降本增效之应用优化 (一) Redis
背景
笔者所在公司八月初拥抱了变化,作为 “幸存者”,自然需要接手一大波前人留下的项目,降本增效的大前提下,为了保住 “狗命”,需要尽可能去多做一些能直接产生价值和收益的工作,
(毕竟在 优化代码 和 “被优化” 之间只能选一项)。
最近两周集中优化了一批应用接口,期间被各种 “奇 (shi) 葩 (shan)” 代码刷新了认知,很难想象这是每天一起吃饭吹水的同事写出来的,果然:
无脑定需求 + 不断改需求 + 疯狂赶进度 + 开发人员长期被动当工具人 = ? ? ?

吐槽归吐槽,这些代码唯一的技术价值就是给优化工作让出了很大的空间,笔者在匆忙间给自己定下了九月份的 OKR: 接手的维护阶段的项目总体资源优化 30%。
概述
因为要优化的项目都属于 IO 密集型,所以主要的工作重心还是在存储、IO 的相关优化上面,本文主要讲解一下优化过程中和 Redis 相关的部分, 笔者将业务问题场景进行了问题分类和对应的优化方案,算是对这两周的工作进行一个简单的回顾。
原则
优化工作的本质是面向收益编程。
优化越靠近业务应用层,效果越明显,映射到现实中,同样如此,越靠近业务层,绩效越好。千万不要直接闷头开始优化,要知道大多数代码都没有优化的必要, 牢记 2/8 原则,主要针对 hot path 代码和和明显有性能问题的代码进行优化。
确定目标
可以根据监控系统的各项指标,来确定具体的优化接口和代码,笔者通常会查看 Redis Server 总体的监控和负载情况,然后再分析具体的性能瓶颈和原因, 这里贴几张常用的性能排查指标图。
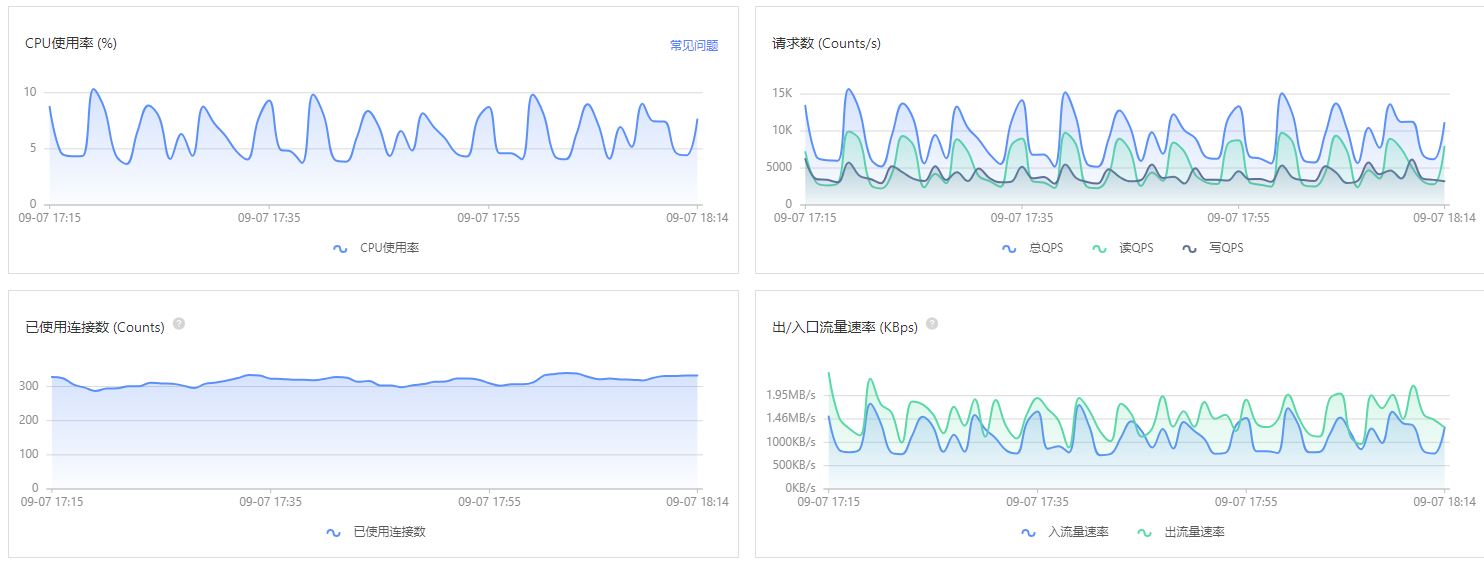
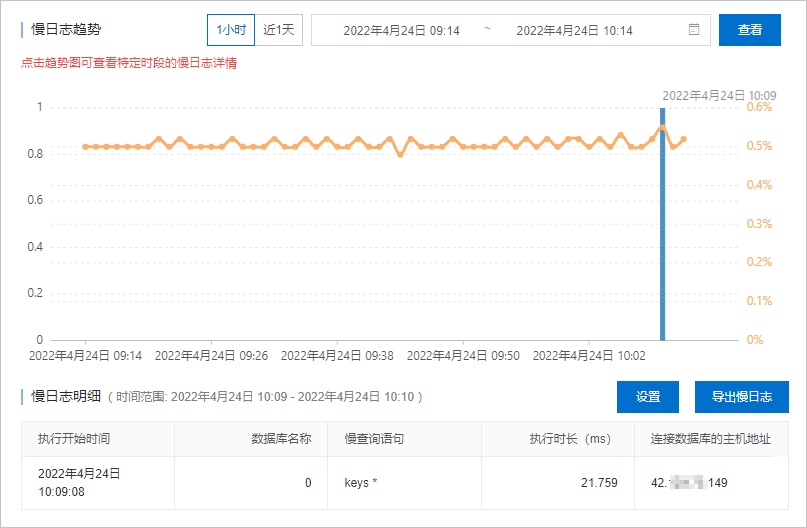
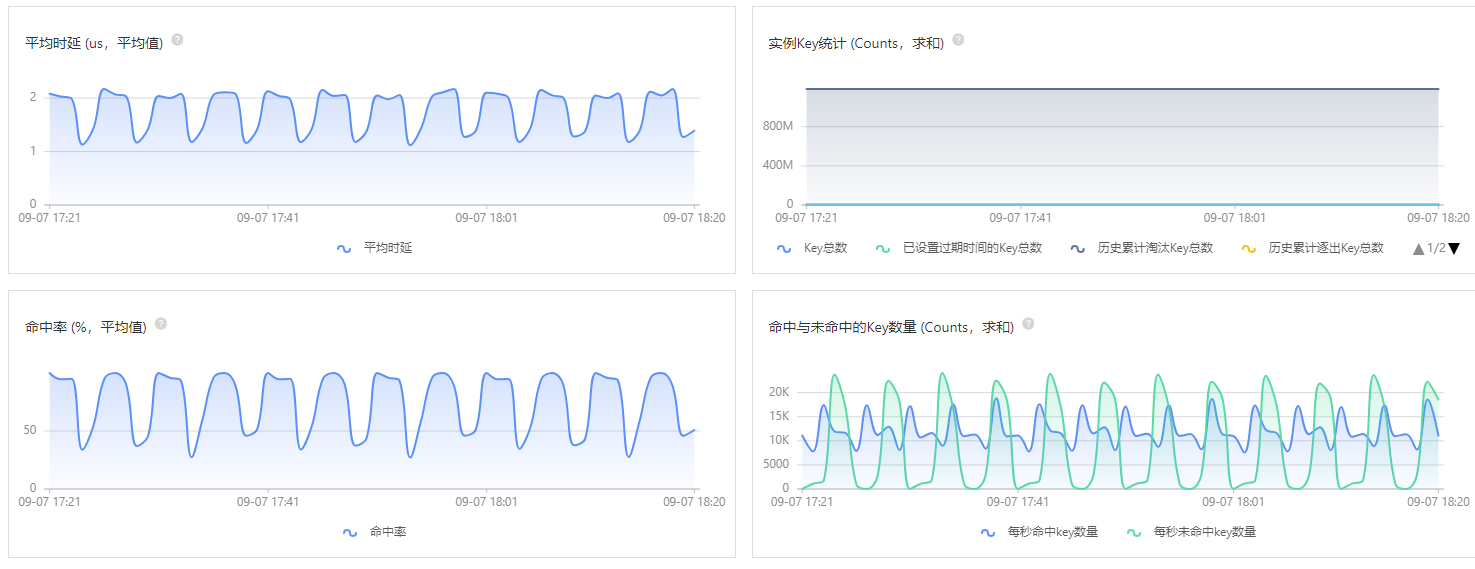
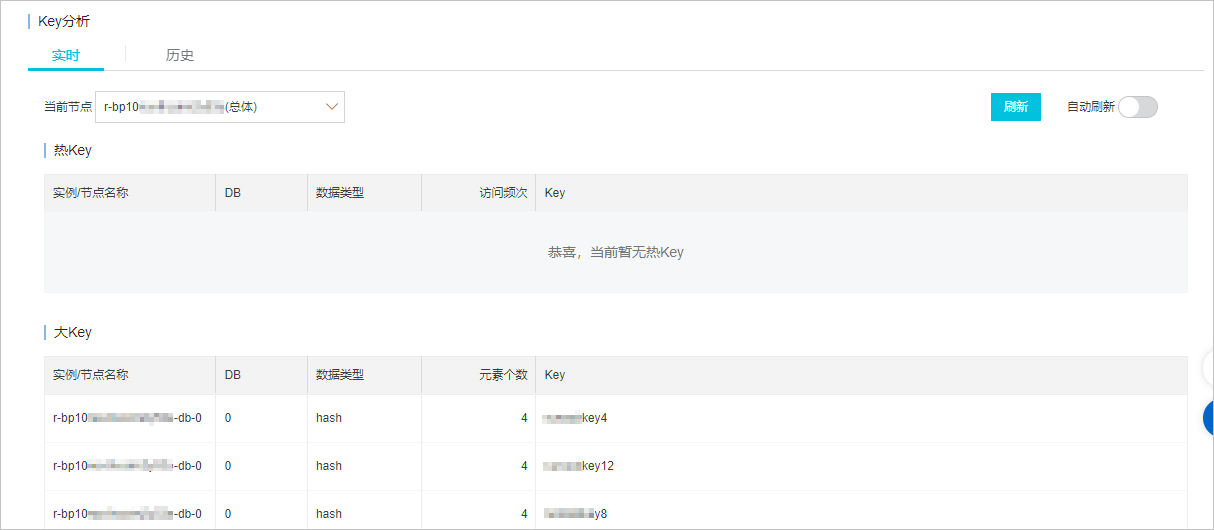
有了上述相关指标数据,我们可以根据 ROI 原则来计算接口的 “优化收益比”,确定要优化的具体接口,然后进行任务拆分、优先级排序、日程确定, 最后通过在线项目管理工具同步到产品和业务方。
为了简洁和统一,下文中提到到 客户端 包括 APP 客户端和 Web 前端。
零请求
优化的最高级形式就是客户端在本地进行数据处理,不发出任何请求到服务端,这种业务场景下,服务端的资源消耗为 0, 所以能在客户端处理的数据,就不要请求到服务端, 下面是笔者总结的四种可以直接在客户端处理的数据场景。
本地缓存
客户端直接将实时性要求不高的数据缓存到本地,用户查看时直接取出数据渲染,同时异步去接口加载。
数据聚合和排序
- 如果对已有的数据按照不同条件排序时,接口数据量不会发生变化,直接在本地排序即可
- 同理,对于聚合类数据操作,只要数量不会发生变化,也可以直接在本地进行
数据搜索和过滤
接口数据量较少的情况下,可以一次性全部返回所有数据,然后直接在客户端本地进行数据搜索和过滤功能,而不是通过请求 + 参数的方式让服务端处理。
数据格式化
- 后台配置的字典数据一次性全部返回,客户端可以根据具体的 key 进行区分,然后填充选项卡、下拉列表等 UI 视图
- 日期数据直接返回到客户端,由客户端做具体格式化处理,服务端返回携带时区的标准数据即可,例如
2022-03-29T16:05:14.000
单个状态值
这类应用场景的典型特征是每个用户只需要一个 bit 的标识位,也就是典型的 bitmap 类问题,解决方案也很简单,使用 Redis 内置的 bitmaps 数据结构即可。
注意: Redis 中的 bitmaps 最大支持数值为 2^32, 这里假设以用户 ID 作为标识字段,如果用户 ID 大于这个 2^32, 就无法存储了,如何解决这个问题呢?
只需要稍微变通一下,使用 ID / (2 ^ 32) 的值作为 bucket 桶编号, 然后拼接具体的业务 key 就可以了,最后使用 BITCOUNT 命令就可以查询统计结果了。
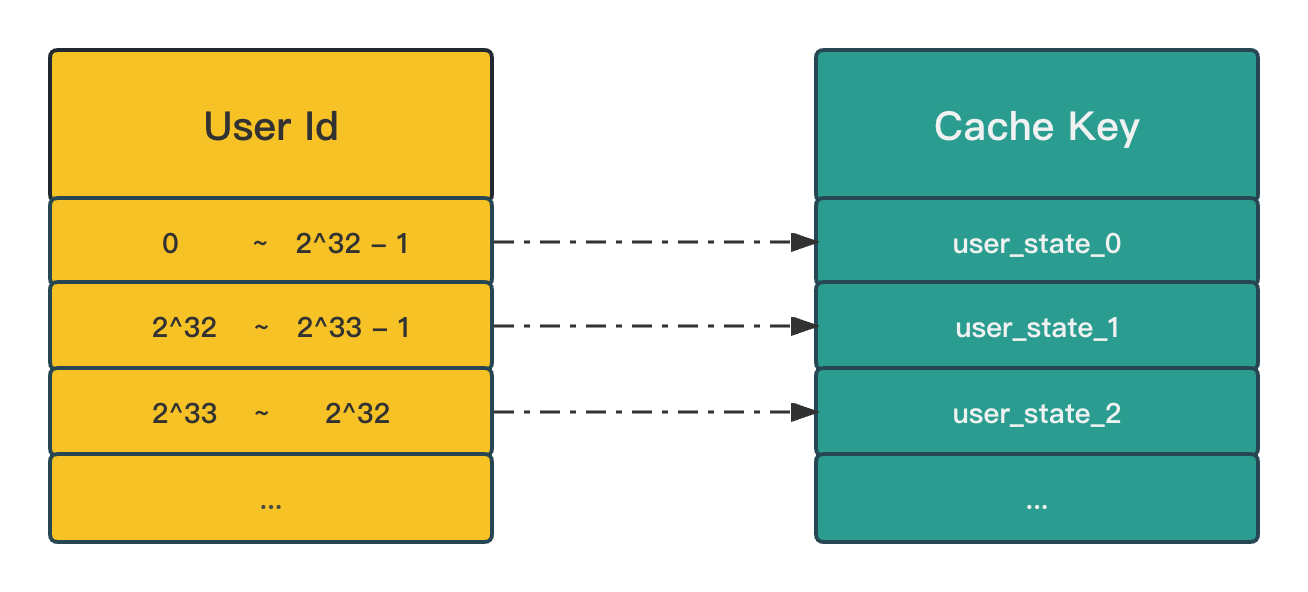
笔者主要优化了以下几个简单的场景:
- 用户是否点赞过、收藏过、分享过某个视频/文章
- 每日签到
- 青少年每日防沉迷提醒
唯一计数器
HyperLogLog 实现的唯一计数器可以大大降低内存使用量,如图所示为记录唯一访客 IP 时,各种数据结构所需的内存量。

数据组合
这类应用场景的典型特征是单个接口内部需要跨多个服务进行调用,最后组装数据统一返回,笔者的优化方法为:
- 按照业务最小维度缓存单条数据,Redis 缓存一份,对于热点数据,本地 (容器) 也缓存一份
- 查询时分别从本地查询单条缓存数据,从 Redis 批量查询数据 (使用 pipeline)
- 根据目标结果集和缓存数据集进行差异比较,计算出未命中的数据
- 从存储 (一般指数据库) 查询未命中的数据,并且回填到缓存中
笔者主要优化了个性化推荐信息流场景:
- 根据当前用户信息从推荐服务获取到具体的内容 ID 列表(内容可能是视频/文章等)
- 根据内容 ID 列表依次从缓存和存储中获取各项业务数据
- 最后将数据组装后返回到接口
编码/解码
如果缓存数据是字符串类型,将数据存储到 Redis 之前,需要进行编码操作,常规的做法是编码为 JSON 字符串,这样从 Redis 读取到缓存的字符串数据后, 如果数据不需要被读取并且不需要被修改,那么就可以直接将数据输出接口,这样可以节省 2 次 CPU 开销:
- 将缓存的字符串数据解码为具体对象
- 将具体对象再编码为字符串后输出接口
缓存 key 的命名
在保证辨识度的前提下,key 的长度越短越好,不仅可以节省存储,还可以提升查询速度。
作为用户资料数据的缓存 key,user_123456_profile 明显由于 user_profile_123456,因为前者的辨识度更高,查询速度更快,
在这个基础上可以对 key 的长度再次优化,例如优化为 u_123456_prof。
时间区间
这类应用场景的典型特征是不同时间段内的数据组合优化,项目中类似场景之前的做法是使用筛选条件中的 (开始时间 + 结束时间 + 业务 key) 进行拼接作为缓存数据 key, 稍微思考后会发现这其中有很大的潜在问题: 不同的两个日期组合结果集合是一个庞大的数字,除了重复数据导致的巨量内存浪费外,还会造成很大的安全隐患。
下面举个浪费内存的例子,不同用户查询的时间区间是重叠的:
- 用户A 2023-01-01 ~ 2023-01-10
- 用户B 2023-01-02 ~ 2023-01-05
- 用户C 2023-01-05 ~ 2023-01-08
通过示例可以看到,虽然有三个用户在查询,但是用户 B 和 用户 C 查询的数据都在 用户 A 的结果集内,也就造成了数据重估存储,白白浪费了内存。
笔者的优化方案为:
- 根据更小的粒度来缓存 (项目中以天为单位),这样单个业务场景一年最多 365 个 key
- 控制时间范围的上限,不能超过 31 天
- 根据请求参数批量从 Redis 读取缓存数据
- 将读取到的缓存数据组装完成后输出接口
注意: 如果项目的数据量很大,就需要调整时间粒度,并且进行数据异步批处理优化,但是整体的思路是不变的。
读写分离
这类应用场景的典型特征是只有一端固定的数据生产者,例如:
- 运营角色在管理后台完成整个 CMS 网站的内容
- 定时任务从第三方同步数据,完成后展示给所有用户
这种场景最容易优化,启动一个后台线程,定时刷新数据到缓存即可,这里不再赘述了 。
小结
本文提到的大多数问题都是因为缺乏对 Redis 的全面了解,直接把 Redis 当成 MemCache 类型的纯 K-V 来应用,也许是因为大家都在忙着背八股?
写在最后
希望大家都能有班上,有钱赚。
