Kubernetes Pod 设计与实现 - 创建流程
2023-11-23 Cloud Native Kubernetes 读代码
概述
Pod 是 Kubernetes 中应用运行的最小单位 (同时也是顶级资源),也称为容器组,单个 Pod 可以看作是一个逻辑独立的主机,拥有自己的 IP、主机名称、进程等。
Pod 的使用方法和最佳实践在 这篇文章 中已经介绍过了,这里不再赘述,本文着重从源代码的角度分析一下 Pod 创建流程的实现原理。
示例
# 官方示例 pods/simple-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
基于 YAML 文件创建 Pod:
$ kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml
在 Kubernetes 中执行上面的代码后,会创建一个包含容器 nginx 的 Pod, 当然在实际应用中不会直接创建 Pod, 而是会使用 Deployment、Job 等工作负载资源来创建 Pod。
宏观流程
在 Kubernetes 中执行上 Pod yaml 文件时,kubectl 发送请求清单到 API Server, AP Server 将清单中的资源对象存储到 etcd, 然后进入调度流程, 调度器分配资源对象运行的具体工作节点,节点上面的 Kubelet 通过监听 API Server (Informer) 资源变更,发现有新的 Pod 分配到本节点后 (Pod 的 nodeName 属性), 获取并检查 Pod 定义,然后命令 CRI (容器运行时) 来启动 Pod 容器。
源码说明
本文着重从源代码的角度分析一下 Pod 的实现原理,Pod 功能对应的源代码位于 Kubernetes 项目的 pkg/controller/kubelet/ 目录,本文以 Kubernetes v1.28 版本源代码进行分析。
因为 Pod 主要是由 kubelet 管理和操作 (创建、删除、重启等) 的,所以相关的代码基本集中在 kubelet 目录。
流程图
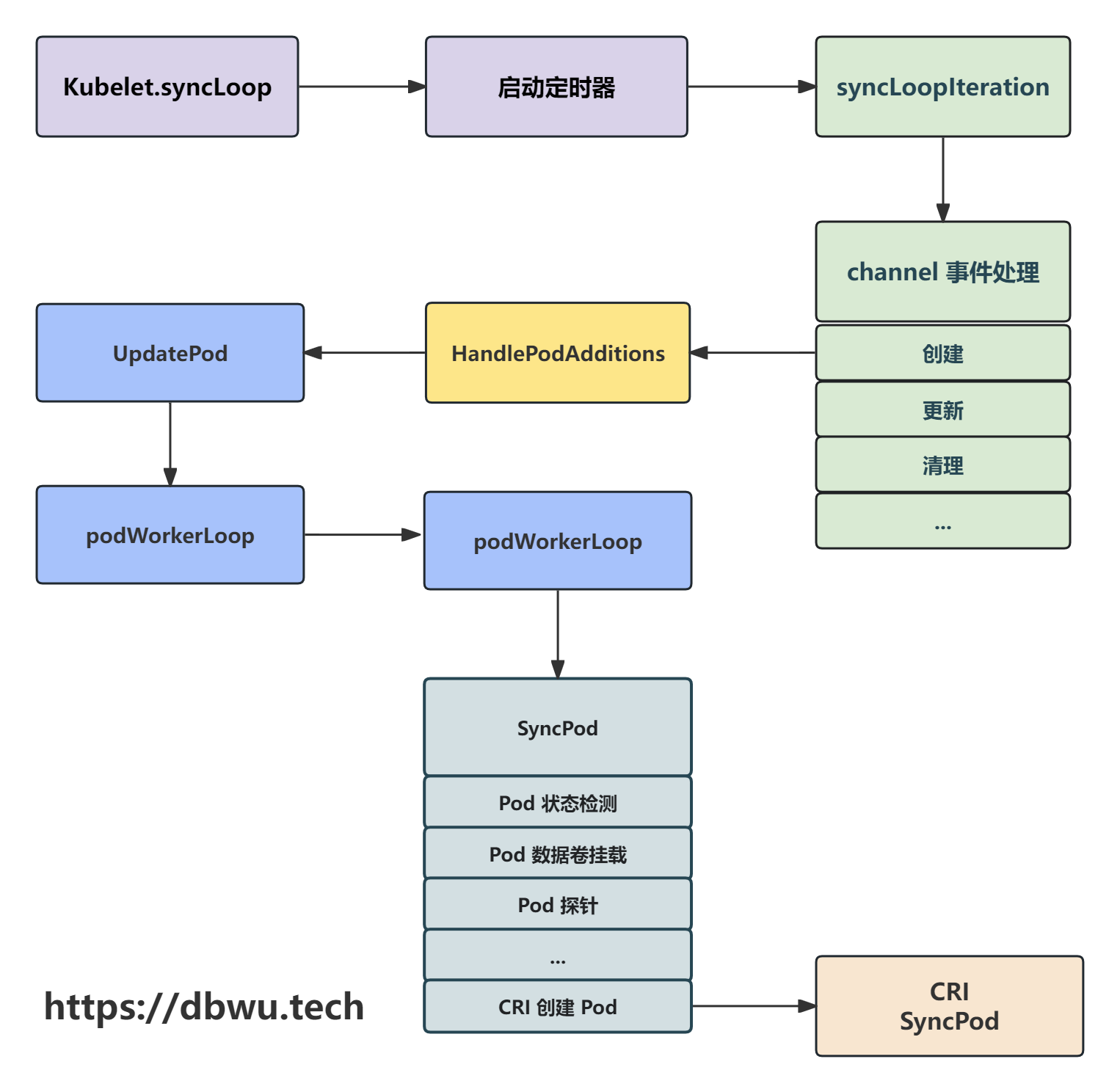
下面我们跟着流程图一起看下源代码的具体实现。
主循环入口
我们先跳过 kubelet 的初始化内容,因为这部分的代码很多,为了节省时间和篇幅,本文的源代码直接从 kubectl 的调度入口开始,后面有空了再单独写一篇关于 kubelet 的文章。
Kubelet.syncLoop 方法是 kubelet 的核心调度方法 (主循环流程),内部通过订阅多个 channel 相关事件的变化,
对比资源的运行状态和期望状态来执行对应的操作,内部的主流程会无限循环,永不退出。
func (kl *Kubelet) syncLoop(ctx context.Context, updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
// Pod 同步定时器: 每秒一次
syncTicker := time.NewTicker(time.Second)
defer syncTicker.Stop()
// Pod 异常清理定时器: 每 2 秒一次
housekeepingTicker := time.NewTicker(housekeepingPeriod)
defer housekeepingTicker.Stop()
...
for {
...
// 记录同步开始时间
kl.syncLoopMonitor.Store(kl.clock.Now())
// 调用 syncLoopIteration 方法执行具体的同步操作
if !kl.syncLoopIteration(ctx, updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
// 记录同步结束时间
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}
执行同步操作
Kubelet.syncLoopIteration 方法用于主循环中单次的同步操作,通过订阅不同的 channel 并且将发生变化的 Pods 分发到对应的回调方法进行处理。
订阅 channel 列表:
| channel 名称 | 相关事件 |
|---|---|
| configCh | 发生变更的 Pod |
| plegCh | 更新运行时缓存, 同步 Pod |
| syncCh | 定时同步 Pod |
| housekeepingCh | 清理 Pod |
| health manager | 探针检测失败的 Pod |
方法内部的工作流:
- 从 channel 读取事件
- 调用事件对应的回调方法
- 更新主循环最后同步时间
从源代码中可以看到,内部使用了 switch 预计从多个 channel 读取数据,这也就意味着: 不同的事件处理并没有固定的先后顺序。
func (kl *Kubelet) syncLoopIteration(ctx context.Context, <-chan ...) bool {
// 处理不同事件
// 哪个事件来了算哪个 :-)
select {
case u, open := <-configCh:
// 来自 {文件系统, ApiServer, HTTP} 的 Pod 变更事件
// 再次检测具体的事件类型 (创建、删除、更新等)
switch u.Op {
case kubetypes.ADD:
// 创建 Pods
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
// 更新 Pods
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
// 直接删除 Pods
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
// 协调 Pods
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
// 优雅删除 Pods
// 不同于上面的直接删除操作
// 注意: 这里的删除使用的是先更新、后删除操作,实现优雅删除
handler.HandlePodUpdates(u.Pods)
}
kl.sourcesReady.AddSource(u.Source)
case e := <-plegCh:
// 更新运行时缓存
if isSyncPodWorthy(e) {
if pod, ok := kl.podManager.GetPodByUID(e.ID); ok {
// 同步 Pod 的运行时状态
handler.HandlePodSyncs([]*v1.Pod{pod})
}
}
if e.Type == pleg.ContainerDied {
// 如果是需要更新 Pod 内部的容器运行时
// 直接删除当前运行的容器
if containerID, ok := e.Data.(string); ok {
kl.cleanUpContainersInPod(e.ID, containerID)
}
}
case <-syncCh:
// 定时同步 Pod
podsToSync := kl.getPodsToSync()
handler.HandlePodSyncs(podsToSync)
case update := <-kl.livenessManager.Updates():
// 存活探针检测失败的 Pod
if update.Result == proberesults.Failure {
handleProbeSync(kl, update, handler, "liveness", "unhealthy")
}
case update := <-kl.readinessManager.Updates():
// 就绪探针检测失败的 Pod
ready := update.Result == proberesults.Success
handleProbeSync(kl, update, handler, "readiness", status)
case update := <-kl.startupManager.Updates():
// 启动探针检测失败的 Pod
started := update.Result == proberesults.Success
handleProbeSync(kl, update, handler, "startup", status)
case <-housekeepingCh:
// 清理 Pod
if !kl.sourcesReady.AllReady() {
// 如果资源还未就绪,无需清理
} else {
// 开始清理 Pods
if err := handler.HandlePodCleanups(ctx); err != nil {
klog.ErrorS(err, "Failed cleaning pods")
}
}
}
return true
}
方法内部虽然使用了很多的条件分支语句,但是流程结构非常直观,我们只需要根据具体的回调方法名称追踪调用链路即可。
Pod 创建
本文着重分析一下 Pod 的创建流程,对应的方法为 Kubelet.HandlePodAdditions。
func (kl *Kubelet) HandlePodAdditions(pods []*v1.Pod) {
// 根据 Pod 的创建时间进行排序
// 因为上文中提到,主循环中的事件处理依赖于 channel 的读取,无法保证顺序
sort.Sort(sliceutils.PodsByCreationTime(pods))
// 遍历要创建的 Pod 列表
for _, pod := range pods {
// 直接将 Pod 添加到专门的 Pod 管理器中
// 因为 kubelet 依赖于从 Pod 管理器获取期望状态
// 如果一个 Pod 不存在于 Pod 管理器中
// 也就意味着该 Pod 已经从 ApiServer 中被删除了,不需要执行其他额外操作了
kl.podManager.AddPod(pod)
// 将创建 Pod 的操作分发到 podWorkers.UpdatePod 方法
kl.podWorkers.UpdatePod(UpdatePodOptions{
Pod: pod,
MirrorPod: mirrorPod,
UpdateType: kubetypes.SyncPodCreate,
StartTime: start,
})
}
}
podWorkers.UpdatePod 方法根据参数配置更新或终止对应的 Pod, 当一个 Pod 状态发生以下变化时:
- 从 ApiServer 删除
- 运行时错误 (探针检测失败、内部容器崩溃等)
- 被 kubelet 驱逐
那么此时 Pod 状态不论是可运行、正在终止、已经终止 3 种状态中的那一个,最终都会变为已终止。
| 状态 | 说明 |
|---|---|
| SyncPod | Pod 需要被启动并运行 |
| TerminatingPod | Pod 正在终止中,内部的一些容器还在运行 |
| TerminatedPod | Pod 已经终止,内部的容器全部停止运行,随时可以被清理 |
func (p *podWorkers) UpdatePod(options UpdatePodOptions) {
...
status, ok := p.podSyncStatuses[uid]
if !ok {
// 如果当前 Pod 不存在于 Pod 状态中
// 就先创建对应的 Pod 状态
status = &podSyncStatus{
syncedAt: now,
fullname: kubecontainer.BuildPodFullName(name, ns),
}
...
p.podSyncStatuses[uid] = status
}
...
// Pod 已经完成并终止
// 此时 Pod 状态不能被更新,直到 Pod UID 被清除
if status.IsFinished() {
return
}
// 检测 Pod 状态是否需要转换到终止
...
// 终于走到核心流程了
// 如果 Pod 不存在,就启动一个 goroutine 创建
podUpdates, exists := p.podUpdates[uid]
if !exists {
podUpdates = make(chan struct{}, 1)
p.podUpdates[uid] = podUpdates
...
// 单独的 goroutine 创建 Pod
go func() {
// 调用 podWorkerLoop 方法
p.podWorkerLoop(uid, outCh)
}()
}
...
}
podWorkers.UpdatePod 方法内部调用链路多且比较复杂,为了抓住重点,上述代码中只保留了和下文中调用相关代码。
podWorkers.podWorkerLoop 方法用于管理单个 Pod 的状态顺序更新,方法的运行时位于一个单独的 goroutine 中,内部的逻辑流程如下:
- Pod 启动,保证统一时间没有两个 Pod 使用相同的 UID、名称
- Pod 同步,通过协调 Pod 定义的期望状态与运行状态来完成 Pod 编排
- Pod 终止,保证 Pod 中运行的所有容器终止
- Pod 清理,在 Pod 被删除之前清理所有必要的资源
func (p *podWorkers) podWorkerLoop(podUID types.UID, podUpdates <-chan struct{}) {
// 遍历更新的 Pod channel
for range podUpdates {
// 小技巧: 将复杂的 switch 条件分支语句放入一个匿名函数执行
// 匿名方法是 Pod 同步操作的核心部分
err := func() error {
...
switch {
case update.WorkType == TerminatedPod:
// Pod 正在终止中
case update.WorkType == TerminatingPod:
// Pod 已经终止
default:
// Pod 创建
// 调用 Kubelet.SyncPod 方法创建
isTerminal, err = p.podSyncer.SyncPod(ctx, ...)
}
return err
}()
...
}
}
最后,创建 Pod 的工作委托给 Kubelet.SyncPod 方法执行。
Kubelet.SyncPod 方法用于创建单个 Pod, 内部逻辑流程如下:
- 如果 Pod 正处于创建过程中,记录创建操作执行延迟
- 调用 generateAPIPodStatus 方法预处理 Pod 的状态
- 如果 Pod 是第一次启动,记录 Pod 的启动延迟
- 将 Pod 的状态同步到 statusManager 对象
- 停止 Pod 中状态异常的容器
- 启动 Pod 相关的后台追踪采样任务
- 创建 Pod 对应的数据目录
- 等待卷目录挂载完成
- 拉取 Pod 对应的 Secrets
- 添加 Pod 的探针检测
- 调用容器运行时 (CRI) 真正创建 Pod
func (kl *Kubelet) SyncPod(ctx context.Context, ...) (isTerminal bool, err error) {
...
// 将 Pod 的状态同步到 statusManager 对象
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// 如果 Pod 没有达到运行条件
// 直接返回错误
// Pods that are not runnable must be stopped - return a typed error to the pod worker
if !runnable.Admit {
...
return false, syncErr
}
// 如果 CNI 插件未就绪
// 那么只有 Pod 的网络模式为 Host 时,才可以创建 (Pod 使用宿主机的 Network Namespace)
// 其他情况直接返回错误
if err := kl.runtimeState.networkErrors(); err != nil && !kubecontainer.IsHostNetworkPod(pod) {
return false, fmt.Errorf("%s: %v", NetworkNotReadyErrorMsg, err)
}
// 如果 kubelet 启动时开启了 cgroups-per-qos
// 如果 Pod 还未创建过对应的 Cgroups 资源控制
// 创建对应的 Cgroups 资源控制
// 对于已经创建过 Cgroups 资源控制,但是已经终止的 Pod
// 直接复用之前的 Cgroups 资源控制即可
pcm := kl.containerManager.NewPodContainerManager()
if !kl.podWorkers.IsPodTerminationRequested(pod.UID) {
...
}
...
// 创建 Pod 对应的数据目录
if err := kl.makePodDataDirs(pod); err != nil {
...
}
// 等待卷目录挂载完成
if err := kl.volumeManager.WaitForAttachAndMount(ctx, pod); err != nil {
...
}
// 拉取 Pod 对应的 Secrets
pullSecrets := kl.getPullSecretsForPod(pod)
// 添加 Pod 的探针检测
// 探针实现细节请参考之前的文章: https://dbwu.tech/posts/k8s/source_code/prober/
kl.probeManager.AddPod(pod)
// 调用 CRI 创建 Pod
// CRI 设计可以参考之前的文章: https://dbwu.tech/posts/k8s/source_code/cri/
result := kl.containerRuntime.SyncPod(todoCtx, pod, podStatus, pullSecrets, kl.backOff)
...
return false, nil
}
当代码执行到 调用 CRI (容器运行时) 创建 Pod 时,就和 之前的这篇文章 连接起来了,
后续源代码本文不再分析,感兴趣的读者可以看看 Pod 设计与实现 一文中的 Kubernetes Pod 启动流程 小节。
小节
附录