为什么 recover 必须在 defer 中调用?
前言
开始正文之前,先来看看几个有趣的小问题:
- 为什么
panic可以让程序崩溃? - 为什么
recover可以捕获panic的消息并终止程序崩溃? - 为什么
recover必须在defer中调用? - 为什么
recover必须在defer中直接调用 (不能嵌套)?
内部实现
带着上面的几个小问题,我们从源代码的角度来探究一下, panic 和 recover 的实现相关文件目录为 $GOROOT/src/runtime,笔者的 Go 版本为 go1.19 linux/amd64。
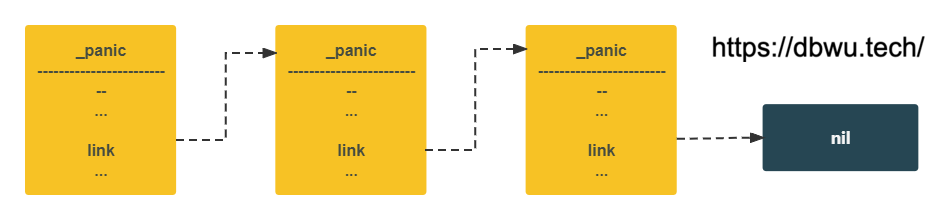
_panic 对象
_panic 对象表示 panic 语句 语句的运行时。
// runtime2.go
type _panic struct {
argp unsafe.Pointer // 指向调用 defer 时参数的指针
arg any // 指向调用 panic 时传入的参数
link *_panic // _panic 链表
pc uintptr // panic 被捕获后,继续执行的程序 sp (栈底) 寄存器
sp unsafe.Pointer // panic 被捕获后,继续执行的程序 pc (程序计数器) 寄存器 (下一条汇编指令的地址)
recovered bool // 当前 panic 是否被捕获
aborted bool // 当前 panic 是否被终止
// pc、sp 和 goexit 三个字段都是为了修复 runtime.Goexit 带来的问题引入的
// runtime.Goexit 能够只结束调用该函数的 goroutine 而不影响其他的 goroutine
// 但是该函数会被 defer 中的 panic 和 recover 取消
// 引入这三个字段就是为了保证 runtime.Goexit 函数一定会执行
goexit bool
}
gopanic 方法
gopanic 方法对应 panic 函数,编译器会将 panic 语句 转换为 gopanic 函数调用。
// panic.go
func gopanic(e any) {
// 获取当前 G
gp := getg()
// 生成一个新的 _panic 对象
var p _panic
p.arg = e
// 将 _panic 对象放在链表头部
p.link = gp._panic
gp._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
for {
// 获取 _defer 链表头节点
d := gp._defer
// 没有 _defer 对象, 自然也就没有 recover,直接跳出循环
// 意味着程序没有捕获 panic, 然后崩溃
if d == nil {
break
}
// defer 语句已经执行过了
// 如果 defer 是由之前的 panic 或 runtime.Goexit 执行的
// 并且触发了新的 panic, 也就是 defer 函数里再次 panic
// 将 defer 从列表中删除,之前的 panic 不会继续运行
// 但需要确保之前的 runtime.Goexit 继续运行
if d.started {
if d._panic != nil {
d._panic.aborted = true
}
d._panic = nil
if !d.openDefer {
d.fn = nil
// 从 defer 链表中删除当前 defer 对象
gp._defer = d.link
freedefer(d)
continue
}
}
// 标记 defer 已经执行
d.started = true
// 如果在 defer 调用期间发生了新的 panic
// 新的 panic 将在链表中找到当前 _defer
// 标记 d._panic (指向当前的 panic) 终止
d._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
d._panic = nil
// 获取 pc, sp 寄存器的值
pc := d.pc
sp := unsafe.Pointer(d.sp)
if p.recovered {
// p.recovered 字段已经在 gorecover 函数中被修改为 true
// 说明当前 panic 被捕获了
// 从 panic 链表中删除当前 panic 对象
gp._panic = p.link
if gp._panic != nil && gp._panic.goexit && gp._panic.aborted {
// 正常的恢复将绕过 Goexit
// 非正常的情况交给 Goexit 处理
}
gp._panic = p.link
// 如果链表的当前节点后面还有 _panic 对象
// 并且被标记为终止了,将它们从链表中删除
for gp._panic != nil && gp._panic.aborted {
gp._panic = gp._panic.link
}
// 将捕获到的 panic 消息传递给 recover 函数
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
// 恢复的时候 panic 函数将从此处跳出 (编译器实现)
// gopanic 调用结束,下面的两行代码不会执行
mcall(recovery)
throw("recovery failed")
}
}
fatalpanic(gp._panic)
}
fatalpanic 方法
fatalpanic 方法表示当 panic 没有被捕获时要执行的操作 (也就是结束程序)。
//go:nosplit
func fatalpanic(msgs *_panic) {
systemstack(func() {
// 程序结束错误码为 2
exit(2)
})
}
gorecover 方法
gorecover 方法对应 recover 函数,编译器会将 recover 语句转换为 gorecover 函数调用。
//go:nosplit
func gorecover(argp uintptr) any {
// recover 函数必须在 defer 函数中调用
// recover 函数必须从最顶层函数 (直接在 defer 语句或函数体中) 调用,也就是说不能出现 defer 嵌套
// p.argp 是最顶层的 defer 函数调用的参数指针,与 panic 函数的调用方的参数进行比较
// 如果匹配,调用方就可以 recover
gp := getg()
p := gp._panic
// 只处理一个 _panic, 标记完就返回
// 具体的捕获恢复处理逻辑在 gopanic 函数实现
if p != nil && !p.goexit && !p.recovered && argp == uintptr(p.argp) {
// 将 panic 标记为已捕获
p.recovered = true
// 返回 panic 的参数
return p.arg
}
return nil
}
recovery 方法
recovery 方法用于恢复 goroutine 的继续执行,通过重置寄存器并将 goroutine 重新加入调度队列。
func recovery(gp *g) {
// 恢复之前传入的 sp 和 pc
sp := gp.sigcode0 // 取出栈 sp
pc := gp.sigcode1 // 取出栈 pc
gp.sched.sp = sp // 重置栈 sp
gp.sched.pc = pc // 重置栈 pc
gp.sched.lr = 0
gp.sched.ret = 1
gogo(&gp.sched) // 加入调度队列
}
函数中的这句代码可以简单解释下:
gp.sched.ret = 1
这里并没有调用 deferproc 函数,但是直接修改了返回值,所以调度再次执行时会跳转到 deferproc 函数的下一条指令位置,设置为 1 是模拟 deferproc 函数返回值。
在上一篇分析 defer 源代码的时候,我们提到过:
如果 deferproc 返回值不等于 0, 说明 panic 被捕获到了
如果 deferproc 返回值等于 0, 说明 panic 没有被捕获
小结
panic + recover 的实现由编译器和运行时共同完成,通过对内部实现源代码的学习,我们可以更加深入理解 defer + panic+ recover 的内部实现,
现在来回答本文开头提到的几个小问题。
panic如果没有被捕获,最终会调用exit(2)终止程序运行 (也就是程序崩溃)recover最终会调用recovery方法恢复程序的继续执行gorecover会进行参数校验,只有在defer语句中调用recover, 才能通过参数校验 (详情见gorecover函数代码注释)- 同上
