Kubernetes Deployment 滚动更新实现原理
2023-12-28 Cloud Native Kubernetes 读代码
概述
一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力。
生产环境中,通常将无状态应用定义为 Deployment 以便于完成对应的滚动更新、水平扩容、自动回滚等典型业务场景。
Deployment 本质上是对 ReplicaSet 的升级,那么为什么不直接使用 ReplicaSet 呢?因为 ReplicaSet 的功能设计比较底层 (或者也可以说比较基础), ReplicaSet 只是为了维护保证一组 Pod 处于运行状态 (只能指定 Pod 的期望副本数量),无法完成水平扩容等高级特性。
示例
# 官方示例 controllers/nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3 # 副本数量,可以根据实际情况修改
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
在 Kubernetes 中执行上面的代码后,不仅会创建 1 个 Deployment 对象,还会创建 1 个对应的 ReplicaSet 对象和 3 个 Pod 对象。
源码说明
本文着重从源代码的角度分析一下 Deployment 的实现原理,Deployment 功能对应的源代码位于 Kubernetes 项目的 pkg/controller/deployment/ 目录,本文以 Kubernetes v1.28 版本源代码进行分析。
流程图
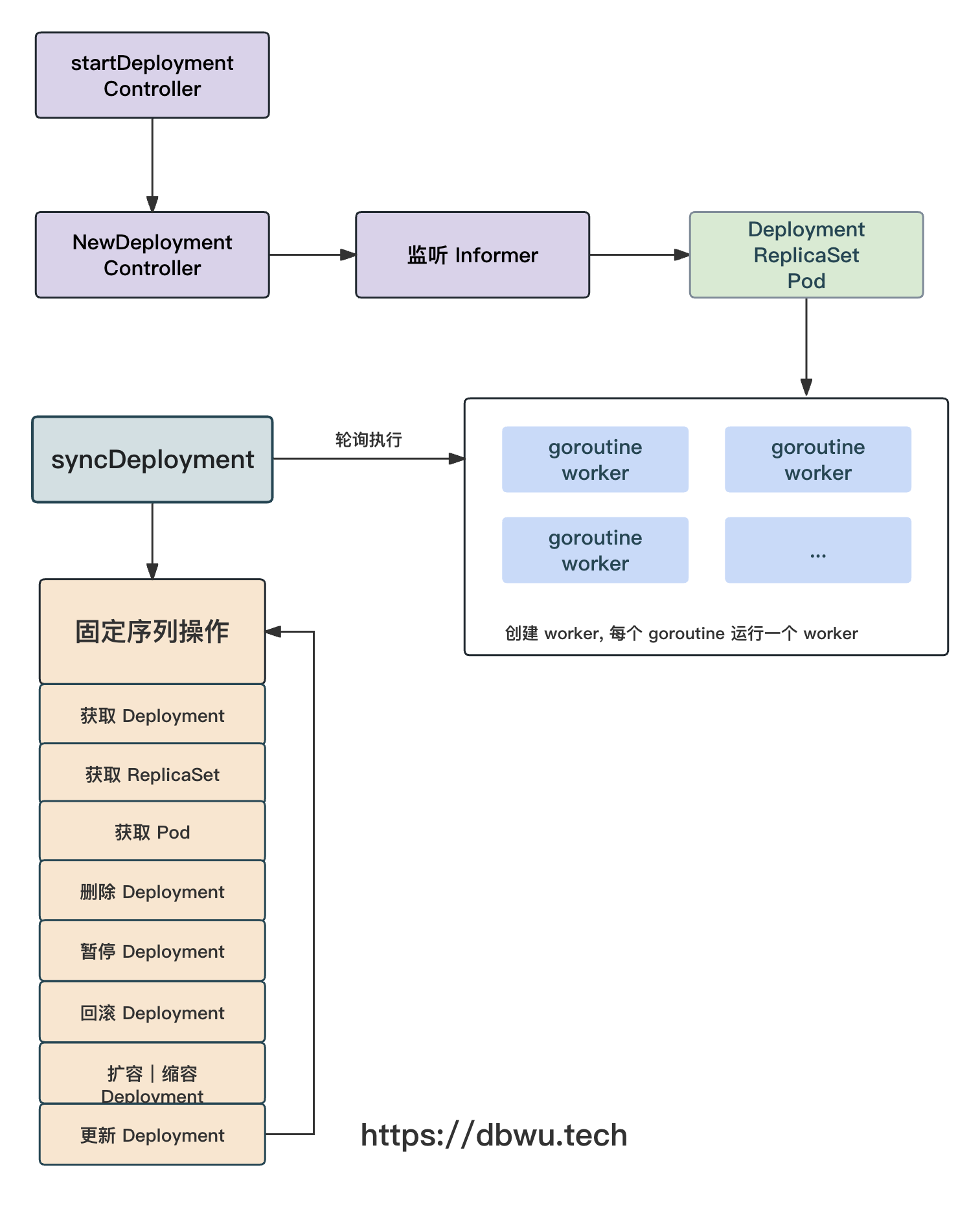
下面我们跟着流程图一起看下源代码的具体实现。
DeploymentController
首先来看看 DeploymentController 控制器对象,该对象是实现 Deployment 功能的核心对象。
// DeploymentController 负责将 Deployment 对象对应的 Pod 调整到定义的期望状态
type DeploymentController struct {
...
// 回调方法
// 同时方便在单元测试中注入 Mock
syncHandler func(ctx context.Context, dKey string) error
// Deployment 列表
dLister appslisters.DeploymentLister
// ReplicaSet 列表
rsLister appslisters.ReplicaSetLister
// Pod 列表
podLister corelisters.PodLister
// 队列中存储发生了变化 (需要同步) 的 Deployment
queue workqueue.RateLimitingInterface
}
初始化
NewDeploymentController 方法用于 DeploymentController 控制器对象的初始化工作,并返回一个实例化对象。
func `NewDeploymentController`(ctx context.Context, ...) (*DeploymentController, ...) {
...
dc := &DeploymentController{
...
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "deployment"),
}
...
// 增加 Deployment informer 监听回调方法
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
...
})
// 增加 ReplicaSet informer 监听回调方法
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
...
})
// 增加 Pod informer 监听回调方法
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
...
})
// 注册回调方法
// 默认为 DeploymentController 对象的 syncDeployment 方法
// 在单元测试中,也可以通过参数的注入,完成 Mock
dc.syncHandler = dc.syncDeployment
...
return dc, nil
}
启动控制器
根据控制器的初始化方法 NewDeploymentController 的调用链路,可以找到控制器开始启动和执行的地方。
// cmd/kube-controller-manager/app/apps.go
func startDeploymentController(ctx context.Context, ...) (...) {
dc, err := deployment.NewDeploymentController(
...
)
// 启动一个单独的 goroutine 来完成 {初始化 && 运行}
go dc.Run(ctx, int(controllerContext.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs))
return nil, true, nil
}
根据源文件代码可以看到,StatefulSetController、 ReplicaSetController 等控制器的启动方法也在该文件中。
具体逻辑方法
DeploymentController.Run 方法执行具体的初始化逻辑。
func (dc *DeploymentController) Run(ctx context.Context, workers int) {
...
// (根据参数配置) 启动多个 goroutine 处理逻辑 (默认为 5 个)
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, dc.worker, time.Second)
}
<-ctx.Done()
}
DeploymentController.worker 方法本质上就是一个无限循环轮询器,不断从队列中取出 Deployment 对象,然后进行对应的操作。
func (dc *DeploymentController) worker(ctx context.Context) {
// 内部调用 processNextWorkItem 方法
for dc.processNextWorkItem(ctx) {
}
}
func (dc *DeploymentController) processNextWorkItem(ctx context.Context) bool {
// 从队列获取 Deployment
// 获取到的对象可以编码为一个字符串 key
key, quit := dc.queue.Get()
// 调用回调方法,默认也就是 syncDeployment 方法
err := dc.syncHandler(ctx, key.(string))
...
}
Deployment 同步
DeploymentController 的回调处理方法默认就是 DeploymentController.syncDeployment 方法,也就是说,该方法是所有 Deployment 操作的入口方法。
func (dc *DeploymentController) syncDeployment(ctx context.Context, key string) error {
// 通过 key 解析出 Deployment 对象对应的 命名空间和名称
namespace, name, err := cache.SplitMetaNamespaceKey(key)
...
// 获取 Deployment 对象
deployment, err := dc.dLister.Deployments(namespace).Get(name)
// 深度拷贝一个对象
// 在方法内部作为局部变量使用
d := deployment.DeepCopy()
...
// 获取 Deployment 对应的 ReplicaSet 列表
rsList, err := dc.getReplicaSetsForDeployment(ctx, d)
// 获取 Deployment 对应的 Pod 列表
// 返回结果会根据 ReplicaSet 进行分组
podMap, err := dc.getPodMapForDeployment(d, rsList)
// Deployment 需要删除
if d.DeletionTimestamp != nil {
// 执行删除操作,然后直接返回
return dc.syncStatusOnly(ctx, d, rsList)
}
// 检测 Deployment 是否处于暂停 (Pause) 状态
if err = dc.checkPausedConditions(ctx, d); err != nil {
return err
}
// 如果 Deployment 处于暂停状态
// 同步状态后直接返回
if d.Spec.Paused {
return dc.sync(ctx, d, rsList)
}
// 当前是回滚操作
// 如果 Deployment 对应的底层 ReplicaSet 使用新的版本更新,那么回滚操作不能重复执行
// 所以应该确保 Deployment 先清理了历史版本,然后再执行回滚 ues.
if getRollbackTo(d) != nil {
return dc.rollback(ctx, d, rsList)
}
// 检测 Deployment 是否需要扩容
scalingEvent, err := dc.isScalingEvent(ctx, d, rsList)
// 同步状态后直接返回
if scalingEvent {
return dc.sync(ctx, d, rsList)
}
// Deployment 有两种更新策略
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
// 1. 全量更新 (先 kill 所有已存在的 Pod, 然后启动新的 Pod)
// 这个一般应用场景很少,所以本文直接跳过,不做源代码分析了
return dc.rolloutRecreate(ctx, d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
// 2. 滚动更新
return dc.rolloutRolling(ctx, d, rsList)
}
...
}
通过 DeploymentController.syncDeployment 方法的源代码,我们可以看到: Deployment 每次同步时都会执行如下的操作:
- 根据参数 key 获取指定的 Deployment
- 获取 Deployment 对应的 ReplicaSet 列表和 Pod 列表
- 检测并在必要时删除 Deployment
- 检测并在必要时暂停 Deployment
- 检测并在必要时回滚 Deployment
- 检测并在必要时扩容|缩容 Deployment
- 检测并在必要时更新 Deployment (滚动更新|全量更新)
需要注意的是,每次同步时只会有一种操作进行,例如如果执行了扩容操作,那么就不会执行更新操作了,其他类型的操作以此类推。
有了上面的这个大致的逻辑框架,接下来我们逐个分析对应的单个方法实现即可,限于篇幅,本文主要分析 Deployment 扩容|缩容、滚动更新、删除这三个操作的具体实现。
Deployment 扩容|缩容
Deployment 的扩容|缩容操作总共分为 3 步,下面逐个步骤来看看。
1. 检测是否为 扩容|缩容 操作
检测 扩容|缩容 操作主要由 DeploymentController.DeploymentController 方法完成。
func (dc *DeploymentController) isScalingEvent(ctx context.Context, ...) (bool, error) {
// 获取所有新的 ReplicaSet 列表和旧的 ReplicaSet 列表
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(ctx, d, rsList, false)
// 所有 ReplicaSet 集合
allRSs := append(oldRSs, newRS)
// 遍历所有拥有 Pod 的 ReplicaSet 列表 (rs.Spec.Replicas > 0)
for _, rs := range controller.FilterActiveReplicaSets(allRSs) {
// 计算期望的 Pod 副本数量
desired, ok := deploymentutil.GetDesiredReplicasAnnotation(logger, rs)
// 如果期望 Pod 副本数量和定义的副本数量不同,就需要扩容操作
if desired != *(d.Spec.Replicas) {
return true, nil
}
}
return false, nil
}
2. 同步 扩容|缩容 操作
func (dc *DeploymentController) sync(ctx context.Context, ...) error {
// 获取所有新的 ReplicaSet 列表和旧的 ReplicaSet 列表
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(ctx, d, rsList, false)
// 执行 扩容|缩容 操作
if err := dc.scale(ctx, d, newRS, oldRSs); err != nil {
return err
}
...
// 所有 ReplicaSet 集合
allRSs := append(oldRSs, newRS)
// 更新 ReplicaSet 状态
return dc.syncDeploymentStatus(ctx, allRSs, newRS, d)
}
3. 具体执行 扩容|缩容 操作
为了降低扩容|缩容过程中可能引发的节点性能故障风险,Kubernetes 不会直接 扩容|缩容 到目标的副本数量,因为这样可能引发 “不可用副本数量急剧增加” 现象, 所以会逐步按照比例进行,类似滚动升级的设计理念。
func (dc *DeploymentController) scale(ctx context.Context, deployment *apps.Deployment, newRS *apps.ReplicaSet, oldRSs []*apps.ReplicaSet) error {
...
// 如果 Deployment 配置的升级模式为滚动升级
// 按照比例伸缩所有 ReplicaSet (包括新的和旧的)
if deploymentutil.IsRollingUpdate(deployment) {
allRSs := controller.FilterActiveReplicaSets(append(oldRSs, newRS))
allRSsReplicas := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
// 初始化 Pod 最大副本数量
allowedSize := int32(0)
if *(deployment.Spec.Replicas) > 0 {
// Pod 最大副本数量 = Deployment 预期副本数量 + 滚动升级模式 Pod 最大数量
// (也就是说可以创建的超出期望的 Pod 数量)
allowedSize = *(deployment.Spec.Replicas) + deploymentutil.MaxSurge(*deployment)
}
// 需要增加伸缩的 Pod 数量
deploymentReplicasToAdd := allowedSize - allRSsReplicas
var scalingOperation string
switch {
case deploymentReplicasToAdd > 0:
// 如果 Pod 数量大于 0,需要扩容
// 对 ReplicaSet 进行排序,让新的 ReplicaSet 靠前,扩容时以新的 ReplicaSet 为基准扩容 Pod
sort.Sort(controller.ReplicaSetsBySizeNewer(allRSs))
scalingOperation = "up"
case deploymentReplicasToAdd < 0:
// 如果 Pod 数量小于 0,需要缩容
// 对 ReplicaSet 进行排序,让旧的 ReplicaSet 靠前,缩容时先删除旧的 Pod
sort.Sort(controller.ReplicaSetsBySizeOlder(allRSs))
scalingOperation = "down"
}
// deploymentReplicasAdded 表示已经累计 Pod 数量
// 该值不能超过 deploymentReplicasToAdd
deploymentReplicasAdded := int32(0)
nameToSize := make(map[string]int32)
// 遍历所有 ReplicaSet
for i := range allRSs {
rs := allRSs[i]
if deploymentReplicasToAdd != 0 {
// 如果 ReplicaSet 需要扩容
// 粗略估算出 ReplicaSet 需要的目标副本数量
proportion := deploymentutil.GetProportion(logger, rs, *deployment, deploymentReplicasToAdd, deploymentReplicasAdded)
// 更新 ReplicaSet 的目标副本数量
nameToSize[rs.Name] = *(rs.Spec.Replicas) + proportion
// 更新已经累计的 Pod 数量
deploymentReplicasAdded += proportion
} else {
// 如果 ReplicaSet 不需要扩容
// 那么 ReplicaSet 的目标副本数量就是其定义的期望副本数量
nameToSize[rs.Name] = *(rs.Spec.Replicas)
}
}
// 遍历所有 ReplicaSet
for i := range allRSs {
rs := allRSs[i]
// 如果需要增加伸缩的 Pod 数量依然不等于 0
// 也就意味着仍然有 ReplicaSet 需要伸缩
// 此时直接将剩余的伸缩数量给到列表中的第一个 (最新的,因为上面排序过了) ReplicaSet 即可
if i == 0 && deploymentReplicasToAdd != 0 {
leftover := deploymentReplicasToAdd - deploymentReplicasAdded
nameToSize[rs.Name] = nameToSize[rs.Name] + leftover
// 缩容最小至 0
if nameToSize[rs.Name] < 0 {
nameToSize[rs.Name] = 0
}
}
// 逐个 ReplicaSet 进行伸缩
if _, _, err := dc.scaleReplicaSet(ctx, rs, nameToSize[rs.Name], deployment, scalingOperation); err != nil {
return err
}
}
}
return nil
}
Deployment 滚动更新
Deployment 的滚动更新操作由 DeploymentController.rolloutRolling 方法完成,内部通过不断对新的 ReplicaSet 进行扩容,
同时对旧的 ReplicaSet 进行缩容,此消彼长间,直到达到预期的状态。
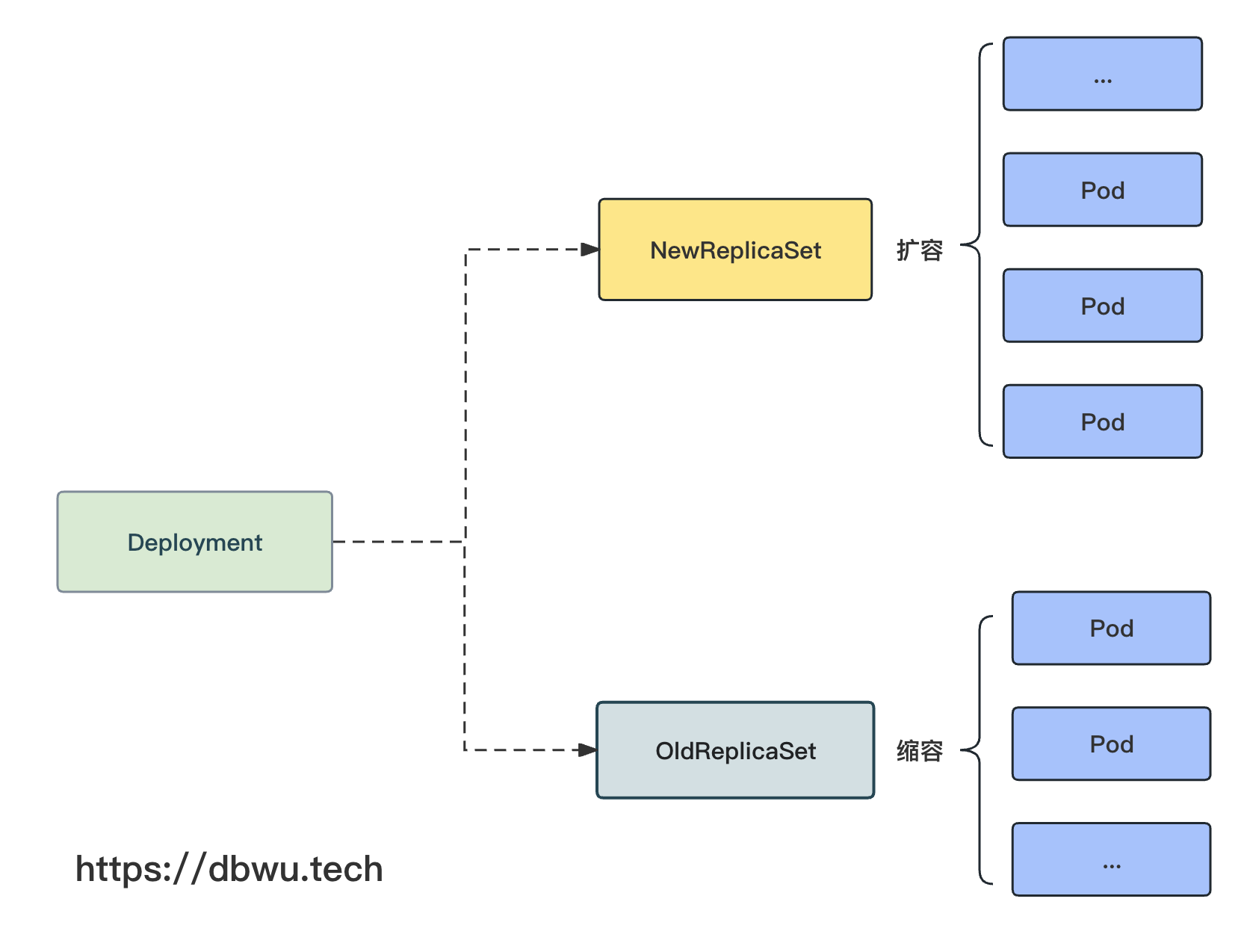
func (dc *DeploymentController) rolloutRolling(ctx context.Context, ...) error {
// 获取所有新的 ReplicaSet 列表和旧的 ReplicaSet 列表
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(ctx, d, rsList, true)
// 所有 ReplicaSet 集合
allRSs := append(oldRSs, newRS)
// 扩容
scaledUp, err := dc.reconcileNewReplicaSet(ctx, allRSs, newRS, d)
if scaledUp {
// 扩容完成
// 同步状态后直接返回
return dc.syncRolloutStatus(ctx, allRSs, newRS, d)
}
// 如果无法扩容了,说明此时 Pod 的副本数量 >= 目标数量
// 那么就应该执行缩容操作了
scaledDown, err := dc.reconcileOldReplicaSets(ctx, allRSs, controller.FilterActiveReplicaSets(oldRSs), newRS, d)
if scaledDown {
// 缩容完成
// 同步状态后直接返回
return dc.syncRolloutStatus(ctx, allRSs, newRS, d)
}
// 清理历史 ReplicaSet 对象
if deploymentutil.DeploymentComplete(d, &d.Status) {
if err := dc.cleanupDeployment(ctx, oldRSs, d); err != nil {
return err
}
}
// 滚动升级完毕
// 同步最终状态
return dc.syncRolloutStatus(ctx, allRSs, newRS, d)
}
DeploymentController.reconcileNewReplicaSet 方法用于执行新的 ReplicaSet 的扩容操作。
func (dc *DeploymentController) reconcileNewReplicaSet(ctx context.Context, ...) (bool, error) {
// 如果 ReplicaSet 的副本数量已经达到期望数量
// 就不需要扩容了,直接返回即可
if *(newRS.Spec.Replicas) == *(deployment.Spec.Replicas) {
return false, nil
}
// 如果 ReplicaSet 的副本数量大于期望数量
// 就需要进行缩容操作了
if *(newRS.Spec.Replicas) > *(deployment.Spec.Replicas) {
scaled, _, err := dc.scaleReplicaSetAndRecordEvent(ctx, newRS, *(deployment.Spec.Replicas), deployment)
return scaled, err
}
// 到这里执行的才是扩容操作
// 计算需要扩容的副本数量
newReplicasCount, err := deploymentutil.NewRSNewReplicas(deployment, allRSs, newRS)
// 同步 ReplicaSet 相关字段
// 同步之后,剩下的操作就交给 ReplicaSet 控制器了
scaled, _, err := dc.scaleReplicaSetAndRecordEvent(ctx, newRS, newReplicasCount, deployment)
return scaled, err
}
DeploymentController.reconcileOldReplicaSets 方法用于执行旧的 ReplicaSet 的缩容操作。
func (dc *DeploymentController) reconcileOldReplicaSets(ctx context.Context, ...) (bool, error) {
// 获取旧的 Pod 数量
oldPodsCount := deploymentutil.GetReplicaCountForReplicaSets(oldRSs)
if oldPodsCount == 0 {
// 如果旧的 Pod 数量为 0,说明就不再需要缩容了
// 缩容的最小数量为 0
return false, nil
}
// 如果满足以下两个条件中的任意一个,就可以执行缩容操作
// 1. 旧的 ReplicaSet 中存在不健康的副本,可以直接缩容 (删除) 掉,同时不会增加不可用性
// 2. 新的 ReplicaSet 比例已经扩大,此时就可以进一步缩容旧的 ReplicaSet 了
// 最大缩容 Pod 副本数量 = 所有 Pod 数量 - 最大不可用数量 - 新启动的 Pod 不可用数量
// 不仅仅要考虑 最大不可用数量 和 已经创建的 Pod 数量,还要考虑新启动的 Pod 不可用数量
// 这样新启动的 Pod 不可用数量,就会被计算在内,从而不会导致在下一轮缩容操作中
// 继续缩减旧的 ReplicaSet 副本,引发不可用性的增高
// 举个例子来说明缩容场景
// * 当前有 10 个副本
// * 滚动升级配置中最大不可用数量为 2 个
// * 新启动的副本为 3 个
// 对于条件 1 来说:
// Deployment 更新之后,旧的 ReplicaSet 缩容到 8 个 Pod,同时新的 ReplicaSet 扩容到 5 个 Pod
// 假设新的 ReplicaSet 发生故障并且一直不可用
// 此时 Pod 总数量为 13, 最小可用数量为 8, ReplicaSet 的不可用 Pod 数量为 5
// 节点故障导致其中一个 ReplicaSet 不可用,但是,13 - 8 - 5 = 0, 所以旧的 ReplicaSet 不能缩容
// 操作人员 (开发或者运维) 发现故障情况,并且执行回滚操作
// 新的 ReplicaSet 最大不可用数量为 1, 因此最大可缩容数量 = 13 - 8 - 1 = 4,
// 最后 Pod 的总数量为 9, 随着时间变化,新的 ReplicaSet 最终会将 Pod 数量扩容到 10
// 对于条件 2 来说:
// 还是以刚才的场景接着说
// ...
// 操作人员 (开发或者运维) 发现故障情况,但是不执行回滚操作,而是直接更新 Pod 模板
// 这是新的 ReplicaSet 必须从 0 开始创建新的 Pod 了,因为此时已经有 13 个 Pod 了
// 但是,新的 ReplicaSet 副本不可用数量同样也是 0, 因此 2 个旧的 ReplicaSet 的副本数量将会缩容 5 个,从 13 个缩减到 8 个
// 这样新的 新的 ReplicaSet 副本就可以直接扩容到 5 个
// 获取所有 Pod 数量
allPodsCount := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
// 获取 Pod 的最多不可用数量
maxUnavailable := deploymentutil.MaxUnavailable(*deployment)
// 计算副本最小可用量
minAvailable := *(deployment.Spec.Replicas) - maxUnavailable
// 计算新的 ReplicaSet 副本不可用数量
newRSUnavailablePodCount := *(newRS.Spec.Replicas) - newRS.Status.AvailableReplicas
// 计算副本最大缩容数量
maxScaledDown := allPodsCount - minAvailable - newRSUnavailablePodCount
// 如果最大缩容数量小于等于 0,说明此时不需要缩容
// 直接退出即可
if maxScaledDown <= 0 {
return false, nil
}
// 清理不可用的 ReplicaSet
oldRSs, cleanupCount, err := dc.cleanupUnhealthyReplicas(ctx, ...)
// 缩容旧的 ReplicaSet, 需要检测最大不可用数量以确保可以正常缩容
allRSs = append(oldRSs, newRS)
scaledDownCount, err := dc.scaleDownOldReplicaSetsForRollingUpdate(ctx, ...)
// 本次已缩容的数量 = 清理的数量 + 缩容的数量
totalScaledDown := cleanupCount + scaledDownCount
return totalScaledDown > 0, nil
}
Deployment 删除
DeploymentController.syncStatusOnly 方法用于更新 Deployment 的状态,最终真正的删除操作是由 GarbageCollector GC 控制器来完成的。
func (dc *DeploymentController) syncStatusOnly(ctx context.Context, ...) error {
// 获取所有新的 ReplicaSet 列表和旧的 ReplicaSet 列表
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(ctx, d, rsList, false)
allRSs := append(oldRSs, newRS)
// 内部调用 syncDeploymentStatus 方法
return dc.syncDeploymentStatus(ctx, allRSs, newRS, d)
}
DeploymentController.syncDeploymentStatus 方法用于检测 Deployment 的状态是否为最新的,并在必要时进行同步。
func (dc *DeploymentController) syncDeploymentStatus(ctx context.Context, ...) error {
newStatus := calculateStatus(allRSs, newRS, d)
newDeployment := d
newDeployment.Status = newStatus
_, err := dc.client.AppsV1().Deployments(newDeployment.Namespace).UpdateStatus(ctx, newDeployment, metav1.UpdateOptions{})
return err
}
–
小结
