Go channel 的 15 条规则和底层实现
2023-06-08 Golang 并发编程 Go 源码分析 读代码
概述
下面表格中的内容是 Go 语言中 channel 数据类型的使用规则,相信读者已经可以熟练掌握,本文主要分析 channel 的内部实现中的数据结构和算法,所以相关的基础概念会直接跳过,
希望读者阅读完本文后,可以深入理解表格中的各类规则,从应用层代码到底层实现,能够知其然并知其所以然。
操作规则
| 操作 | nil | 已关闭 channel | 未关闭有缓冲区的 channel | 未关闭无缓冲区的 channel |
|---|---|---|---|---|
| 关闭 | panic | panic | 成功关闭,然后可以读取缓冲区的值,读取完之后,继续读取到的是 channel 类型的默认值 | 成功关闭,之后读取到的是 channel 类型的默认值 |
| 接收 | 阻塞 | 不阻塞,读取到的是 channel 类型的默认值 | 不阻塞,正常读取值 | 阻塞 |
| 发送 | 阻塞 | panic | 不阻塞,正常写入值 | 阻塞 |
编译规则
| 操作 | 类型 | 结果 |
|---|---|---|
| 接收 | 只写 channel | 编译错误 |
| 发送 | 只读 channel | 编译错误 |
| 关闭 | 只读 channel | 编译错误 |
channel 的内部实现文件路径为 $GOROOT/src/runtime/chan.go,笔者的 Go 版本为 go1.19 linux/amd64。
几个常量
const (
// 内存对齐的最大值,这个等于 64 位 CPU 下的 cacheline 的大小
maxAlign = 8
// 计算 unsafe.Sizeof(hchan{}) 最接近的 8 的倍数
hchanSize = unsafe.Sizeof(hchan{}) + uintptr(-int(unsafe.Sizeof(hchan{}))&(maxAlign-1))
// 是否开启 debug 模式
debugChan = false
)
hchan 对象
hchan 对象表示运行时的 channel。
对于无缓冲 channel 来说,发送队列和接收队列至少有一个为空,一个无缓冲 channel 和一个阻塞在该 channel 上面的 goroutine,使用 select 语句发送和接收。
对于有缓冲 channel 来说,qcount > 0 意味着接收队列为空,qcount < dataqsiz 意味着发送队列为空。
type hchan struct {
qcount uint // channel 元素数量
dataqsiz uint // channel 缓冲区环形队列长度
buf unsafe.Pointer // 指向缓冲区的底层数组 (针对有缓冲的 channel)
elemsize uint16 // channel 元素大小
closed uint32 // 是否关闭
elemtype *_type // channel 元素类型
sendx uint // 当前已发送元素在队列中的索引
recvx uint // 当前已接收元素在队列中的索引
recvq waitq // 接收 goroutine 队列 (数据结构是链表)
sendq waitq // 发送 goroutine 队列 (数据结构是链表)
// lock 保护结构体中的所有字段,以及 sudogs 对象中被当前 channel 阻塞的几个字段
// 不要在持有锁时修改另一个 goroutine 的状态(特别是没有进入 ready 状态的 goroutine)
// 因为这会导致栈收缩而发生死锁
lock mutex
}
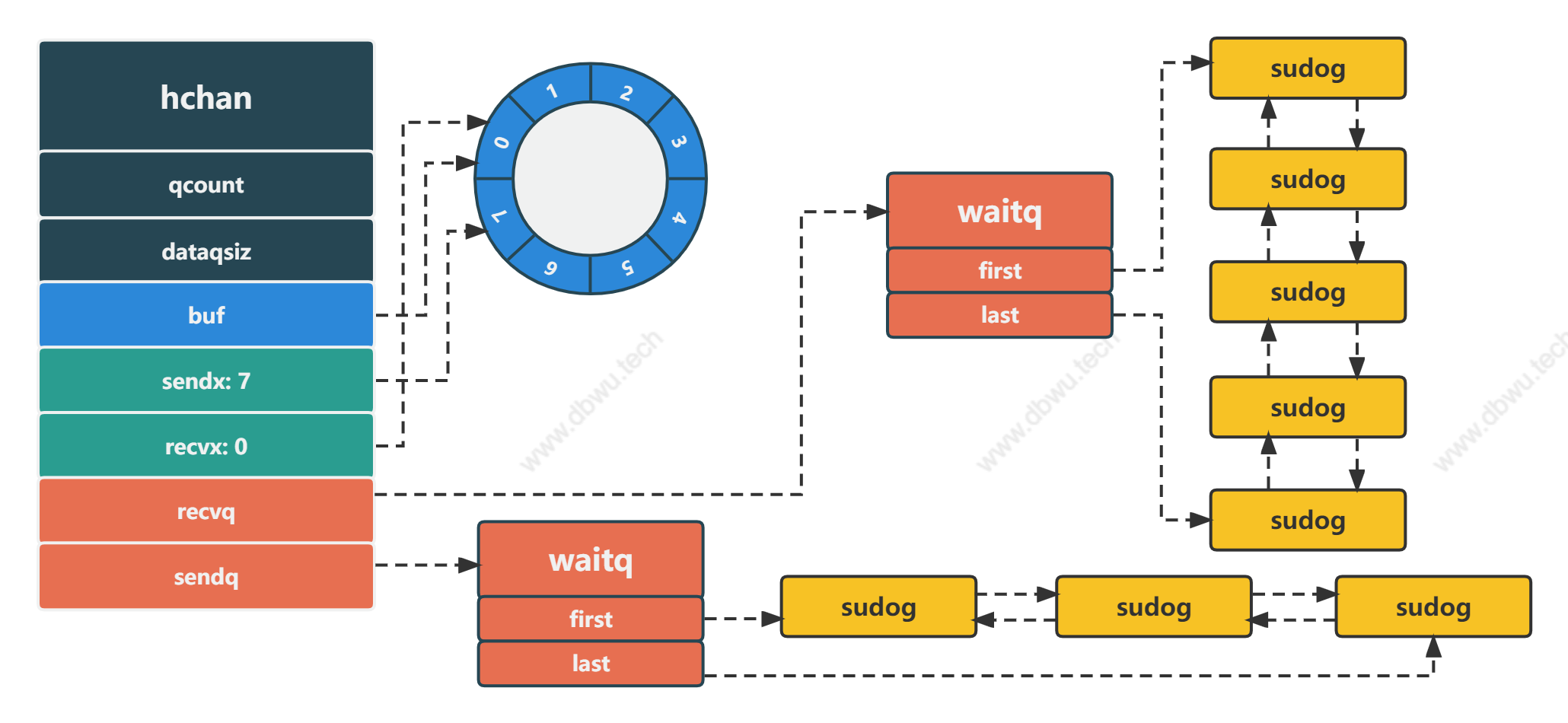
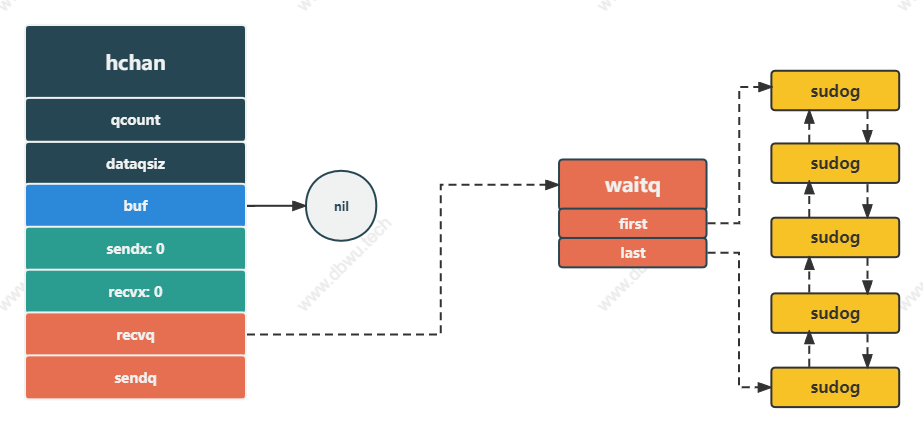
上面的图片展示了一个典型的 channel 数据结构图,其中各元素表示为:
- 缓冲区环形队列长度为 8, 也就是最多可以存放 8 个数据
- 发送索引指向 7,接收索引指向 0,说明当前缓存队列已满,无法再放入数据了,此时新的发送/接收
goroutine会进入发送/接收队列 - 发送队列中有 3 个
goroutine等待发送 - 接收队列中有 5 个
goroutine等待接收
waitq 对象
waitq 对象表示因为 channel 缓冲区空间不足而陷入等待的 goroutine 发送/接收队列, 数据结构是双向链表,其中头节点和尾节点都是 sudog 对象,
sudog 对象的字段和具体作用在之前的 GMP 调度器 - 数据结构 一文中已经讲过,这里不再赘述。
type waitq struct {
first *sudog
last *sudog
}
读者可以停下来思考一个问题: 同一个 goroutine 有可能同时出现在发送队列和接收队列吗?为什么?
创建 channel
编译器会将应用层代码中的 make(chan type, N) 语句转换为 makechan 函数调用。
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 由编译器检查保证元素大小不能大于等于 64K
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
// 检测 hchan 结构体大小是否是 maxAlign 的整数倍
// 并且元素的对齐单位不能超过最大对齐单位
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
// 检测内存是否超过限制
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// 当存储在 buf 中的元素不包含指针时,可以消除 GC 扫描
var c *hchan
switch {
case mem == 0:
// 如果是无缓冲 channel
// 仅为 hchan 分配内存空间
c = (*hchan)(mallocgc(hchanSize, nil, true))
// data race detector 使用当前作为检测点进行同步
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// 如果 channel 中的元素不包含指针
// 为 hchan 结构体和 buf 字段分配一段连续的内存空间
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 如果 channel 中的元素包含指针
// 分别为 hchan 结构体和 buf 字段单独分配内存空间
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 设置 channel 元素大小
c.elemsize = uint16(elem.size)
// 设置 channel 元素类型
c.elemtype = elem
// 设置 channel 缓冲区长度
c.dataqsiz = uint(size)
if debugChan {
// 如果开启了 debug 模式
// 打印初始化信息
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}
发送数据
chansend 方法
编译器会将应用层代码中的 c <- x 语句转换为 chansend1 函数调用。
//go:nosplit
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
// 编译器将
//
// select {
// case c <- v:
// ... foo
// default:
// ... bar
// }
//
// 转换为
//
// if selectnbsend(c, v) {
// ... foo
// } else {
// ... bar
// }
//
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {
return chansend(c, elem, false, getcallerpc())
}
chansend1 和 selectnbsend 函数内部调用的都是 chansend 函数, chansend 函数向 channel 发送数据,并且返回是否发送成功。
chansend 函数内部的 channel 处理逻辑分为两种:
- 阻塞发送
- 非阻塞发送
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// channel == nil
// 例如
// var a chan int
// a <- 1
if c == nil {
if !block {
// 非阻塞模式下直接返回
return false
}
// nil channel 发送数据会永久阻塞
// 挂起当前 goroutine
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// channel 非阻塞且未关闭
// 并且缓冲区已满,直接返回
if !block && c.closed == 0 && full(c) {
return false
}
// 加锁 (注意后续代码中不同条件下的解锁处理细节)
lock(&c.lock)
// channel 已经关闭,抛出 panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 如果存在等待接收的 goroutine
// 将数据发送给等待接收的 goroutine 后,直接返回
if sg := c.recvq.dequeue(); sg != nil {
// 将数据发送给队列第一个 goroutine
// 将数据直接传递给 goroutine,绕过 channel 缓冲区 (类似零拷贝的设计理念)
// 详情见: send 函数
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// qcount 是队列当前元素数量
// dataqsiz 是队列总长度
// 当前元素数量小于队列总长度时,说明还有空闲空间可供使用
if c.qcount < c.dataqsiz {
// 缓冲区未满,还有可用空间
// 获取下一个可以存放数据的地址 (缓冲区槽位)
qp := chanbuf(c, c.sendx)
// 将发送的数据拷贝到缓冲区
typedmemmove(c.elemtype, qp, ep)
// 发送索引 + 1
c.sendx++
// 环形队列,当发送索引等于队列长度时,索引重置为 0
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// 缓冲区元素数量 + 1
c.qcount++
// 解锁
unlock(&c.lock)
return true
}
// 队列没有空闲空间可供使用
// 直接返回
if !block {
unlock(&c.lock)
return false
}
// --------------------------
// 接下来的流程针对的是阻塞的情况
// --------------------------
// 获取当前发送数据的 goroutine
// 然后绑定到一个 sudog 结构体 (包装为运行时表示)
gp := getg()
// 获取 sudog 结构体
// 并且设置相关字段 (包括当前的 channel,是否是 select 等)
mysg := acquireSudog()
mysg.g = gp
mysg.isSelect = false
mysg.c = c
// 将 sudog 放入发送队列
c.sendq.enqueue(mysg)
// 挂起当前 goroutine, 进入休眠 (等待接收)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
// 确保发送的值一直处于有效状态,直到接收方将其复制出来
// sudog 有一个指向栈对象的指针,保持发送的数据处于活跃状态,避免被 GC
KeepAlive(ep)
// 取消 sudog 和 channel 绑定关系
mysg.c = nil
// 释放 sudog
releaseSudog(mysg)
if closed {
// goroutine 被唤醒后发现 channel 已关闭, 抛出 panic
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
return true
}
send 函数
send 函数用于处理 channel 数据的发送操作,函数会调用 sendDirect 直接将发送方的数据复制到接收方,或将等待接收的 goroutine 唤醒。
- 参数
sg表示接收方goroutine - 参数
ep表示要发送的数据
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if sg.elem != nil {
// 直接拷贝数据
sendDirect(c.elemtype, sg, ep)
}
...
// 调用 goready 函数将接收方 goroutine 唤醒并标记为可运行状态
// 并把其放入发送方所在处理器 P 的 runnext 字段等待执行
// runnext 字段表示最高优先级的 goroutine (GMP 调度器一文中讲过)
goready(gp, skip+1)
}
sendDirect 函数
sendDirect 函数用于 channel 具体的发送数据操作,将发送方 goroutine 的数据直接写入到接收方 goroutine。
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
...
}
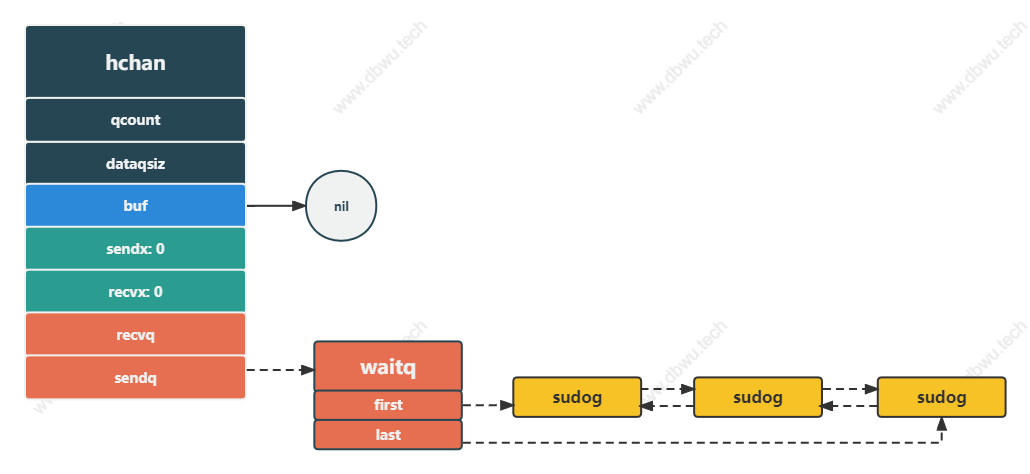
阻塞发送
channel 阻塞发送时,将 sudog 结构体放入发送队列:
非阻塞发送
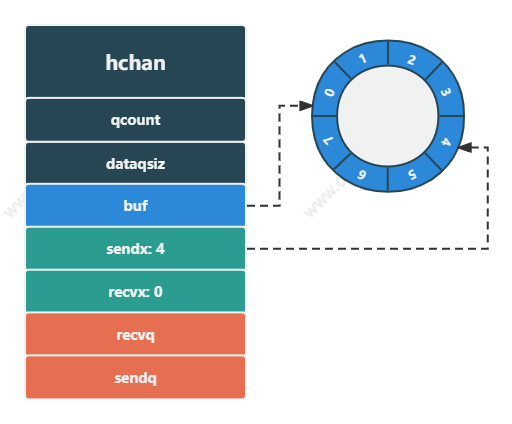
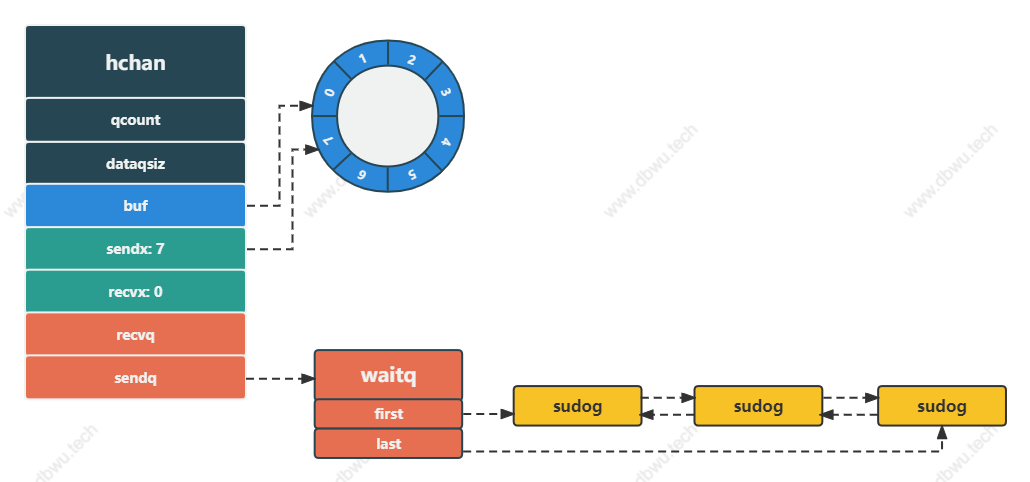
channel 非阻塞发送时,分为两种情况:
- 缓冲区未满,直接将数据存入缓冲区
- 缓冲区已满,将
sudog结构体放入发送队列
小结
channel 发送数据的条件分支:
- 如果
channel == nil, 非阻塞模式直接返回,阻塞模式,休眠当前goroutine - 如果
channel为非阻塞模式并且channel未关闭,同时缓冲区已满,直接返回 - 如果
channel已经关闭,发生panic - 如果
channel接收队列不为空, 出队第一个元素作为接收方goroutine,将数据发送给接收方goroutine后,直接返回 - 如果
channel缓冲区未满,将数据存入缓冲区,直接返回 - 如果以上条件都不满足,就获取一个新的
sudog结构体并放入channel的发送队列,同时挂起当前发送数据的goroutine, 进入休眠 (等待接收方接收数据)
接收数据
编译器会将应用层代码中的 <- ch 语句转换为 chanrecv1 函数调用。
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
编译器会将应用层代码中的 x, ok <- ch 语句转换为 chanrecv2 函数调用。
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
// 编译器将
//
// select {
// case v, ok = <-c:
// ... foo
// default:
// ... bar
// }
//
// 转换为
//
// if selected, ok = selectnbrecv(&v, c); selected {
// ... foo
// } else {
// ... bar
// }
//
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected, received bool) {
return chanrecv(c, elem, false)
}
chanrecv1 和 chanrecv2 以及 selectnbrecv 函数内部调用的都是 chanrecv 函数。
chanrecv 函数用于在 channel 上接收数据并将接收到的数据写入参数 ep (ep 可以设置为 nil, 这种情况下接收到的数据将会被忽略),并有两个返回值:
selected用于在select{}语句中表示是否会选中该分支received表示是否接收到了数据
根据参数的不同返回不同的值:
- 如果
block == false并且没有数据可用,返回 false, false - 如果
channel已经关闭,返回数据的零值和 false - 如果上述两种条件都不满足(说明有数据可用并且 channel 未关闭),将数据赋值给参数 *ep 然后返回 true, true
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if c == nil {
if !block {
// 非阻塞的情况下,直接返回
// 非阻塞出现在 select{} + default 场景
return
}
// 在 nil channel 上进行接收操作,会永久阻塞
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable") // 疑问:这行代码能执行到吗?
}
// 非阻塞模式并且接收数据操作会阻塞
// empty 函数返回 true 的情况:
// 1. 无缓冲 channel 并且没有发送方正在阻塞
// 2. 有缓冲 channel 并且缓冲区没有数据
if !block && empty(c) {
// 接下来再判断 channel 是否已经关闭
if atomic.Load(&c.closed) == 0 {
// 如果是未关闭的 channel, 非阻塞且没有可接收数据的情况下,直接返回
// 因为 channel 关闭后就无法再打开
// 所以只要 channel 未关闭,上述方法都是原子操作 (看到的结果都是一样的)
return
}
// 执行到这里,说明 channel 已经关闭
// channel 关闭后就无法再打开
// 重新检查 channel 是否存在等待接收的数据
if empty(c) {
// 没有任何等待接收的数据
if ep != nil {
typedmemclr(c.elemtype, ep) // 清理 ep 指针中的数据
}
return true, false
}
}
...
// 加锁 (注意后续代码中不同条件下的解锁处理细节)
lock(&c.lock)
if c.closed != 0 { // channel 已经关闭
if c.qcount == 0 { // 缓冲区也没有数据了
unlock(&c.lock) // 解锁
if ep != nil {
typedmemclr(c.elemtype, ep) // 清理 ep 指针中的数据
}
return true, false
}
} else {
// 先检测发送的队列是否不为空
// 不为空说明有阻塞在等待发送的 goroutine
if sg := c.sendq.dequeue(); sg != nil {
// 出队发送队列第一个 goroutine
// 如果缓冲区还有剩余的可用空间,直接从发送 goroutine 接收数据
// 否则,从接收队列头部的 goroutine 开始接收数据,并将数据添加到发送队列尾部的 goroutine
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
}
// 如果 channel 缓冲区还有数据
if c.qcount > 0 {
// 获取 channel 接收地址
qp := chanbuf(c, c.recvx)
if ep != nil {
// 直接拷贝数据到接收地址
typedmemmove(c.elemtype, ep, qp)
}
// 清除缓冲区数据
typedmemclr(c.elemtype, qp)
// 接收索引 + 1
c.recvx++
// 环形队列,当索引等于队列长度时,索引重置为 0
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 缓冲区元素数量 - 1
c.qcount--
// 解锁
unlock(&c.lock)
return true, true
}
// 如果是非阻塞并且无数据可接收
// 直接返回
if !block {
unlock(&c.lock)
return false, false
}
// --------------------------
// 接下来的流程针对的是阻塞的情况
// --------------------------
// 获取当前发送数据的 goroutine
// 然后绑定到一个 sudog 结构体 (包装为运行时表示)
gp := getg()
// 获取 sudog 结构体
// 并且设置相关数据 (包括当前的 channel,是否是 select 等)
mysg := acquireSudog()
mysg.g = gp
mysg.isSelect = false
mysg.c = c
// 将 sudog 放入接收队列
c.recvq.enqueue(mysg)
// 挂起当前 goroutine, 进入休眠 (等待发送方发送数据)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
// 取消 sudog 和 channel 绑定关系
mysg.c = nil
// 释放 sudog
releaseSudog(mysg)
return true, success
}
recv 函数
recv 函数用于处理 channel 的数据接收操作。
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 无缓冲 channel
if c.dataqsiz == 0 {
if ep != nil {
// 直接从发送方拷贝数据
recvDirect(c.elemtype, sg, ep)
}
} else {
// 获取缓冲区首元素
qp := chanbuf(c, c.recvx)
if ep != nil {
// 从缓冲区拷贝数据到接收方
typedmemmove(c.elemtype, ep, qp)
}
// 从发送方拷贝数据到缓冲区
typedmemmove(c.elemtype, qp, sg.elem)
// 接收索引 + 1
c.recvx++
// 环形队列,当索引等于队列长度时,索引重置为 0
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 除了更新接收索引外,还要更新发送索引 (赋值为更新后的接收索引值)
// 这样下次写入发送数据时,才能保证写入位置正确
c.sendx = c.recvx
}
...
// 调用 goready 函数将接收方 goroutine 唤醒并标记为可运行状态
// 并把其放入接收方所在处理器 P 的 runnext 字段等待执行
goready(gp, skip+1)
}
recvDirect 函数
recvDirect 函数和 sendDirect 函数作用一致,这里不再赘述。
func recvDirect(t *_type, sg *sudog, dst unsafe.Pointer) {
...
}
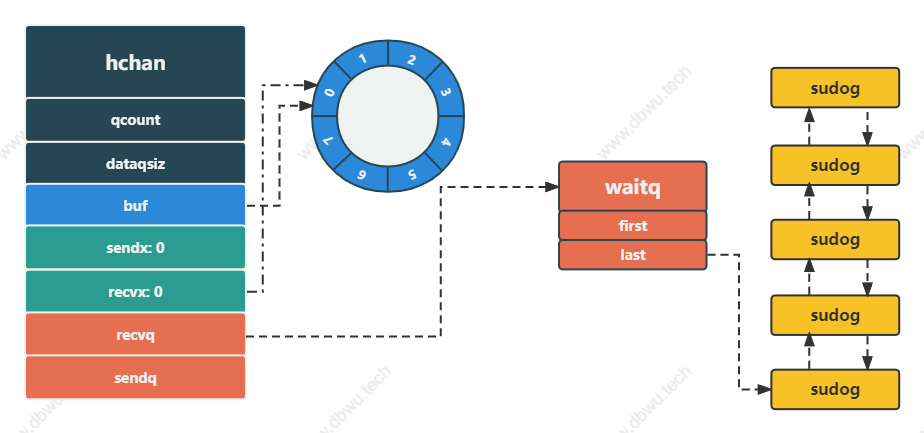
阻塞接收
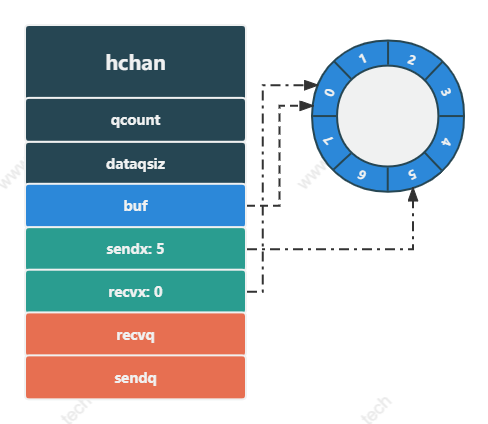
非阻塞接收
channel 非阻塞接收时,分为两种情况:
- 缓冲区不为空,直接从缓冲区读取数据
- 缓冲区为空,将
sudog结构体放入接收队列
小结
channel 接收数据的条件分支:
- 如果
channel == nil, 非阻塞模式直接返回,阻塞模式,休眠当前goroutine - 如果
channel已经关闭或者缓冲区没有等待接收的数据,直接返回 - 如果
channel发送队列不为空, 出队第一个元素作为发送方goroutine,将数据发送给接收方goroutine后,直接返回 - 如果
channel缓冲区有数据,直接从缓冲区读取数据 - 如果以上条件都不满足,就获取一个新的
sudog结构体并放入channel的接收队列,同时挂起当前发送数据的goroutine, 进入休眠 (等待发送方发送数据)
关闭 channel
编译器会将应用层代码中的 clsoe(channel name) 语句转换为 closechan 函数调用。
func closechan(c *hchan) {
// 关闭一个 nil channel, 抛出 panic
if c == nil {
panic(plainError("close of nil channel"))
}
// 加锁,这个锁的粒度比较大
// 会持续到释放完所有的 sudog 才解锁
lock(&c.lock)
// 关闭一个已经关闭的 channel, 抛出 panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
...
// 设置 channel 状态为已关闭
c.closed = 1
// goroutine 列表
// 用于存放发送+接收队列中的所有 goroutine
var glist gList
// 将接收队列中所有 goroutine 加入 gList 列表
for {
sg := c.recvq.dequeue()
// 出队的 sudog 为 nil
// 说明接收队列为空,直接跳出循环
if sg == nil {
break
}
// 将 sg 对应的 goroutine 添加到 glist 列表
glist.push(gp)
}
// 将发送队列中所有 goroutine 加入 gList 列表
// 当然,因为 channel 已经关闭,所以这些 goroutine 被唤醒后发生数据时会直接 panic
for {
sg := c.sendq.dequeue()
// 出队的 sudog 为 nil
// 说明发送队列为空,直接跳出循环
if sg == nil {
break
}
// 将 sg 对应的 goroutine 添加到 glist 列表
glist.push(gp)
}
// 解锁
unlock(&c.lock)
// 将出队的所有 goroutine 设置为可运行状态
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
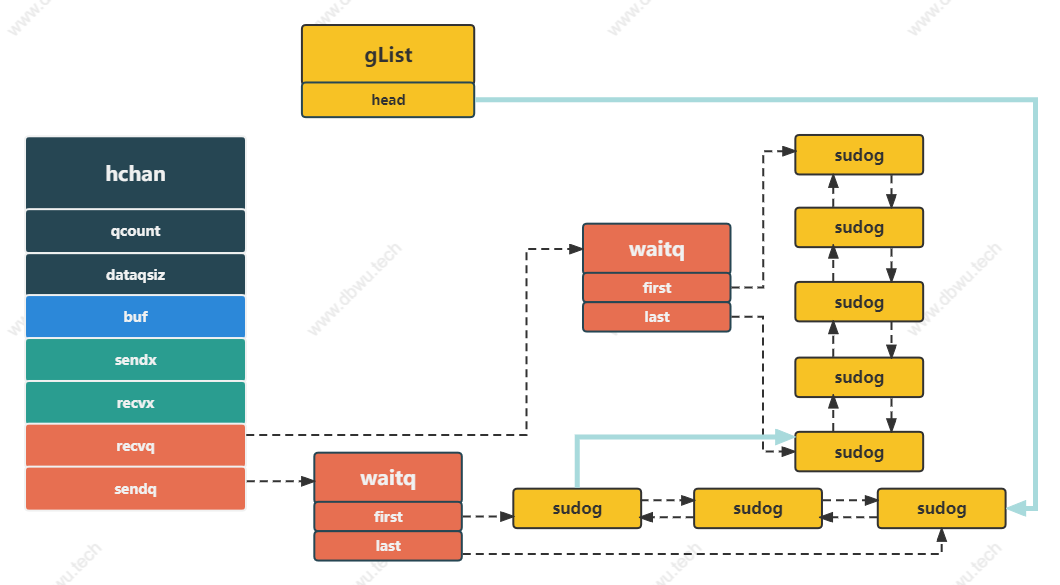
示意图
这里需要注意的是: gList 是一个栈数据结构 (后进先出),所以调用 glist.pop 方法时,首先出队的是发送队列的最后一个 goroutine,
最后出队的是接收队列的第一个 goroutine (图中两条青色的线条),虽然顺序相反,但是数据的发送/接收不会受到影响。
辅助函数
empty
empty 函数检测从 channel 读取数据是否会阻塞 (也就是检测 channel 缓冲区是否为空),主要分为两种情况:
- 如果
channel没有缓冲区,查看是否存在发送数据goroutine - 如果
channel有缓冲区,检查元素数量是否等于 0
func empty(c *hchan) bool {
if c.dataqsiz == 0 {
return atomic.Loadp(unsafe.Pointer(&c.sendq.first)) == nil
}
return atomic.Loaduint(&c.qcount) == 0
}
chanbuf
chanbuf 函数用于获取缓冲区下一个地址 (缓冲区槽位),chanbuf(c, i) 表示指向缓冲区中第 i 个槽位的指针。
func chanbuf(c *hchan, i uint) unsafe.Pointer {
return add(c.buf, uintptr(i)*uintptr(c.elemsize))
}
full
full 函数检测 channel 缓冲区是否已满,主要分为两种情况:
- 如果
channel没有缓冲区,查看是否存在接收者 - 如果
channel有缓冲区, 比较元素数量和缓冲区长度是否一致
func full(c *hchan) bool {
if c.dataqsiz == 0 {
return c.recvq.first == nil
}
return c.qcount == c.dataqsiz
}
enqueue
enqueue 方法用于将 goroutine 放入 channel 的发送/接收队列 (入队操作),内部实现就是链表操作。
func (q *waitq) enqueue(sgp *sudog) {
...
}
dequeue
dequeue 方法用于出队 channel 的发送/接收队列的一个元素 (出队操作),内部实现就是链表操作。
func (q *waitq) dequeue() *sudog {
...
}
FAQ
close channel 设计理念
func closechan(c *hchan) {
// 关闭一个 nil channel, 抛出 panic
if c == nil {
panic(plainError("close of nil channel"))
}
}
为什么关闭一个已经关闭的 channel 会 panic ?
官方这样设计的初衷,应该是希望开发者不要依赖于 close 函数,而是要求开发者通过合理设计 goroutine + channel 工作流来提高程序的健壮性。
如何检测 channel 是否已关闭
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int)
go func() {
if val, ok := <-ch; !ok {
fmt.Println("channel closed")
} else {
fmt.Printf("val = %d", val)
}
}()
ch <- 1024
close(ch)
time.Sleep(time.Second)
}
如何实现健壮的 channel close 方法
关闭一个已经关闭的 channel 会 panic, 实现一个方法,可以让调用方无需考虑边界情况,直接调用即可。
下面的代码只是作为技术解决方案探究,没有任何实际意义 (不要应用在任何业务中)。
1. recover
通过 recover 函数捕获 panic, 可以保证关闭一个已经关闭的 channel 报错不会导致程序终止。
package main
import (
"fmt"
)
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Printf("recover err: %v\n", err)
}
}()
ch := make(chan int)
close(ch)
// 关闭一个已经关闭的 channel
close(ch)
}
2. sync.Once
通过 sync.Once 方法保证 close(channel) 只会被调用一次。
package main
import (
"sync"
)
type myChan struct {
ch chan int
once sync.Once
}
func (c *myChan) close() {
c.once.Do(func() {
close(c.ch)
})
}
func main() {
ch := &myChan{
ch: make(chan int),
}
ch.close()
// 关闭一个已经关闭的 channel
ch.close()
}
3. atomic.CAS
通过 atomic.CAS 方法保证 close(channel) 只会被调用一次。
package main
import "sync/atomic"
type myChan struct {
ch chan int
closed int32
}
func (c *myChan) close() {
if atomic.CompareAndSwapInt32(&c.closed, 0, 1) {
close(c.ch)
}
}
func main() {
ch := &myChan{
ch: make(chan int),
}
ch.close()
// 关闭一个已经关闭的 channel
ch.close()
}
4. context.Context
通过 context.Context 保证 close(channel) 的操作顺序同步。
package main
import (
"context"
)
type myChan struct {
ch chan int
ctx context.Context
cancel context.CancelFunc
}
func (c *myChan) close() {
select {
case <-c.ctx.Done():
return
default:
close(c.ch)
// 事件同步
c.cancel()
}
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
ch := &myChan{
ch: make(chan int),
ctx: ctx,
cancel: cancel,
}
ch.close()
// 关闭一个已经关闭的 channel
ch.close()
}
channel 最佳实践
- channel 类型作为参数时,指定操作类型 (读/写)
- 使用
select + default处理多个channel轮询场景 - 永远不要在读取方向关闭
channel, 只在写入端关闭 channel - 不要依赖任何应用层实现的
channel关闭检测方法函数,应该将channel的读写操作进行分离 (通过不同的goroutine),并实现只在一个写入端关闭 channel - 使用
context.Context控制channel的生命周期 - 充分考虑缓冲和非缓冲
channel的使用场景- 无缓冲
channel提供了阻塞机制,虽然避免了数据竞态,但是当数据较多时降低了性能,而且可能引发死锁 - 缓冲
channel虽然避免了阻塞,但是有潜在的数据竞态,而且需要考虑缓冲区大小,设计不合理容易浪费资源
- 无缓冲
channel 和锁如何选择?
当你发现使用锁使程序变得复杂时,可以试试使用 channel 会不会使程序变得简单。
锁的使用场景
- 访问共享数据结构中的缓存信息
- 保存应用程序上下文和状态信息
- 保护某个结构内部状态和完整性
- 高性能要求的临界区代码
channel 的使用场景
- 线程 (goroutine) 通信
- 并发通信
- 异步操作
- 任务分发
- 传递数据所有权
- 数据逻辑组合 (如 Pipeline, FanIn FanOut 等并发模式)
官方给出的建议是除了特殊的、底层的应用程序外,其他情况最好使用 channel 或其他同步原语来完成 (但是从大多数开源组件实现代码来看,并没有遵守官方的建议)。
小结
本文着重介绍了 channel 的运行时数据结构和常见的三个操作 (发送数据、接收数据、关闭 channel) 对应的底层算法实现,标准库中 channel 文件源代码有将近 900 行,
但是核心在于 hchan 结构体以及围绕该结构体实现的各个函数方法,重点是 hchan 结构体中的 环形队列、发送/接收索引, 发送/接收链表 字段,
理解了这 3 个字段对应的数据结构和算法,channel 的设计与实现也就完全理解了。
