CDN 原理
2023-02-28 计算机网络
概述
CDN 的全称是 Content Delivery Network,即内容分发网络,基本思路是: 尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节, 使内容传输得更快更稳定。
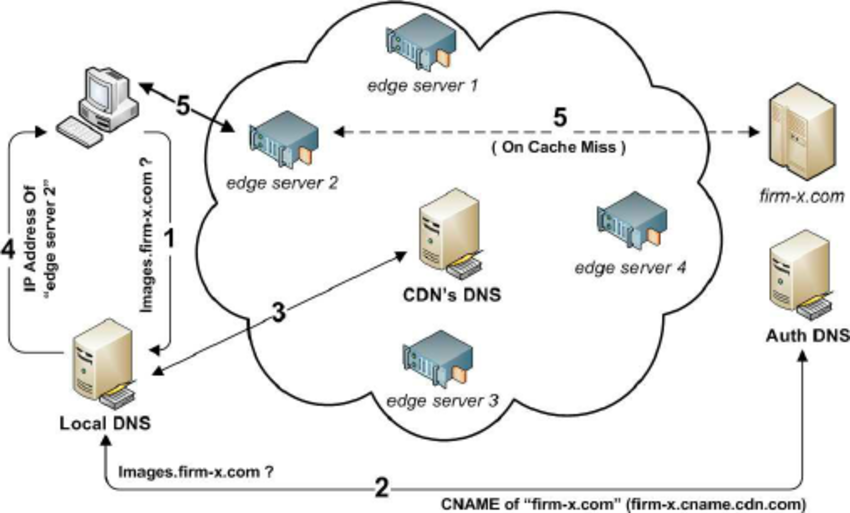
CDN 技术原理
CDN 的 基本原理为反向代理,反向代理(Reverse Proxy)方式是指以代理服务器来接受 Internet 上的连接请求,然后将请求转发给内部网络上的服务器,
并将从服务器上得到的结果返回给 Internet 上请求连接的客户端,此时代理服务器对外就表现为一个节点服务器。通过部署更多的反向代理服务器,来实现 多节点 CDN 架构。
CDN 主要使用了 负载均衡、动态路由 和 内容压缩 来提高其性能和可靠性:
- 分布式存储: 采用可扩展的系统架构,利用多节点、多位置、多种方式存储数据
- 负载均衡: 可以将流量均匀地分配到多个节点服务器上,从而避免某些服务器过度负载而导致响应时间延迟
- 动态路由: 可以根据网络流量和服务器负载情况来选择最优的路径和服务器来响应用户请求
- 内容压缩: 可以将内容文件压缩到更小的体积,以减少网络传输的时间和成本
简单地理解,CDN 就是客户端和真实服务器之间的一层高效的缓存。
传统网站访问过程
在说明 CDN 的技术优势之前,我们先来看看传统网站的 HTTP 请求 访问过程。大部分开发者应该都熟悉 HTTP 协议基础流程,下面以请求一个图片文件来举例说明。
- 客户端浏览器输入网址,如
https://www.example.com/logo.png - 浏览器请求
DNS服务器,查询https://www.example.com/logo.png对应的源服务器IP地址 - DNS 服务器返回对应的
IP地址 - 浏览器向服务器发起
TCP连接 - 浏览器通过建立的
TCP连接发送HTTP请求图片文件 - 服务器向浏览器发送图片文件
- 浏览器将接收到的图片文件渲染,完成本次请求
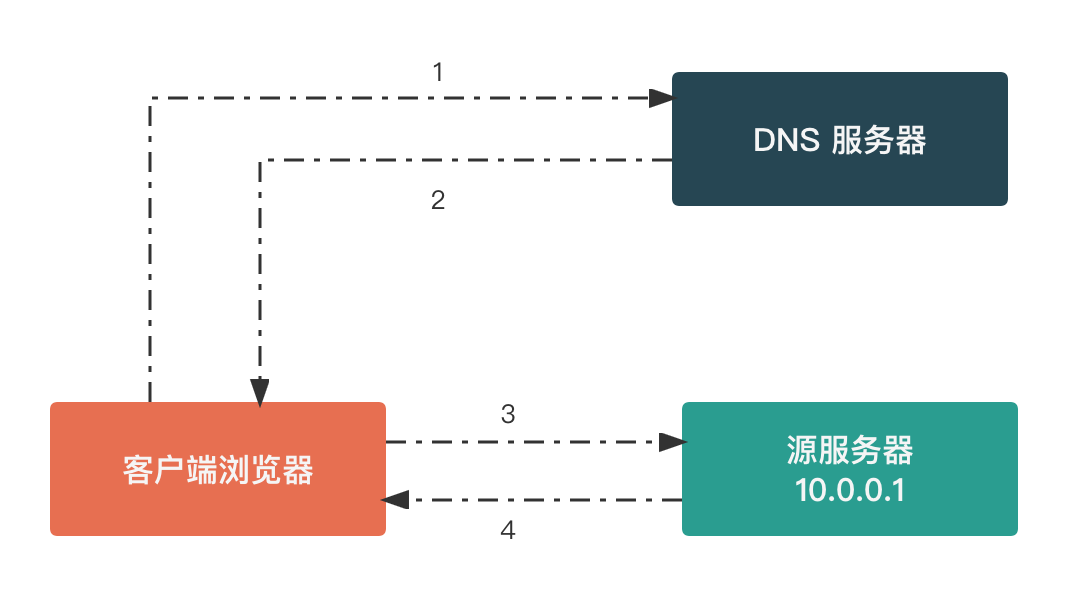
如果我们要加入 CDN 的话,是加到哪个步骤呢?
根据上面描述的步骤不难发现,从第 3 步开始,客户端浏览器就和真实的服务器开始建立连接了,连接建立完成后,客户端浏览器就直接从服务器获取数据, 这显然不是我们需要的,因为这样所有的客户端都会直接连接服务器,会严重增加服务器的负载。
我们再来看第 2 步,浏览器在访问真实的服务器之前,会先通过 DNS 查询域名对应源服务器的 IP 地址,如果 DNS 返回的是 CDN 服务器的 IP 地址,
那么后面的流程就会变为: 客户端浏览器就直接从 CDN 服务器获取数据,接下来的工作就会全部转交给 CDN 了,如何完成这项工作呢?
将域名
www.example.com的 CNAME 记录解析到 CDN 服务商即可,CDN 服务商的 DNS 服务器也称为权威服务器 (细节请看上篇文章: DNS 原理)。
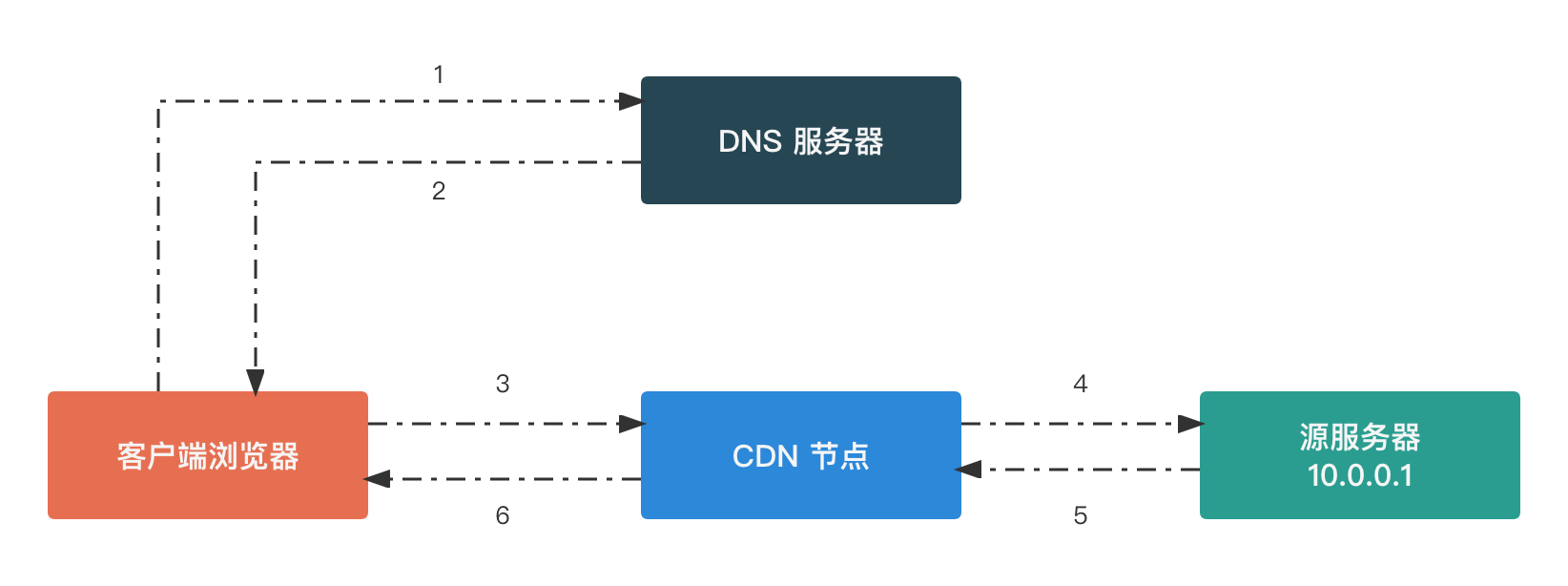
接入 CDN 网站访问过程
- 客户端浏览器输入网址,如
https://www.example.com/logo.png - 浏览器请求
DNS服务器,查询https://www.example.com/logo.png对应的服务器IP地址 - 由于域名的
CNAME记录解析到了CDN服务商,所以这里DNS服务器会返回CDN服务商提供的CDN节点服务器的地址 - 浏览器向
CDN节点服务器发起TCP连接 - 浏览器通过建立的
TCP连接发送HTTP请求图片文件 CDN节点服务器使用内部专用DNS解析出域名对应的源服务器IP地址CDN节点服务器向源服务器发起TCP连接CDN节点服务器通过建立的TCP连接发送HTTP请求图片文件CDN服节点务器接收到图片文件后,在本地保存一份,作为缓存使用,减少源服务器的回源流量CDN节点服务器向浏览器发送图片文件- 浏览器将接收到的图片文件渲染,完成本次请求
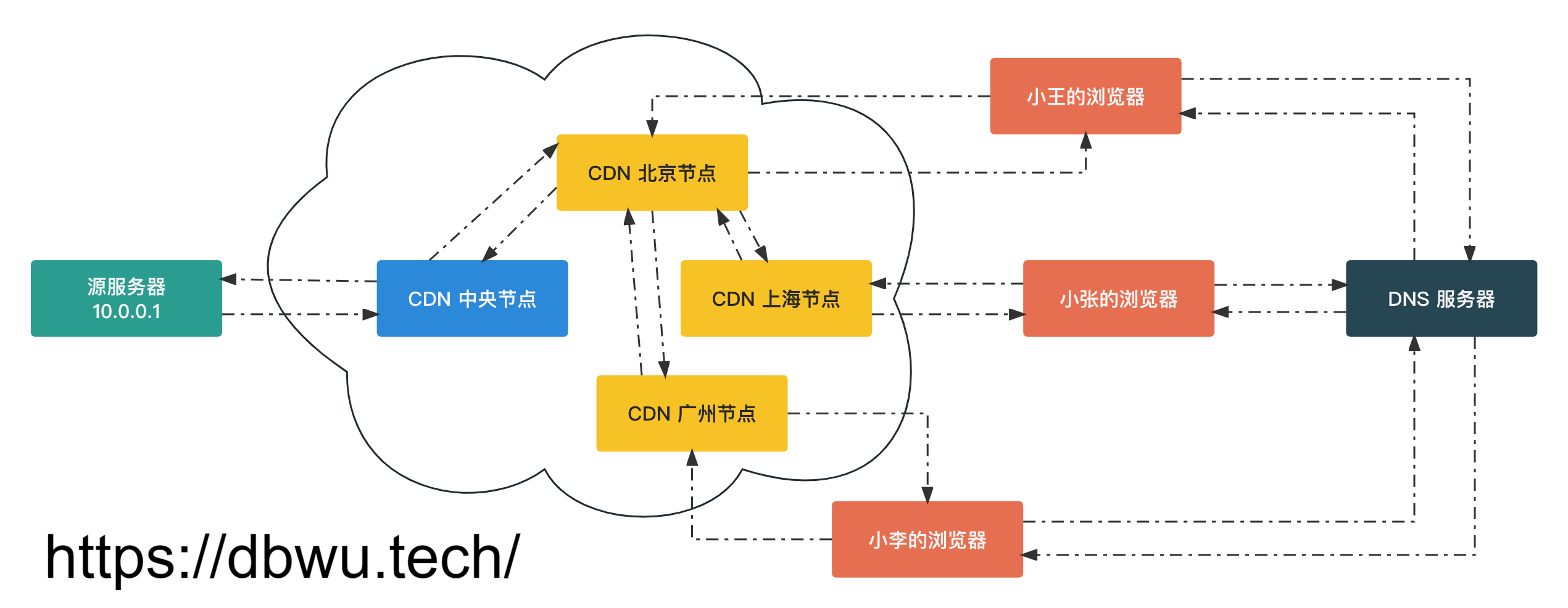
中央节点如何选择提供服务的 CDN 节点
一般会综合考虑以下几个方面:
- 网络成本
- 流量分布
- 源站负载
- 地理位置
这里以 地理位置 举例说明:
- 用户访问
CDN服务商的权威DNS服务器 DNS服务器获取用户的IP地址- 根据用户
IP地址查询用户所在地 - 返回离用户最近的
CDN节点的IP地址,比如用户离北京近,就返回北京的CDN节点的IP地址
如何提高 CDN 缓存命中率
- 在流量高峰来临前,将热门资源提前预热到
CDN节点 - 合理配置文件缓存过期时间,如将静态文件缓存过期时间设置为 1 个月甚至更久
- 消除 URL 中文件名称后面的参数,如
https://www.example.com/logo.png和https://www.example.com/logo.png?version=123应该被视作同一个文件处理 - 超大文件设置分片回源策略,如
视频文件,APP 安装包等
不适合使用 CDN 的场景
- 请求客户端和服务器物理距离很近,比如同机房、同机架的内网服务
- 用户分布在同一地理区域,如同城服务、本地门户网站
- 动态文件或接口,比如更新很频繁的文件,使用
CDN反而会增加响应耗时
数据如何回源
还是以刚才的 https://www.example.com/logo.png 为例,CDN 节点服务器会先把这张图片缓存起来,下次有相同的请求到达时,直接返回缓存的图片,从而减少回源流量。
这里提到的 缓存 是一个很复杂的功能,下面是阿里的 HTTP 缓存服务器,名字叫 Swift。
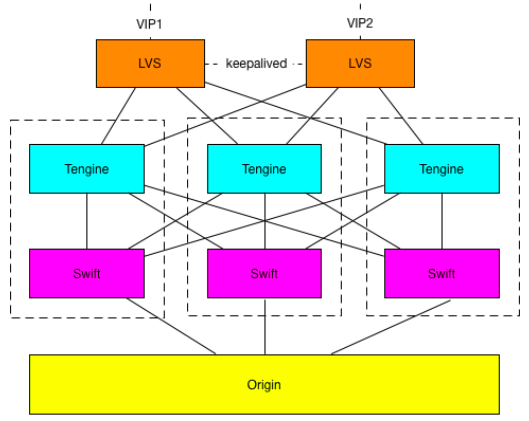
图中是一个 CDN 节点,用户的请求从 LVS(LVS是一个四层的负载均衡组件)的入口来,先由 LVS 做一次 4 层的负载均衡,
然后转到一台 Tengine(阿里在 Nginx 的基础上开发的服务器)上,Tengine 做一致性哈希,选择一台 Swift 服务器去做缓存数据回源。
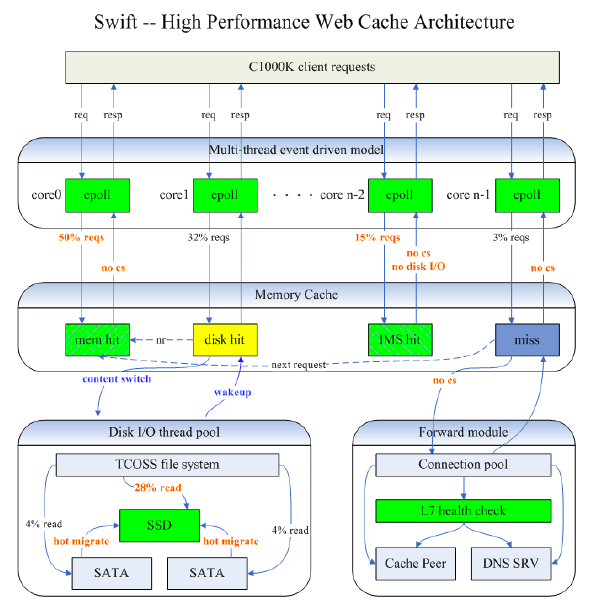
首先可以看到,Swift 是一个多线程的程序,每个线程启动一个 epoll 来充分发挥多核的处理能力,并且尽量减少线程间的上下文切换,一个请求尽量在一个线程处理。
除此之外,还能看到 内存缓存,SSD 缓存,SATA 缓存。Swift 有热点淘汰和提升机制,将热文件放在内存里,次热文件放在 SSD 上,最后才是 SATA 盘。
叔度 (阿里 CDN 负责人) 指出,Tengine 和 Swift 是通过 Spdy 协议 来通信的,从而优化HTTP的效率。
和 OSS (Object Storage Service) 的差别
- OSS 的核心是存储以及计算能力,而 CDN 的核心是分发
- OSS 用来存放静态资源,比如 image、js 文件等资源,CDN 用来将 OSS 里面的文件进行分发 (回源操作)
- OSS 里面的文件会缓存到 CDN 的节点上,但 CDN 本身不会给用户提供直接操作存储的入口 (单纯用来请求)
更新方式
Push
当资源内容发生变化时,直接推送给 CDN 并重写 URL 地址以指向新资源的 CDN 地址,资源只有在更新或新增时才推送,流量最小化,但储存最大化。
Pull
当资源首次被访问或资源内容过期时,CDN 服务器从源服务器上拉取资源 (回源操作),这会增加响应时间,但是可以最小化 CDN 的 的存储。 为了避免峰值流量遇到 CDN 资源缓存失效的极端场景,CDN 服务器都会提供资源缓存过期时间,并在过期之前主动去源服务器拉取资源, 当然这会带来一些额外的流量 (毕竟大多数静态资源生成之后基本不会变化),但是可以极大提升用户体验,所以高流量的应用服务通常会对热点资源同时采用 Push + Pull 两种更新方式。
小结
CDN的原理是: 基于分布式架构,通过将源服务器上的内容分发到多个节点服务器上,使用户能够从最近的服务器中获取所需内容。 这些节点服务器被称为 边缘服务器,它们通常位于不同的地理位置,并通过高速互联网连接互相交换数据。 用户通过接入离他们最近的 边缘服务器 来获取所需的内容,从而降低了响应时间和延迟,提高了网站的访问速度。
