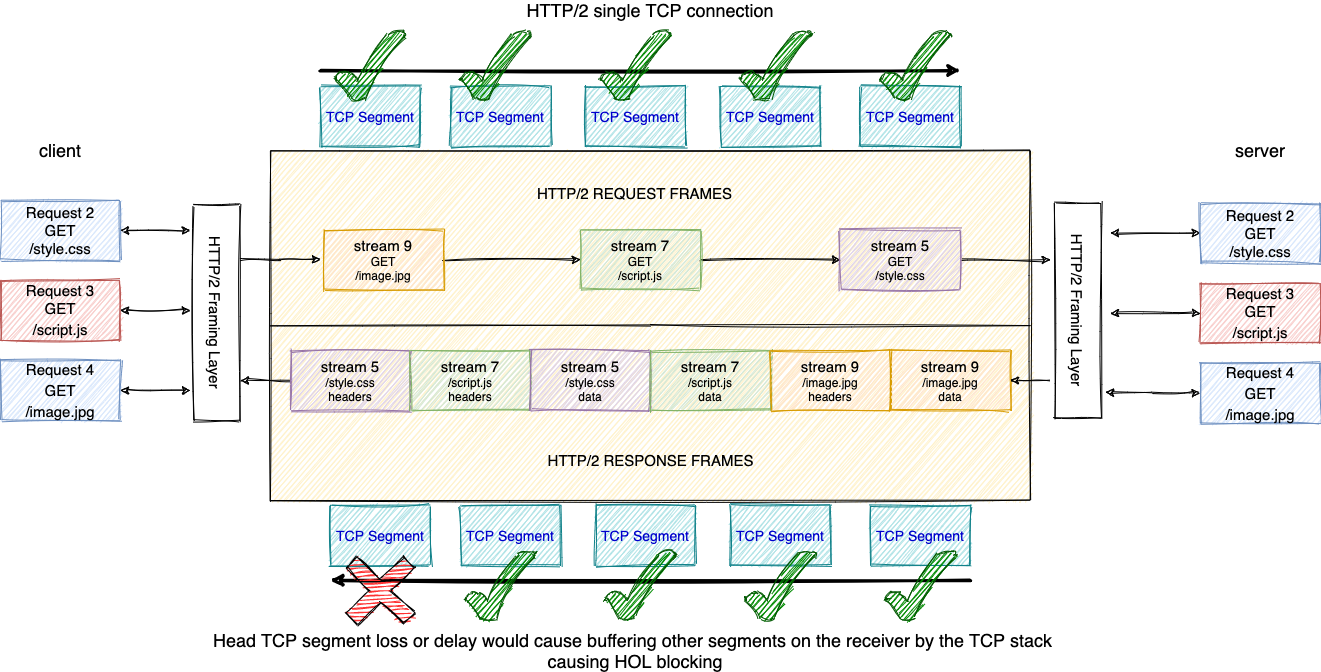
这里以 HTTP 场景为例,丢包带来的影响在 HTTP/2 中表现更为严重,因为 HTTP/2 只使用 1 个 TCP 连接进行传输。所以 1 次丢包会导致所有的资源下载速度变慢。而 HTTP/1.1 可能有多个独立的 TCP 连接,1 次丢包也只会影响其中 1 个 TCP 连接,所以这种场景下 HTTP/1.1 反而会获得更好的性能。
顺序可靠性保证
虽然 TCP 确保所有数据包有序到达,但是这个顺序语义保证可能会引发类似 HTTP 队列头部请求阻塞 (head of line blocking) 问题。
TCP 在传输时使用序列号 (Seq) 标识数据的顺序,一旦某个数据丢失,后续的数据需要保存在接收方的 TCP 缓冲区中,等待丢失的数据重传完成后,才能进行下一步处理 (传递到应用层)。
应用层无法得知 TCP 接收缓冲区的情况,所以必须等待序列 (Seq) 完整之后才可以获取应用数据。但是实际上,已经接收到的数据包中,很可能就有应用层可以直接处理的数据,所以,这也可以称之为 TCP 队列头部请求阻塞 (head of line blocking) 问题。
改进和优化
针对基于丢包的拥塞控制算法,最明显的改进就是使用更为合理的拥塞控制算法,例如可以更好地适应高带宽、高时延、且容忍一定丢包率的 BBR 算法。
如果保证 TCP 可以在
0 丢包的前提下传输数据,那么自然而然可以最大化利用带宽。
🤔: 思考: 如果高丢包的情况下,使用 UDP 会获得更好的性能吗?
三次握手
除了拥塞控制引起的 “性能问题” 外,TCP 建立连接时的三次握手机制,在某些场景下也会引起性能问题。
对于大多数 TCP 的使用场景 (长连接 + 频繁数据传输),三次握手几乎可以忽略不计。真正会造成性能影响的是 长时间 + 大量短连接 场景,针对这个问题, 可以考虑将短连接改造为长连接,或者使用 TFO 技术 来进行优化。
此外,还有 2 个会引发性能问题的场景是 HTTP 和网络切换。
HTTP
在 HTTP/1.1 版本中,访问不同的的资源时 (CSS, Javascript, images …) 会使用多个 TCP 连接会产生大量的延迟,如下图所示。
解决方案也很简单:直接升级使用 HTTP/2, 在整个通信过程中,只会有 1 个 TCP 连接。
除此之外,有的读者可能会想到 “弱网络” 这个使用场景 (例如人群密集的地铁车厢),但是,既然都是 “弱网络” 了,那么使用其他的传输协议也很难规避这个问题。
网络切换
TCP 连接迁移:受限于 TCP 四元组 的限制,如果源 IP 发生变化,则需要重新建立 TCP 连接,从而导致延迟暂停 (例如当前设备从 Wifi 切换到蜂窝网络)。
类似的场景,还有多个物理场所使用不同的出口公网 IP 地址,例如学校的图书馆和宿舍,公司的会议室和办公区,当使用者切换物理空间时,也会发送重新建立 TCP 连接。
当然,该问题同样可以通过使用 TFO 技术 来进行优化。
确认与重传
这块 (可能) 会引发 TCP 性能问题的原因,主要涉及到 3 点:
- TCP 超时重传带来的性能影响
- TCP 快速重传的局限性
- TCP 选择性重传解决了哪些问题
细节部分在 之前的文章中 已经详细讲过了,本文不再赘述。
小结
现代 TCP 在理想传输条件下,性能只受限于光速和接收方缓冲区 (内存) 大小,也就是硬件和物理。
硬件方面,有例如 TOE, NIC 的各种助攻和加速。
所以最终 TCP 在理想情况下的硬件性能受限于:
- 链路中最小的带宽
- 链路中最慢的硬件处理
- 链路中最小的接收缓冲区大小
三者结合起来,也就是通信过程中的所谓 “瓶颈链路”。
如果不存在硬件性能限制,也就是在足够的带宽、足够的内存、足够的处理速度的前提下,TCP 的性能理论上只受限于物理,也就是光速。
最后,再次搬上大佬语录:
网络编程中,开发者遇到的实际问题,大约有 90% 都和开发者对于 TCP/IP 的理解有关。不要对 TCP 和 UDP 的相对性能做任何先验假设,即使是很小的擦不参数改变,都可能对性能产生严重影响。
