Go map 设计与实现
概述
在计算机科学中,关联数组 (
Associative Array),又称映射 (Map)、字典 (Dictionary) 是一个抽象的数据结构,它包含着类似于(键,值)的有序对。
从应用的角度来看,Go 语言的 map 数据结构主要有以下常见问题:
- 未初始化写入时报错
- 遍历时无序
- 非并发安全
本文通过分析标准库中 map 的内部实现,尝试解答上面的问题。
内部实现
map 的源代码文件路径为 $GOROOT/src/runtime/map.go,笔者的 Go 版本为 go1.19 linux/amd64。
相关常量
const (
bucketCntBits = 3
// 8: 一个 bucket 存放元素的数量上限
bucketCnt = 1 << bucketCntBits
// 触发扩容的负载因子: 6.5
// 官方的解释是这个值是根据测试结果统计出来的
// 负载量超过负载因子时,发生扩容
// 负载量 = 元素数量 / bucket 桶数量
loadFactorNum = 13
loadFactorDen = 2
// 保持内联的键值对大小上限, 超过这个大小,键和值会被转换为指针
// 必须在 uint8 所表示的范围内 [0 - 255]
maxKeySize = 128
maxElemSize = 128
// 数据偏移量根据 bmap 结构体的大小进行对齐
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
// tophash 除了放正常的高 8 位的 hash 值
// 还会在空闲、迁移时存储一些自定义的状态值
emptyRest = 0 // 槽未使用,且在较高的索引或溢出处不再有非空单元
emptyOne = 1 // 槽未使用
evacuatedX = 2 // 对应的键值存在,并且已经迁移到扩容后的 map 的前半部分
evacuatedY = 3 // 对应的键值存在,并且已经迁移到扩容后的 map 的后半部分
evacuatedEmpty = 4 // 槽未使用, 桶迁移完成
minTopHash = 5 // 正常填充槽的最小 TopHash 值
iterator = 1 // 可能有一个使用 bucket 的迭代器
oldIterator = 2 // 可能有一个使用 oldbuckets 的迭代器
hashWriting = 4 // 一个等待写入 map 的 goroutine
sameSizeGrow = 8 // 等量扩容: 当前的 map 增长是一个相同大小的新 map
// 用于迭代器检查的哨兵 bucket ID
noCheck = 1<<(8*goarch.PtrSize) - 1
)
我们暂时只需要关注两个常量数值:
- 单个
bucket最多可以放 8 个元素 map负载因子上限为 6.5
map 负载量的计算方式为:
负载量 = 元素数量 / bucket 桶数量
数据结构
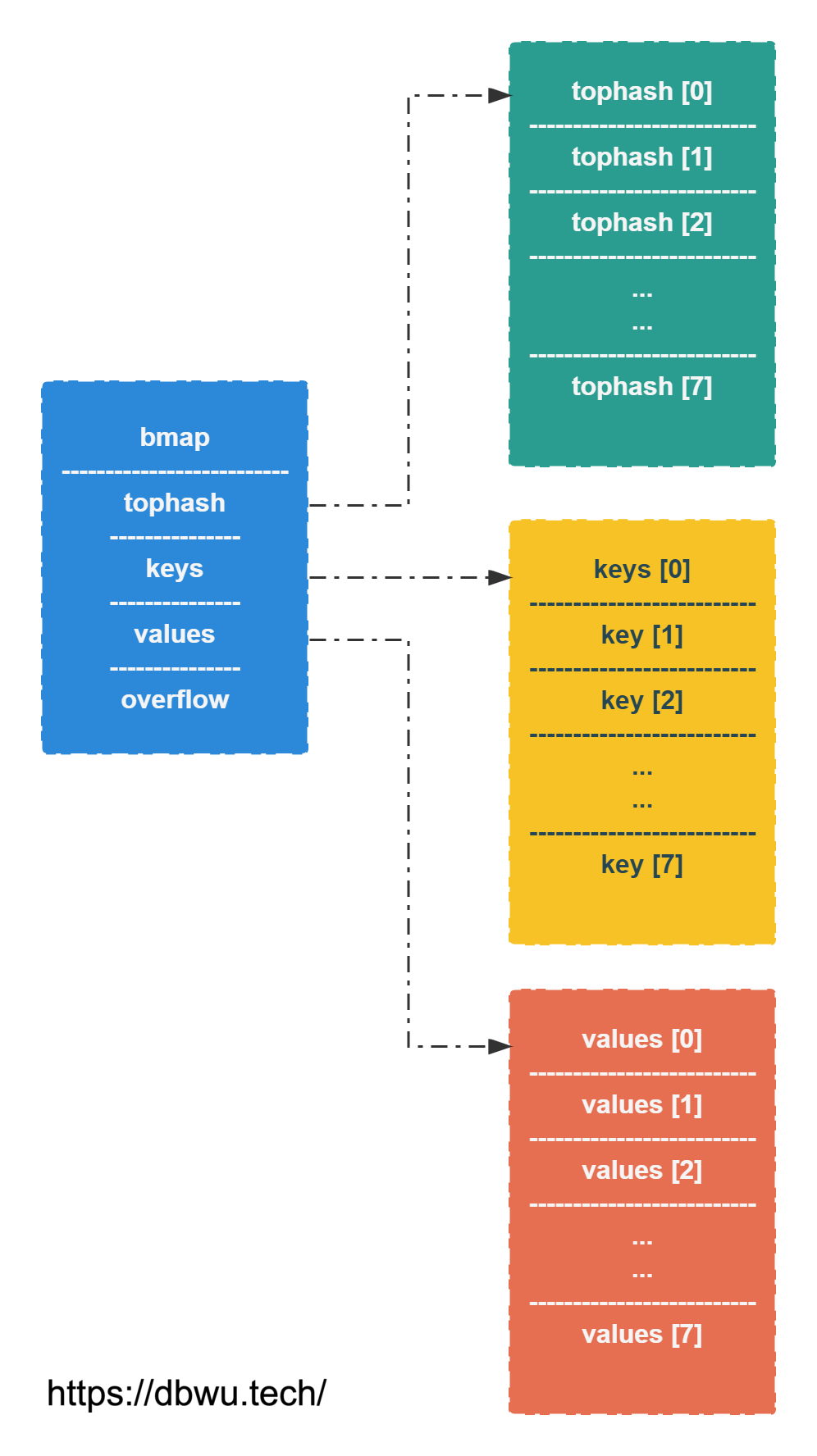
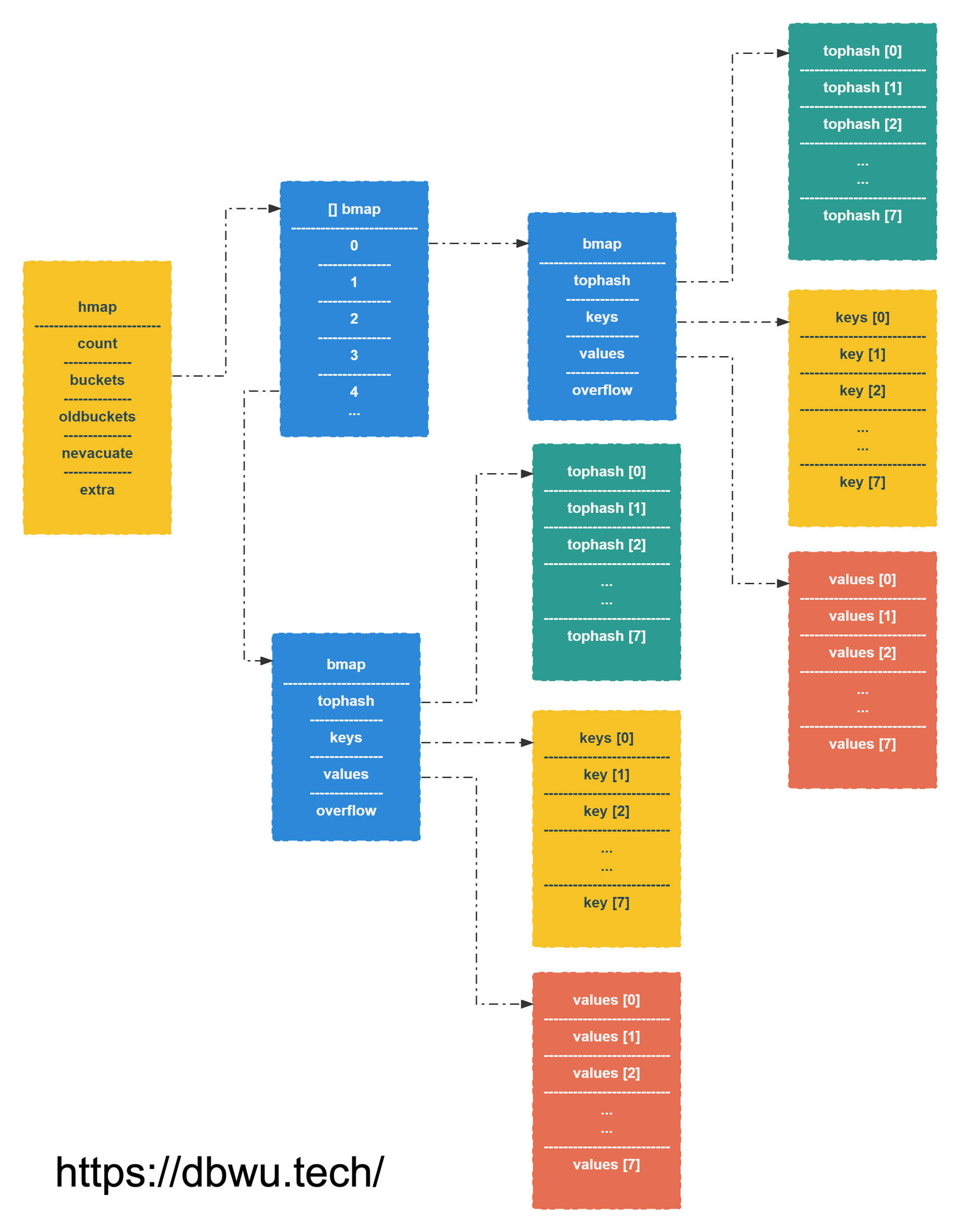
bmap 对象
bmap 对象表示 map 中用于存储数据的 bucket, 也就是数据桶。
type bmap struct {
// tophash 通常包含此 bucket 中每个 key 的 hash 值高位字节
// 如果 tophash[0] < minTopHash, 那么其表示 bucket 的迁移状态
tophash [bucketCnt]uint8
}
编译器会将 bmap 结构体转换为下面的结构体:
type bmap struct {
tophash [bucketCnt]uint8
keys [bucketCnt]keytype
values [bucketCnt]valuetype
// 溢出 bucket 的指针
overflow uintptr
}
需要注意的是: key + value 并不是配对存储的,而是分别存储在不同的数组中。把所有的 key 放在一起,然后把所有的 value 放在一起,
可以消除为了内存对齐而导致的内存填充 (主要是为了节省内存),如 map[int64]int8 这种较为极端的情况。
| 配对存储 | 独立存储 | |
|---|---|---|
| map[int64]int8 | 128 字节 | 72 字节 |
- 在配对存储时,需要内存对齐,所以单个
key/value大小为 16 字节,8 个元素一共 128 字节 - 在独立存储时,不需要内存对齐,8 个键 64 字节,8 个元素 8 字节,一共 72 字节
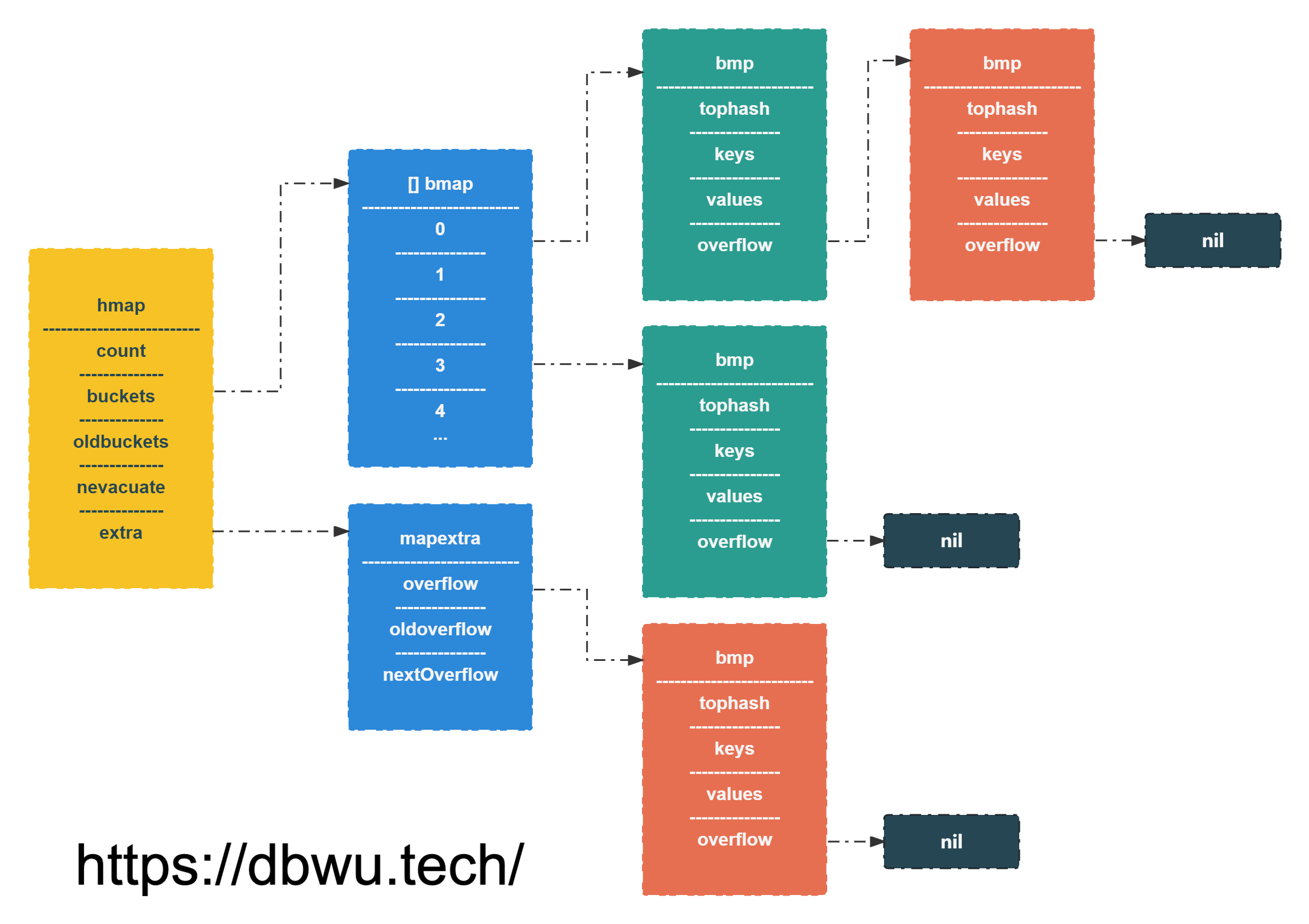
mapextra 对象
如果 map 的键和值都不包含指针,并且可以被内联 (<=128 bytes), 那么标记 bucket 桶不含指针,这样可以避免 GC 扫描。
但是 bmap.overflow 字段是一个指针,为了保证溢出的 bucket 桶存活 (不被 GC),在 hmap.extra.overflow 和 hmap.extra.oldoverflow 中存储了指向所有溢出桶的指针。
type mapextra struct {
// overflow 和 oldoverflow 仅在 key 和 elem 都不包含指针时使用
// overflow 包含 hmap.buckets 的溢出桶
// oldoverflow 包含 hmap.oldbuckets 的溢出桶
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow 指向空闲的溢出桶
nextOverflow *bmap
}
hmap 对象
hmap 对象表示 map 数据类型的主体结构。
type hmap struct {
// map 中的元素个数
// 必须放在 struct 的第一个位置
// 因为内置的 len 函数会从这里读取 (减少指令,提升性能,和 sync.Once 的 done 字段作用一样)
count int
flags uint8
// bucket 桶数量对应的指数
// bucket 桶数量 = 2^B
// 超过 6.5 * 2^B 个元素,就需要扩容
B uint8
// 溢出 bucket 桶的数量
noverflow uint16
// 哈希种子, 为哈希函数的结果引入随机性
hash0 uint32
// bucket 桶存放数据的数组
// 如果 count 字段等于 0,则为 nil
buckets unsafe.Pointer
// 只有在扩容期间不为 nil
// 扩容期间指向 buckets
oldbuckets unsafe.Pointer
// 迁移进度计数器
// 小于计数器的 bucket 桶表示已经迁移完成
nevacuate uintptr
// 当键和值都可以内联的时,就会使用这个字段
extra *mapextra
}
方法
makemap_small 方法
makemap_small 方法实现了两种 map 创建方式:
- 零长度
map, 例如 make(map[k]v) - 长度较小的
map, 例如 make(map[k]v, hint), 前提是在编译时可以推断出参数hint最多为 8 并且分配到堆上
func makemap_small() *hmap {
h := new(hmap)
// 生成哈希种子
h.hash0 = fastrand()
return h
}
makemap 方法
如果创建的 map 不符合 makemap_small 方法的条件, 会调用 makemap 方法来创建。
// 如果 h != nil, map 可以在 h 中创建
// 如果 h.buckets != nil, 可以复用 h.buckets 数组
func makemap(t *maptype, hint int, h *hmap) *hmap {
if h == nil {
h = new(hmap)
}
// 生成哈希种子
h.hash0 = fastrand()
// 计算需要的 bucket 数量
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 创建 bucket 桶用于保存数据的数组
// 如果 B == 0, buckets 字段懒加载
// 如果 map 长度较大,那么这部分内存初始化会花较长时间
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
mapaccess2 方法
mapaccess1,mapaccess2,mapaccessK 几个方法差不多,都可以用来访问 map 元素,这里以 mapaccess2 作为示例说明。
mapaccess2 不仅可以返回参数 key 对应的元素,还可以返回第二个参数用来表示 key 对应的元素是否存在。
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
if h == nil || h.count == 0 {
// map == nil 或元素数量为 0, 直接返回未找到
return unsafe.Pointer(&zeroVal[0]), false
}
if h.flags&hashWriting != 0 {
// 并发读写 map 错误
throw("concurrent map read and map write")
}
// 不同类型的 key,所用的 hash 算法是不一样的
hash := t.hasher(key, uintptr(h.hash0))
// 找到对应的 bucket 桶
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 如果 map 正在扩容
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// 如果当前扩容机制是翻倍扩容
// 说明之前的 buckets 只有现在的一半
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
// 如果旧桶中的数据还未迁移完成
// 说明 key 对应的值可能存在于旧桶中
b = oldb
}
}
// 取高 8 位的值
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
// 一个桶在满 8 个元素后,会创建新的桶
// 然后挂在原来的桶的 overflow 指针上
for i := uintptr(0); i < bucketCnt; i++ {
// 循环对比桶中各个元素的哈希值
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
// 如果当前元素后面的元素都是空的,说明没有更多的元素了
// 直接跳转到下一个溢出桶
break bucketloop
}
continue
}
// 如果找到了相等的哈希值,那说明 key 对应的值可能存在于当前桶中
// 根据偏移量取出对应的 key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.key.equal(key, k) {
// 仅当当前 key 和参数 key 完全相同时
// 才说明对应的元素找到了
return e, true
}
}
}
// 没有找到 key 对应的值,返回零值和 false
return unsafe.Pointer(&zeroVal[0]), false
}
mapassign 方法
mapassign 方法用于设置 map 的值 ,和 mapaccess 方法不同的地方在于: 如果 key 不存在于 map 中,则为它分配对应的槽,然后设置值。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
// map 未初始化时不能赋值
panic(plainError("assignment to entry in nil map"))
}
if h.flags&hashWriting != 0 {
// 并发写错误
throw("concurrent map writes")
}
// 调用对应类型的 hash 算法
hash := t.hasher(key, uintptr(h.hash0))
// 调用 hash 算法后设置 hashWriting 状态标识
// 因为 t.hasher 可能发生 panic, 此时实际的设置操作还未完成
h.flags ^= hashWriting
// 初始化第一个桶
if h.buckets == nil {
h.buckets = newobject(t.bucket)
}
again:
// 计算低 8 位
bucket := hash & bucketMask(h.B)
if h.growing() {
// 如果 map 当前正在扩容
// 顺便调用一次增量扩容
growWork(t, h, bucket)
}
// 计算出存储的桶地址, 转换为 bucket 对象
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
// 计算高 8 位
top := tophash(hash)
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
// 循环对比桶中各个元素的哈希值
if b.tophash[i] != top {
// 在 b.tophash[i] != top 的情况下
// 理论上有可能会是一个空槽位
// 一般情况下 map 的槽位分布是这样的,e 表示 empty:
// [h1][h2][h3][h4][h5][e][e][e]
// 但在执行过 delete 操作时,可能会变成这样:
// [h1][h2][e][e][h5][e][e][e]
// 所以如果再插入的话,会尽量往前面的位置插入
// [h1][h2][e][e][h5][e][e][e]
// ^
// ^
// 这个位置
// 所以在循环的时候还要顺便把前面的空位置先记下来
if isEmpty(b.tophash[i]) && inserti == nil {
// 如果这个槽位没有被占,说明可以往这里放入 key 和 value
...
}
if b.tophash[i] == emptyRest {
// 如果当前元素后面的元素都是空的,说明没有更多的元素了
// 直接跳转到下一个溢出桶
break bucketloop
}
continue
}
// 如果找到了相等的哈希值,那说明 key 对应的值可能存在于当前桶中
// 根据偏移量取出对应的 key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// 如果两个 key 的首 8 位、最后 8 位 hash 值一样,会进行比较,和处理 hash 碰撞一样
// 如果相同的哈希位置的 key 和要插入的 key 不相等
// 直接跳过
if !t.key.equal(key, k) {
continue
}
// 如果当前 key 和参数 key 完全相同
// 但是对应的位置已经有值了,直接更新
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
// 设置完成,直接跳转到 done 条件标签
goto done
}
// 当前桶没有可用的位置,从溢出桶继续查找
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// 没有找到 key, 分配新的内存空间
// 如果触发了负载因子上限或者已经有太多溢出 bucket,并且当前没有在进行扩容,那么开始扩容操作
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
// 扩容的时候会把当前的 bucket 桶放入 oldbucket
// 如果还没有分配新的 bucket 桶, 则跳转到 again 重试一次
// 重试的时候在 growWork 方法里会把这个 key 对应的 bucket 桶提前分配好
goto again
}
if inserti == nil {
// 当前的桶和它挂载的溢出桶都满了,分配一个新的桶
...
}
// 将键值存储到对应的位置
...
// map 元素数量 + 1
h.count++
done:
if h.flags&hashWriting == 0 {
// 并发写错误
throw("concurrent map writes")
}
return elem
}
mapdelete 方法
mapdelete 方法用于删除 map 中指定的 key, 其内部逻辑和 mapassign 赋值方法大多数都是相同的。
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
// 如果 map 还未初始化或元素数量为 0, 直接返回
if h == nil || h.count == 0 {
return
}
if h.flags&hashWriting != 0 {
// 并发写错误
throw("concurrent map writes")
}
// 调用对应类型的 hash 算法
hash := t.hasher(key, uintptr(h.hash0))
// 调用 hash 算法后设置 hashWriting 状态标识
// 因为 t.hasher 可能发生 panic, 此时实际的删除操作还未完成
h.flags ^= hashWriting
// 计算低 8 位
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
// 计算出存储的桶地址, 转换为 bmap 结构
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
// 计算高 8 位
top := tophash(hash)
search:
for ; b != nil; b = b.overflow(t) {
// 循环对比桶中各个元素的哈希值
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
// 如果当前元素后面的元素都是空的,说明没有更多的元素了
// 直接跳转到下一个溢出桶
break search
}
continue
}
// 根据偏移量取出对应的 key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// 对应的槽标记为未使用
b.tophash[i] = emptyOne
// map 元素数量 + 1
h.count--
}
}
if h.flags&hashWriting == 0 {
// 并发写错误
throw("concurrent map writes")
}
}
makeBucketArray 方法
makeBucketArray 方法用于初始化 bucket 桶对应的底层数组。
- 参数
b表示 bucket 桶的数量对应的指数 (例如传入 3, 表示桶的数量为 2 ^ 3 = 8) - 参数
dirtyalloc表示是否复用其他的数组,如果为nil会分配一个新数组,否则会清空参数dirtyalloc,然后重用这部分内存作为新数组
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
// 当 bucket 数量小于 2^4 时
// 由于数据较少、使用溢出桶的可能性较低,会省略创建的过程以减少额外开销
// 当 bucket 桶的数量大于等于 2^4 时
// 额外创建 2 ^ (b - 4) 个溢出桶
if b >= 4 {
// 加上溢出桶的数量
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
if dirtyalloc == nil {
// 分配新的数组内存
buckets = newarray(t.bucket, int(nbuckets))
} else {
// 复用参数数组
buckets = dirtyalloc
size := t.bucket.size * nbuckets
if t.bucket.ptrdata != 0 {
memclrHasPointers(buckets, size)
} else {
memclrNoHeapPointers(buckets, size)
}
}
if base != nbuckets {
// 预分配一些溢出桶
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}
扩容
map 的性能会随着元素的增加而逐渐降低,此时需要扩容机制来保证性能,如果 map 当前不处于扩容状态,那么满足下列条件之一时会自动触发扩容:
- 负载量超过负载因子
6.5(计算方式见overLoadFactor方法) - 存在过多溢出桶 (计算方式见
tooManyOverflowBuckets方法)
扩容主要有两种扩容机制: 翻倍扩容和等量扩容,数据复制和迁移并不是阻塞式的原子过程,而是动态增量完成的 (每次迁移一部分数据)。
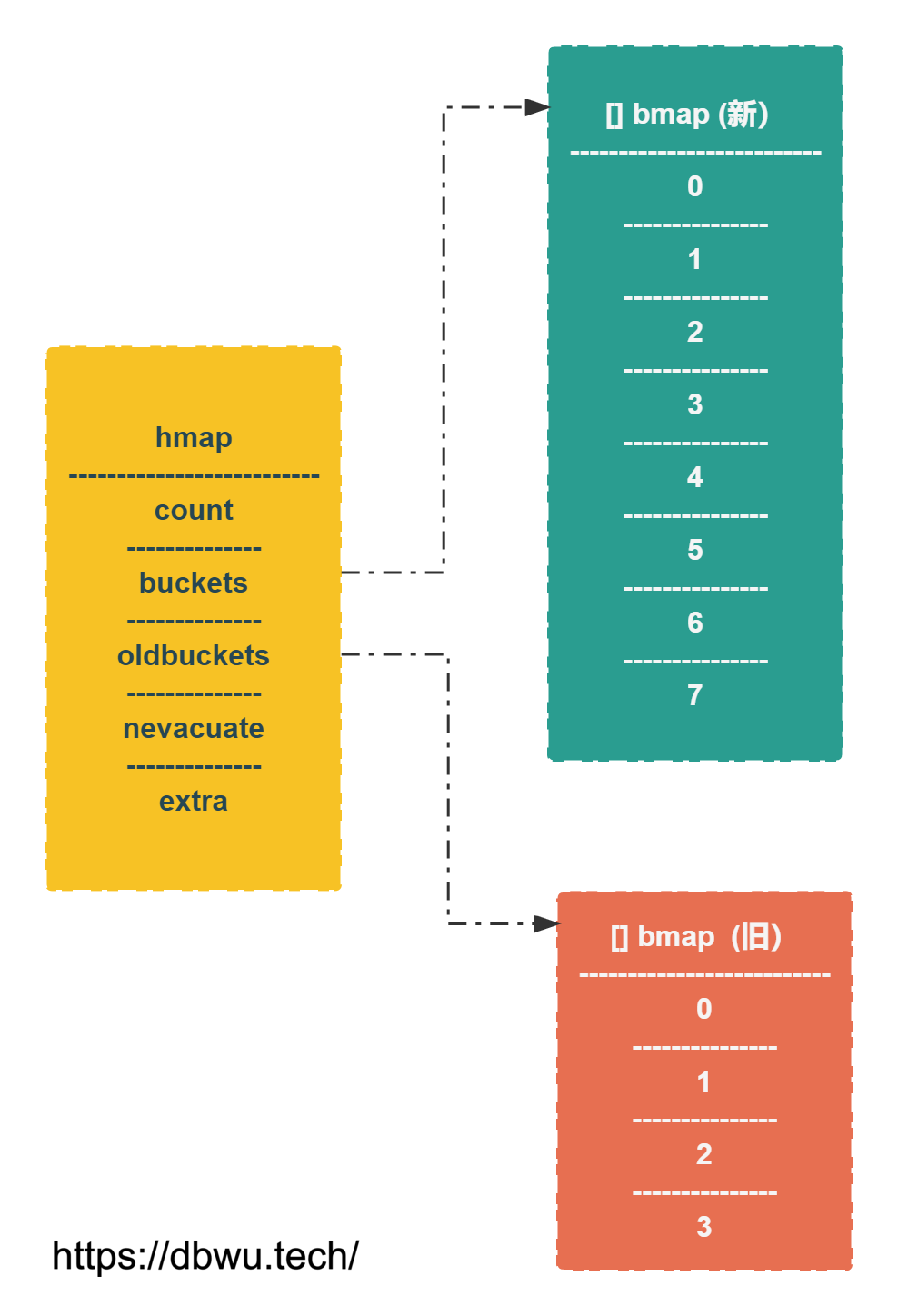
翻倍扩容
示例: 原来的 bucket 桶数量为 4 个,翻倍之后为 8 个。
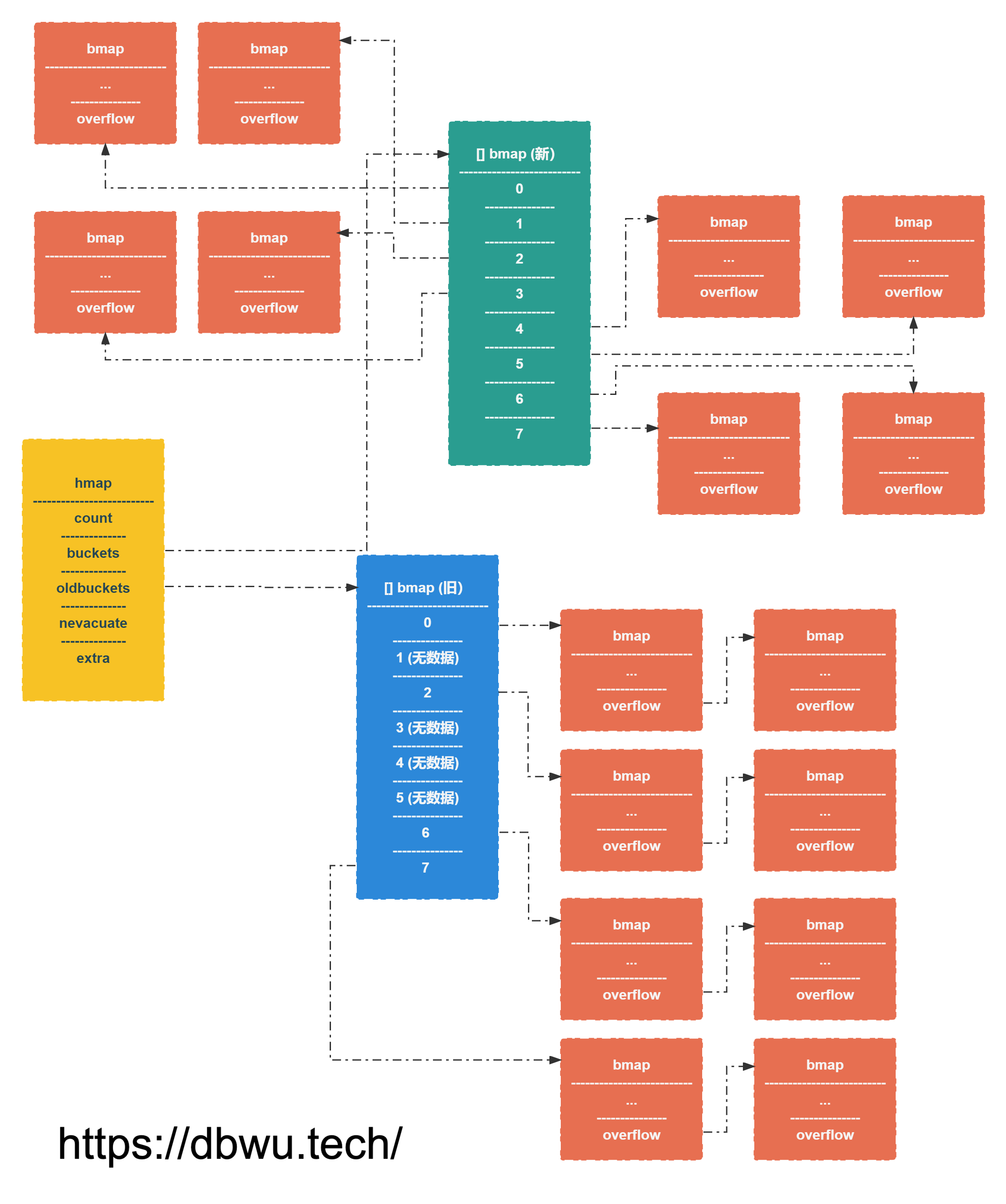
等量扩容
示例: 原来的 bucket 桶数量为 8 个,翻倍之后依然为 8 个,但是数据分布更加均匀了。
hashGrow 方法
不论是 翻倍扩容 还是 等量扩容, 最终调用的都是 hashGrow 方法。
如果
map当前的负载量已经超过负载因子 (6.5), 进行翻倍扩容 (h.B += 1),否则,说明存在过多的溢出桶,需要保持相同数量的桶并将数据横向填充 (等量扩容)。
func hashGrow(t *maptype, h *hmap) {
// 默认为翻倍扩容
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
// 等量扩容
bigger = 0
h.flags |= sameSizeGrow
}
// 扩容期间将 oldbuckets 也指向桶的指针
oldbuckets := h.buckets
// 分配的新桶
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
// 更新扩容的相关字段
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// 扩容导致的数据迁移计数器重置为 0
h.nevacuate = 0
// 溢出桶的数量重置为 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// 把当前的溢出桶赋值给老的溢出桶
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}
growWork 方法
扩容过程中的数据复制迁移工作是由
growWork方法和evacuate方法动态增量完成的**。
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 确保迁移的 oldbucket 桶与将要使用的 bucket 桶对应
evacuate(t, h, bucket&h.oldbucketmask())
// 如果正在扩容,多迁移一个 bucket 桶
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
evacuate 方法
evacuate 方法负责具体的数据迁移工作,它会将一个旧的 bucket 桶里面的数据分流到两个新的 bucket 桶。
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
// 如果是等量扩容
// x 表示同一个新 bucket 桶数组的前半部分 (用于存储当前桶的前半部分数据)
// y 表示同一个新 bucket 桶数组的后半部分 (用于存储当前桶的后半部分数据)
// 如果是翻倍扩容
// x 表示一个新 bucket 桶数组 (用于存储当前桶的前半部分数据)
// y 表示另一个新 bucket 桶数组 (用于存储当前桶的后半部分数据)
var xy [2]evacDst
x := &xy[0]
if !h.sameSizeGrow() {
// 如果 map 是翻倍扩容,计算 y
y := &xy[1]
}
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
var useY uint8
if !h.sameSizeGrow() {
// 计算 hash 以确认数据迁移的具体位置
// 也就是需要将当前这个键值对迁移到位置 x 还是位置 y
}
...
}
}
// 分离溢出桶, 清理键值对, 为 GC 做准备
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
...
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
advanceEvacuationMark 方法
advanceEvacuationMark 方法用于增加迁移进度计数器,并在扩容结束后释放 oldbuckets 和 extra.oldoverflow。
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
if h.nevacuate == newbit {
// 扩容结束,释放 oldbuckets
h.oldbuckets = nil
// 释放 oldoverflow
if h.extra != nil {
h.extra.oldoverflow = nil
}
}
}
newoverflow 方法
newoverflow 方法用于创建 bucket 桶,如果有预先分配的桶, 直接返回即可,如果没有的话,创建一个新的桶返回。
func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap {
var ovf *bmap
if h.extra != nil && h.extra.nextOverflow != nil {
// 有可用的预先分配的溢出桶
// 细节可以参考 makeBucketArray 方法的注释部分
ovf = h.extra.nextOverflow
if ovf.overflow(t) == nil {
// 还未到达最后一个预分配的溢出桶
// 让桶的溢出指针指向当前 bucket
h.extra.nextOverflow = (*bmap)(add(unsafe.Pointer(ovf), uintptr(t.bucketsize)))
} else {
// 这是最后一个预分配的溢出桶
// 重置这个桶的溢出指针,该指针被作为哨兵设置为非 nil 值
ovf.setoverflow(t, nil)
h.extra.nextOverflow = nil
}
} else {
// 没有可用的预先分配的溢出桶, 创建一个新桶
ovf = (*bmap)(newobject(t.bucket))
}
// 统计溢出桶的数量
h.incrnoverflow()
return ovf
}
createOverflow 方法
createOverflow 方法用于初始化溢出bucket 桶。
func (h *hmap) createOverflow() {
if h.extra == nil {
h.extra = new(mapextra)
}
if h.extra.overflow == nil {
h.extra.overflow = new([]*bmap)
}
}
incrnoverflow 方法
incrnoverflow 方法用于统计溢出 bucket 桶的数量。
- 需要保持溢出桶数量不能太多 (最多为 65535),因为
noverflow字段的数据类型为 uint16 - 当
bucket桶数量很少时,noverflow字段是一个精确的数值 - 当
bucket桶数量很多时,noverflow字段是一个模糊 (大概) 的数值
func (h *hmap) incrnoverflow() {
// 如果溢出桶的数量与正常桶的数量一样,触发等量扩容
if h.B < 16 {
// 精确统计
h.noverflow++
return
}
// 模糊统计
// 增加概率 1/(1<<(h.B-15))
// 当达到 1<<15 - 1 时,溢出桶的数量与正常桶的数量大致相同
mask := uint32(1)<<(h.B-15) - 1
// 例如: 如果 h.B 等于 18, mask 就等于 7
// 所以 fastrand() & mask == 0 的概率就是 1/8
if fastrand()&mask == 0 {
h.noverflow++
}
}
overLoadFactor 方法
overLoadFactor 方法返回负载量是否大于负载因子 (6.5)。
元素数量 > 桶数量 && 元素数量 > 桶数量 * 6.5
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
tooManyOverflowBuckets 方法
tooManyOverflowBuckets 方法返回 溢出桶 的数量是否多于 正常桶 的数量,参数 B 表示桶数量对应的指数,具体的判定条件为:
- 当 B < 15, 正常 bucket 桶数量小于 2^15, 溢出 bucket 桶数量大于 2^B
- 当 B >= 15, 正常 bucket 桶数量大于等于 2^15, 溢出 bucket 桶数量大于 2^15
方法名称中的 too many 语义表示 溢出桶 的数量和 正常桶 的数量大致相同,如果阈值太低,扩不扩容都差不多 (因为扩容后不久又会触发扩容),
如果阈值太高,扩容和缩容会引发大量未使用的内存 (很多不经常访问的数据占用着内存)。
// 注意,溢出 bucket 桶大多数应该访问次数很少
// 如果访问很频繁,应该已经触发了翻倍扩容
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}
小结
从应用层面来说,map 在使用前一定要进行初始化,如果对于存储数据的数量有大概的了解,可以在初始化时 预分配 一定的容量,可以有效提高性能。
从内部实现来说,map 通过编译器和运行时实现了常规操作,通过 拉链法 来解决哈希碰撞问题 (每个 bmap 对象都有一个 overflow 指针),
此外,通过将每个 bucket 中元素的前 8 位哈希值存入 tophash, 以空间换时间,可以加速遍历 bucket 中元素。
flag: map 代码较多且抽象,有时间将常见操作用图画出来,毕竟,一图胜千言 :-)
FAQ
为什么 map 未初始化写入时报错
因为 mapassign 方法限定了写入条件:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
}
如何判断两个 map 是否相等
map 和 slice 一样不可比较,只能和 nil 比较。
如果需要比较 map, 可以通过自定义方法实现,例如:
// 示例:判断两个 map 是否相等
func equal(x ,y map[string]int) bool {
if len(x) != len(y) {
return false
}
for k, xv := range x {
if yv, ok := y[k]; !ok || yv != xv {
return false
}
}
return true
}
或者直接调用标准库提供的 reflect.DeepEqual 方法。
map 是线程安全的吗
通过源代码中的 throw("concurrent map writes") 代码可以看到,map 只支持多个线程读,不支持多个线程读写或写入。
为什么遍历 map 是无序的
map 发生扩容后,大部分 key 对应的 bucket 都会发生变化,即使按照 bucket 顺序遍历,也不能保证每一次的顺序都是一样的。
官方不希望开发者想当然地认为 map 是有序的,所以每次都是从一个随机的 bucket 开始遍历 (每次遍历时下一个元素都是随机的)。
元素 slot 定位方式
- 计算出
key的哈希值 (不同类型的key使用的hash 算法是不一样的) - 通过哈希值最后的
hmap.B个bit, 计算出bucket桶的索引值 - 通过索引值的高 8 位计算出
bucket桶里面的具体的slot - 通过使用
slot对应的完整key和参数key进行对比,如果两者一致,说明参数key对应的元素已经找到 - 如果没有找到对应的元素,并且
bucket桶的overflow溢出桶不为nil, 那么接着去溢出桶中查找
map 的扩容过程
扩容发生在分配元素时,具体条件请参照 hashGrow 方法和 tooManyOverflowBuckets 方法的注释。
扩容主要分为 容量翻倍 和 横向填充 两种方式,前者主要针对 元素过多 的情况,后者主要针对 元素分布稀疏 的情况,
扩容过程并不是原子性的,而是在调用 元素分配, 元素删除 等写入方式操作时动态增量进行的,这样可以 避免原子操作时造成的瞬时抖动性能问题。
