为什么 Redis 6.0 引入多线程模型?
2023-05-03 Redis
Redis 为什么这么快?
如果你曾经看过/背过一些后端面试八股文,那么这个高频题你一定非常眼熟:
Redis 为什么快?
下面是一个经典的八股文式回答:
- C 语言实现
- 纯内存 I/O
- I/O 多路复用
- 单线程模型
我们来分析下上面的答案是否正确:
Redis 内置的数据结构以及相关操作都是纯内存操作,所以即使不是 C 语言实现的 (比如由其他静态语言实现),其性能也不会太差,此外,Redis 基于 IO 多路复用技术 (例如 Linux 上的 epoll) 来实现网络 IO 的海量吞吐,最后,Redis 的核心模型 (计算+网络) 位于单个线程内,虽然这导致 Redis 无法利用多核来提升性能,但是却正好避免了多线程情况下带来的上下文切换、同步机制、锁开销等性能影响。
所以整体来分析的话,上面的八股文答案大致是正确的,表面上看起来,只需要将八股文答案背下来,我们就可以快速掌握 Redis 高性能原理,这正是八股文的魅力所在 (简单暴力且有效)。
为什么选择单线程?
如果此时面试官追问到: “既然单线程无法利用多核优势,Redis 为什么选择单线程呢?” 这时就可以直接使用官方的回答来升华一下:
性能考量
对于 Redis 来说,CPU 通常不会成为性能瓶颈,因为大多数操作都是内存或者 IO 密集型的,而不是 CPU 密集型。 举例来说,即使在一台普通的服务器上面,Redis 使用管道操作的情况下,最高 QPS 可以达到 100 万, 所以如果应用程序主要使用复杂度 O(N) 或 O(log(N)) 的 Redis 命令操作,其实不会有太多的 CPU 消耗。
综上所述,Redis 本质上还是网络服务器,其核心瓶颈在于 IO 操作上面,也就是客户端和服务器端之间网络传输延迟, 所以 Redis (6.0 以下版本) 使用了单线程的 IO 多路复用机制来实现其网络模型。
代码实现考量
除了性能方面的考量之外,当然还有工程代码实现方面的考量,具体来说:
1. 避免复杂的线程模型
多线程并发调度中会引起 CPU 上下文切换,而上下文的切换又涉及到程序计数器、堆栈指针和程序状态字等一系列的寄存器置换、程序堆栈重置甚至是 CPU 高速缓存、TLB 快表的失效和淘汰。
多线程还涉及到底层数据的同步问题,这就必然需要引入同步原语机制,例如互斥锁、读写锁等,数据读写时获取锁和释放锁操作就会带来额外的性能开销,如锁竞争、,例如 Redis 内置的 List 数据类型,可以想象给一个长度较大的 List Key 热点数据读写操作时加锁时带来的性能影响。
使用单线程就可以避免多线程的复杂性带来的这些问题。
2. CPU 和内存利用率
Redis 作为基于内存的 K-V 型数据库,采用单线程可以更好地利用 CPU 缓存,提升内存的读写效率。在单个 CPU 性能较高时,单线程模型可以充分利用 100% CPU (极限压榨) 发挥最大性能。
3. 简化开发和维护工作
单线程模型简化了 Redis 的开发和维护工作,降低了多线程编程中开发和调试的复杂性,在单线程模型中,所有操作的原子性更容易实现。

如何部署多 CPU 服务器
对于多个 CPU 的服务器,如何部署 Redis 达到最大资源利用率呢?常见的部署方案是多实例部署。
通过在同一台服务器上启动多个 Redis 实例,每个实例绑定一个 CPU 核心,到达充分利用多核 CPU 的计算能力。
不同的 Redis 实例可以存储不同的数据 (例如根据业务划分),或者存储相同的数据用于主从复制、读写分离等 (理论可行,但是实际中不会这么做)。
虽然多实例部署提升了资源利用率,但同时也带来了实例管理复杂性,例如服务器资源和实例的关联管理,单个服务器上面每个实例的内存限制管理等。所以实际中更常用的方案是通过 Redis Cluster 在多个实例之间自动分片数据来实现负载均衡和读写性能提升。
小结
综上所述,虽然单线程模型在某些场景下限制了 Redis 的并发性能,但是基于 Redis 的事件驱动模型设计以及大部分使用场景属于读多写少, 所以单线程模型下的 Redis 依然拥有非常出色的表现。
Redis 6.0 引入多线程
既然 Redis 在单线程模型下的性能已经足够,那么为什么 6.0 版本之后又引入了多线程呢?原因可以总结为两个方面。
提升网络 IO 性能 (核心原因)
Redis 单线程模型中会消耗过多的 CPU 在网络 IO 处理上面,而且这个问题在单线程模型中几乎没有很好的方法解决,所以 Redis 的性能如果想进一步提升,只能从两个方面着手:
- 优化网络 IO 处理
- 提高内存读写效率
第二点受限于硬件的发展,这需要时间且无法预知,所以 客观条件下短期内的唯一方向就是优化网络 IO 处理,网络的 IO 有可以分为两个方向:
- 零拷贝或 DPDK
- 多核 CPU
Redis 使用零拷贝有一定的局限性,无法完全匹配 Redis 的网络 IO 场景,只能在部分场景下提升性能:
- 文件读写: 在进行持久化操作时(例如 AOF 日志和 RDB 快照),可以利用零拷贝来避免数据在内核态和用户态之间的复制
- 数据复制:在主从复制或集群数据迁移时,可以利用零拷贝来避免数据在内核态和用户态之间的复制
- 客户端回复:将操作结果返回到客户端时,可以利用零拷贝将数据直接从内核缓冲区拷贝到网卡,完全消除用户态和内核态之间拷贝数据开销
DPDK 技术实现过于复杂,需要通过旁路网卡 I/O 绕过内核协议栈,还需要内核甚至是硬件的支持。
各种性能优化方案和约束条件排除之后,直接利用多核 CPU 硬件优化,引入多线程模型优化网络 IO 成为简单可行的首选方案。
社区生态的需求
Redis 相关生态圈都已经开始大规模改造和使用多线程模型的 Redis, 例如主流的的云服务器厂商都有提供多线程模型的 Redis 商业版本,社区开发者对于 Redis 在性能和并发支持方面有更高的期望,如果 Redis 升级到多线程模型,就可以充分利用现代硬件性能提高并行处理能力,可以在保持 Redis 已有优势的同时增加其在现代多核 CPU 硬件上的性能潜力,为 Redis 适应未来持续发展做好准备。
所谓 “多线程”
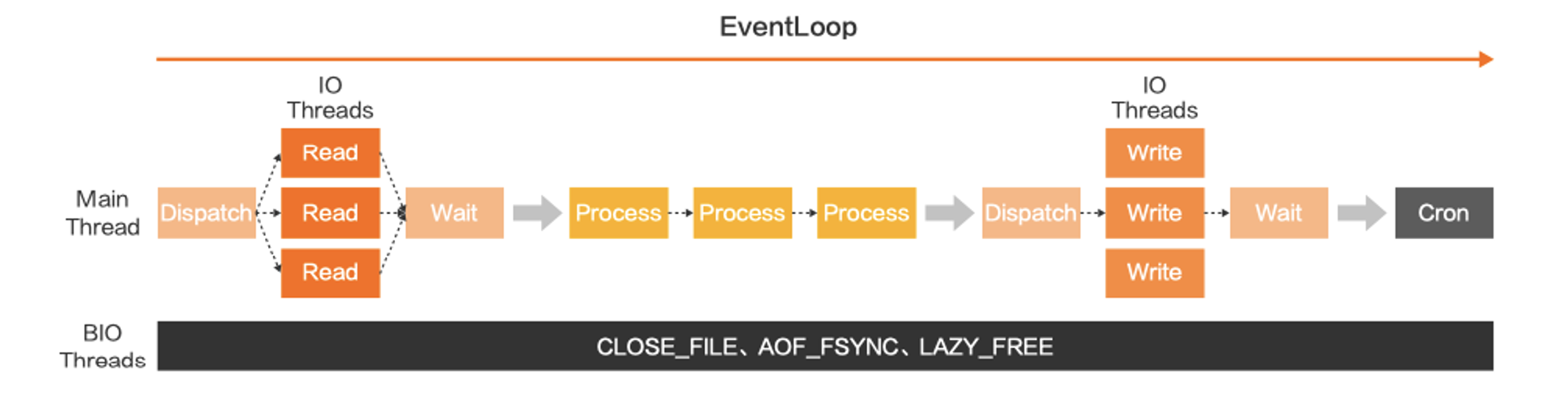
Redis 6.0 虽然引入多线程模型,但是客户端的所有命令执行还是在核心线程 (主线程) 中执行,I/O 线程仅仅是读取和解析客户端命令,这样就可以利用多核 CPU 的硬件优势来提高网络吞吐量。
引入多线程模型除了提升网络吞吐量之外,还带来了以下好处:
- 避免阻塞主线程:通过使网络 I/O 操作分配给 IO 处理线程,可以防止耗时的 I/O 操作阻塞主线程,主线程专注于执行客户端命令计算和连接分配即可
- 提升 CPU 和内存利用率:主线程工作过程中,IO 线程也可以执行客户端命令解析、响应客户端数据操作,整体提升 CPU 和内存的利用率
当然最重要的是,将数据计算操作控制在主线程内,可以保证数据的读写依然保持原子性,性能提升的同时还完全兼容了 Redis 的已有内部数据结构,实现了工程上面的可控制和可实现。
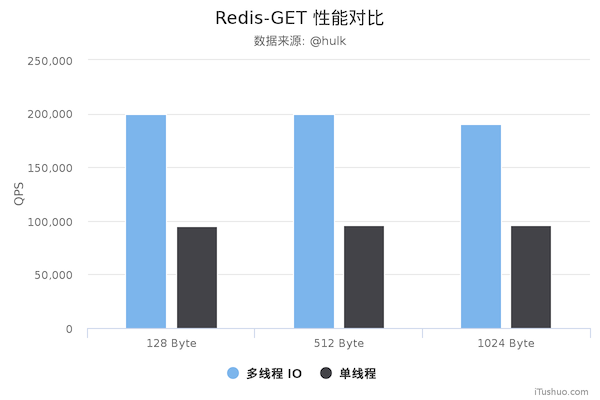
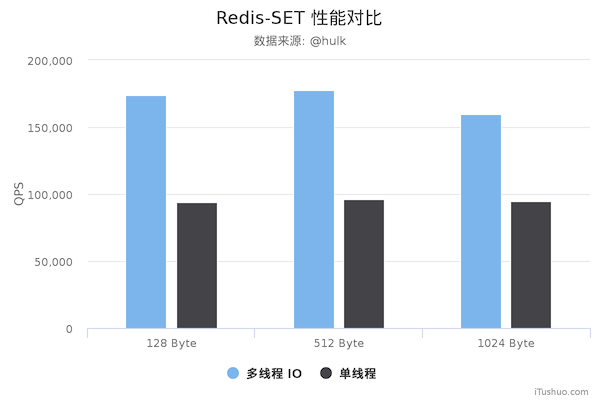
性能提升空间
由于计算线程依然只有一个 (主线程),对于简单的命令例如 GET key, SET key 整体上性能确实提高了,但是如果命令本身比较复杂,主线程还是会阻塞等待。其次,将读取客户端命令和响应客户端数据分配到 IO 线程时,主线程也处于阻塞等待状态,无法提供服务。所以总体来看,Redis 6.0 的多线程版本虽然迈出了一大步,但是性能方面依然有很大的优化和提升空间。
使用方式
如果需要在 Redis 中启用多线程 I/O,可以更改 redis.conf 配置文件或使用命令行设置选项:
# 修改 redis.conf 配置文件, 变更需要启动的线程数量
io-threads 4
io-threads-do-reads yes
# 或者在 Redis 服务启动时通过参数设定需要启动的线程数量
redis-server --io-threads 4
阿里云 Redis 多线程商业版
笔者所在公司并没有自主搭建 Redis 高可用服务,而是直接购买了阿里云的 Redis 集群服务,这里正好也顺带说一下阿里云团队对于 Redis 的多线程模型改造,从中学习汲取工程思路和经验。
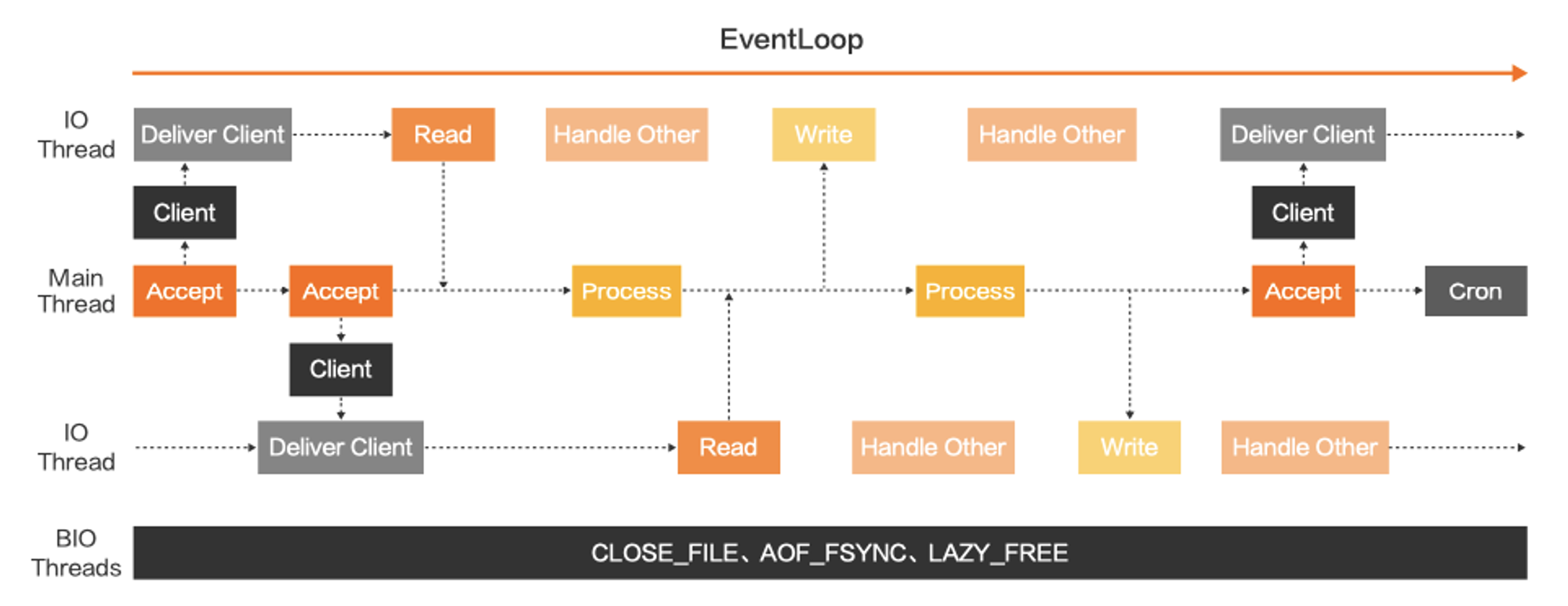
阿里云 Redis 企业版 (Tair) 的线程模型模型更进一步,把整个事件处理流程拆分地更加细化,主线程只负责命令处理 (计算),所有的客户端连接管理、读写处理全部由 IO 线程完成,也就是在 Redis 6.0 的基础上将主线程的工作进一步降低,客户端连接到达之后,直接交给 IO 线程处理,主线程不再关心这些操作。
当客户端命令到达之后,IO 线程会将命令解析之后交给主线程处理,主线程处理完成之后通过通知将处理结果给到 IO 线程,剩下的工作由 IO 线程完成,最大程度降低主线程的等待时间,将性能再提升一步。
小结
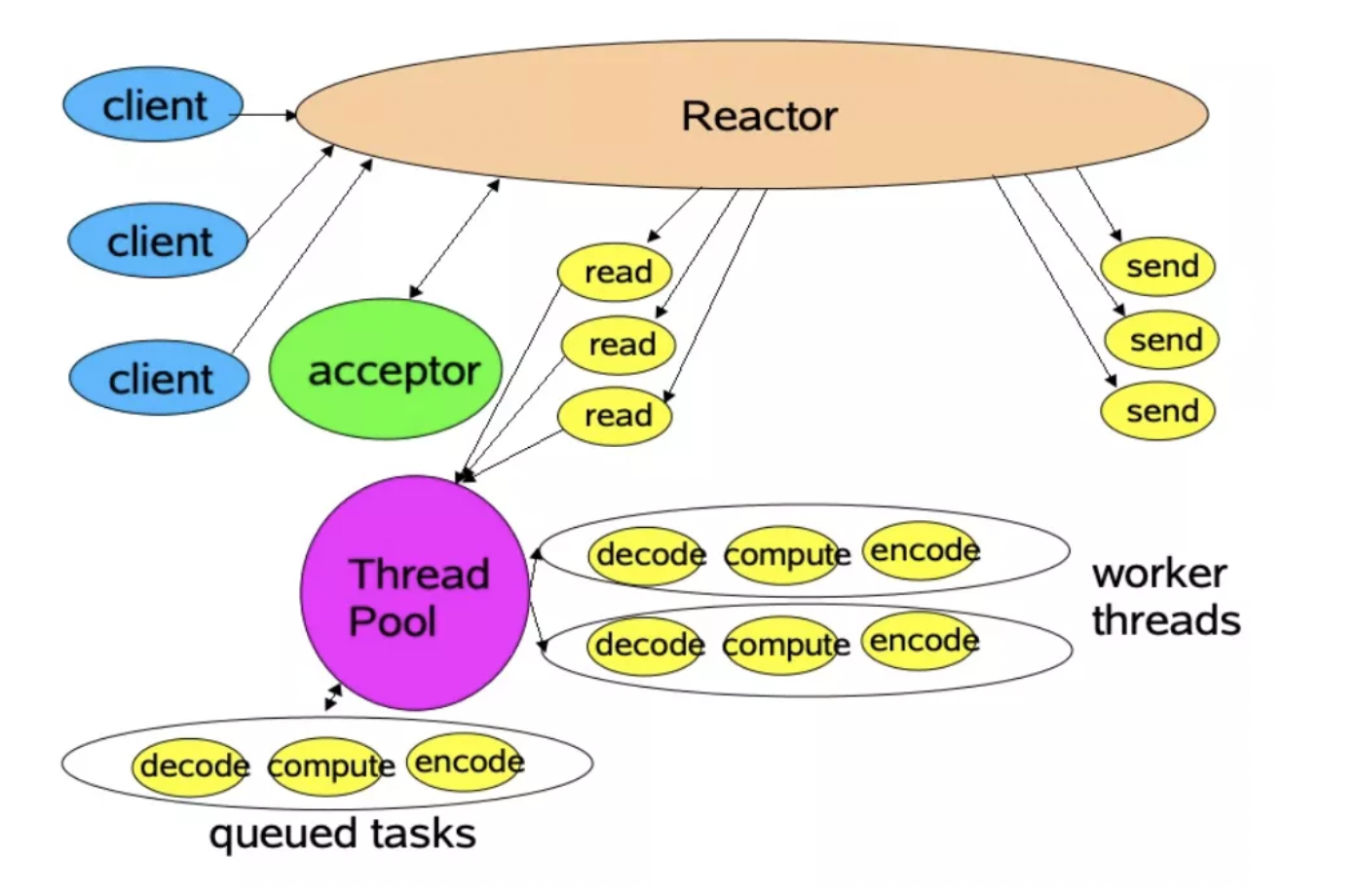
网络上很多文章称 Redis 6.0 引入的多线程模型为 “缺陷版本”,根本出发点在于: 认为 Redis 6.0 未实现标准完整的 Multi-Reactors-Pattern/Master-Workers 线程模型,在该模型中,主线程只负责分发任务,而在 Redis 的多线程模型中,主线程除了分发任务之外,还要执行客户端的命令请求,并且每次分配完任务之后都要阻塞等待 IO 线程接收完成,因此对于多核 CPU 的整体利用率并不充分。
这么明显的问题 Redis 作者和社区难道看不出来吗?答案当然是否定,我们可以看到:不管是开原版的 Redis 6.0, 还是阿里云的 Redis 企业版 (Tair), 最终的版本中,Redis 负责数据处理的线程依然只有一个主线程,之所以没有跨过 “多线程并行计算” 这一步,本质原因还是 Redis 已有的内部数据结构并非是 “Thread Safe” (线程安全) 的,作为一个 K-V 型数据库,数据结构是其生命基石,如果要将数据结构全部改为 “Thread Safe” 版本,那么这其中的工作量无疑是非常巨大的。
所以通过多方的升级改造方案来看,都是采取 “Trade Off” 迭代式更新,既保持了内部核心代码 (数据结构) 的兼容性,又能利用多核 CPU 提升 IO 性能。相信在不久的将来,以 Redis 的市场占有率、社区成熟度外加 antirez 的影响力,真正完全意义上的 Redis 多线程模型会全面实现,保持期待!
