Kubernetes 探针设计与实现
2023-11-20 Cloud Native Kubernetes 读代码
概述
Kubernetes 存在 3 种类型的探针: 启动探针、存储探针、就绪探针。
探针的使用方法和最佳实践在 这篇文章 中已经介绍过了,这里不再赘述,本文着重从源代码的角度分析一下探针的实现原理。
探针功能对应的源代码位于 Kubernetes 项目的 pkg/kubelet/prober 目录,本文以 Kubernetes v1.28 版本源代码进行分析。
重要参数
在 Kubernetes 探针最佳实践 一文中总结了几个探针相关的重要参数,这几个参数对探针的内部执行逻辑有很重要的影响。
initialDelaySeconds
表示容器启动后,等待多少时间之后再启动各类探针
periodSeconds
表示探针执行检测的间隔时间
timeoutSeconds
表示探针执行检测的超时后的等待时间
successThreshold
表示探针执行检测失败之后,如果容器状态想再次被标记为健康,至少需要经过多少次连续成功检测
failureThreshold
表示探针执行检测时,连续失败多少次,容器状态就会被确认不健康
流程图
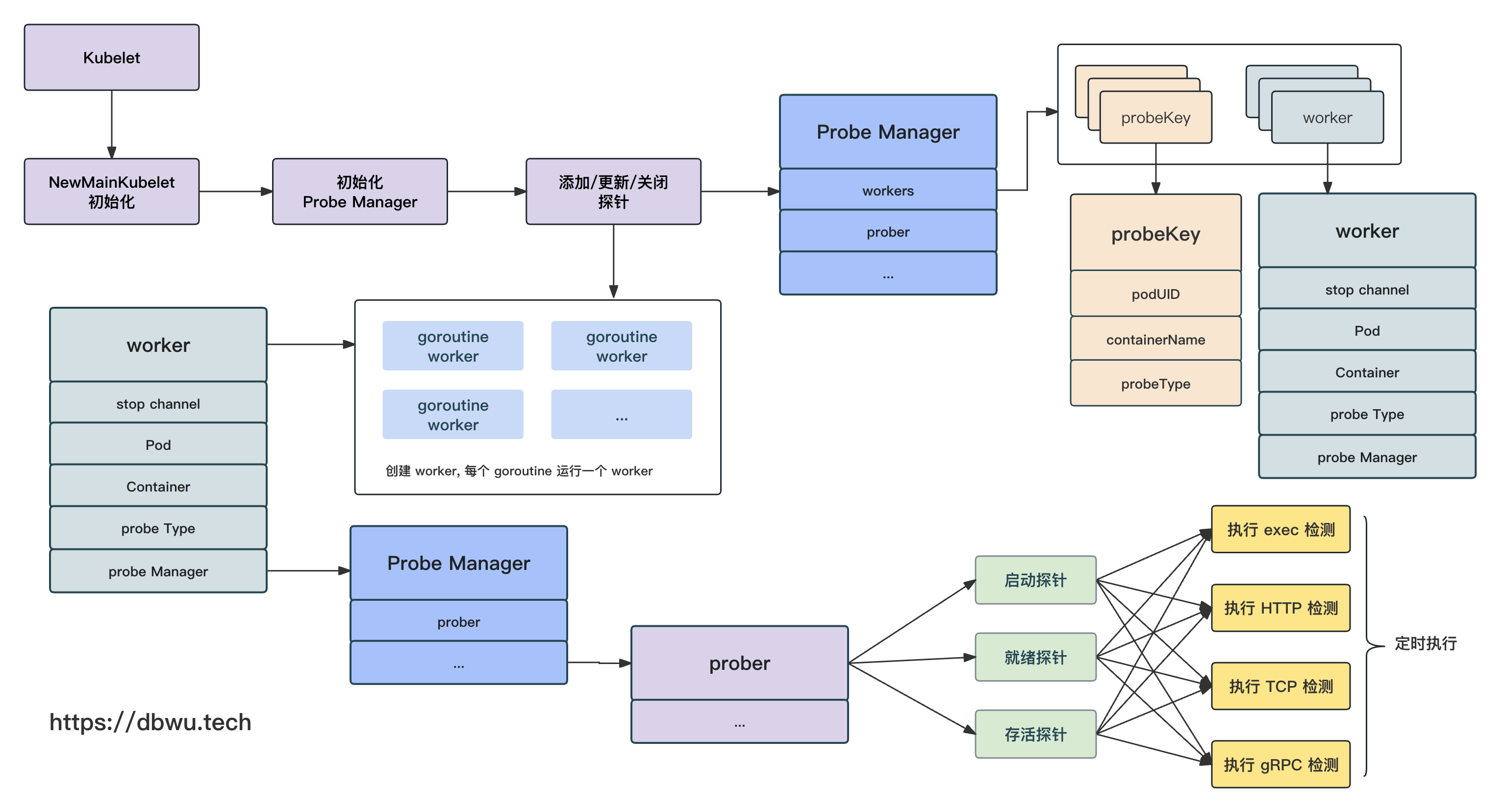
下面我们跟着流程图一起看下源代码的具体实现。
探针对象
prober 表示探针对象,其内嵌了 4 个具体的探针检测实现对象,分别是 exec (shell) 命令行,HTTP 请求,TCP 连接,gRPC 请求,
这 4 种检测方式的具体实现源代码位于 pkg/probe 目录,限于篇幅,本文不做介绍,感兴趣的读者可以自行研究。
type prober struct {
exec execprobe.Prober
http httpprobe.Prober
tcp tcpprobe.Prober
grpc grpcprobe.Prober
...
}
newProber 方法创建并返回一个新的 prober 探针对象。
func newProber(...) *prober {
// HTTP 请求检测方式禁用重定向
const followNonLocalRedirects = false
return &prober{
exec: execprobe.New(),
http: httpprobe.New(followNonLocalRedirects),
tcp: tcpprobe.New(),
grpc: grpcprobe.New(),
}
}
管理器接口
管理器定义为一个接口,用于管理 Pod 和探针。
type Manager interface {
// 为 Pod 新增探针
// Pod 内不同的容器可以使用不同的探针
AddPod(pod *v1.Pod)
// 终止 Pod 之前,先关闭存活探针和启动探针
StopLivenessAndStartup(pod *v1.Pod)
// 终止 Pod 时,停止 Pod 关联的所有的探针以及探针的检测结果
RemovePod(pod *v1.Pod)
// 停止给定参数的 Pod 关联的所有探针
CleanupPods(desiredPods map[types.UID]sets.Empty)
// 更新 Pod 的状态
UpdatePodStatus(*v1.Pod, *v1.PodStatus)
}
探针管理器对象
管理器对象 manager 是探针管理器接口的具体实现。
type manager struct {
// { 探针 <-> worker } 映射关系 Map
workers map[probeKey]*worker
// worker map 读写锁
workerLock sync.RWMutex
// 状态管理器
// 缓存了探针对应关联的 Pod IP 和 容器 ID
statusManager status.Manager
// 就绪探针的检测结果
readinessManager results.Manager
// 存活探针的检测结果
livenessManager results.Manager
// 启动探针的检测结果
startupManager results.Manager
// 具体的探针
prober *prober
// 启动时间
start time.Time
}
// 探针哈希对象
// 通过 {PodID + 容器名称 + 探针类型} 三元组,可以确定一个唯一探针
type probeKey struct {
podUID types.UID
containerName string
probeType probeType
}
NewManager 方法根据指定参数创建一个新的 manager 管理器对象并返回。
func NewManager(...) Manager {
prober := newProber(...)
return &manager{
prober: prober,
...
}
}
管理器初始化
因为探针的检测目标是容器,所以最终探针的执行主体是 kubelet, 在创建 kubelet 实例时,会顺带初始化一个 manager 管理器对象。
func NewMainKubelet(...) (*Kubelet, error) {
...
klet := &Kubelet{
...
}
// 初始化管理器对象
if kubeDeps.ProbeManager != nil {
klet.probeManager = kubeDeps.ProbeManager
} else {
klet.probeManager = prober.NewManager(
...
)
}
...
return klet, nil
}
探针管理
接下来,我们看一下管理器接口中几个探针相关方法的具体实现,几个方法需要对应到 Pod 生命周期的不同阶段,为了节省篇幅抓住文本重点, 和 Pod 相关的源代码本文不做展示和分析,只列出具体的方法即可。
为 Pod 新增探针
当 Pod 创建完成后,会调用执行主体的 kubelet.SyncPod 方法同步 Pod 的状态并将 Pod 收敛到期望的状态,
方法内部会调用探针管理器 manager 对象为 Pod 中的所有容器增加对应的探针。
func (kl *Kubelet) SyncPod(ctx context.Context, ...) (...) {
...
// 这里的 probeManager 对象
// 就是 kubelet 对象初始化时赋值的管理器对象
kl.probeManager.AddPod(pod)
...
}
func (m *manager) AddPod(pod *v1.Pod) {
...
// 初始化探针哈希对象
// 后续不同的探针都以该对象为基础生成 key
key := probeKey{podUID: pod.UID}
// 遍历 Pod 中的容器
for _, c := range append(pod.Spec.Containers, getRestartableInitContainers(pod)...) {
// 更新为当前容器名称
key.containerName = c.Name
// 创建启动探针
if c.StartupProbe != nil {
// 更新探针类型
key.probeType = startup
// 创建一个启动探针 worker 示例
w := newWorker(m, startup, pod, c)
// 更新管理器的 map
m.workers[key] = w
// 启动单独的 goroutine
go w.run()
}
// 创建就绪探针
// 流程和上面的启动探针类似
if c.ReadinessProbe != nil {
...
}
// 创建存活探针
// 流程和上面的启动探针类似
if c.LivenessProbe != nil {
...
}
}
}
关闭探针
终止 Pod 之前,先关闭存活探针和启动探针,通过源代码可以看到内部实现很简单,只需要将存活探针和启动探针对应的两个 worker 停止即可。
func (kl *Kubelet) SyncTerminatingPod(_ context.Context, ...) error {
...
// 首先关闭存活探针和启动探针
kl.probeManager.StopLivenessAndStartup(pod)
...
// 然后关闭所有探针
kl.probeManager.RemovePod(pod)
...
}
func (m *manager) StopLivenessAndStartup(pod *v1.Pod) {
...
// 初始化探针哈希对象
// 后续不同的探针都以该对象为基础生成 key
key := probeKey{podUID: pod.UID}
for _, c := range pod.Spec.Containers {
// 更新为当前容器名称
key.containerName = c.Name
// 这里只先关闭存活探针和启动探针
for _, probeType := range [...]probeType{liveness, startup} {
key.probeType = probeType
if worker, ok := m.workers[key]; ok {
// 停止 worker
worker.stop()
}
}
}
}
关闭 Pod 所有探针
终止 Pod 时,关闭 Pod 内的所有容器 (包括 init 容器) 关联的所有的探针,内部实现和关闭探针类似。
func (m *manager) RemovePod(pod *v1.Pod) {
...
// 初始化探针哈希对象
// 后续不同的探针都以该对象为基础生成 key
key := probeKey{podUID: pod.UID}
// 遍历所有容器
for _, c := range append(pod.Sepec.Containers, getRestartableInitContainers(pod)...) {
// 更新为当前容器名称
key.containerName = c.Name
// 关闭所有类型的探针
for _, probeType := range [...]probeType{readiness, liveness, startup} {
key.probeType = probeType
if worker, ok := m.workers[key]; ok {
// 停止 worker
worker.stop()
}
}
}
}
停止指定 Pod 关联的所有探针
定期清理状态异常的 Pod。
func (kl *Kubelet) HandlePodCleanups(ctx context.Context) error {
...
kl.probeManager.CleanupPods(possiblyRunningPods)
...
}
func (m *manager) CleanupPods(desiredPods map[types.UID]sets.Empty) {
...
for key, worker := range m.workers {
// 这里就体现出使用结构体作为 map key 的优势了
// 可以通过任意组合来适应更多场景
if _, ok := desiredPods[key.podUID]; !ok {
worker.stop()
}
}
}
探针 worker
上文中的源代码分析提到,探针的新增、关闭、停止方法中,最终的执行对象都是 worker,接下来一起来看下 worker 的定义和作用。
探针 worker 就是负责具体执行检测的对象,每个 worker 专注于一件事: 定时执行检测某个 Pod 中的某个容器的某个探针,
在调用方,每个 worker 都会在一个独立的 goroutine 中运行。
type worker struct {
// 探针终止信号 channel
stopCh chan struct{}
// 手动触发探针的信号 channel
manualTriggerCh chan struct{}
// worker 关联的 Pod (只读)
pod *v1.Pod
// worker 关联的容器 (只读)
container v1.Container
// worker 关联的探针 (只读)
spec *v1.Probe
// 探针类型
probeType probeType
// worker 关联的管理器
probeManager *manager
...
}
创建 worker
newWorker 方法根据指定参数 (Pod + 容器 + 探针类型) 初始化一个 worker 对象并返回。
func newWorker(m *manager, probeType probeType, pod *v1.Pod, container v1.Container) *worker {
w := &worker{
stopCh: make(chan struct{}, 1), // channel 的缓冲区设置 1 (非阻塞)
manualTriggerCh: make(chan struct{}, 1), // channel 的缓冲区设置 1 (非阻塞)
pod: pod, // worker 关联 Pod
container: container, // worker 关联容器
probeType: probeType, // worker 关联探针类型
probeManager: m, // worker 关联管理器
}
// 根据不同的探针类型,关联不同的探针
switch probeType {
case readiness:
...
case liveness:
...
case startup:
...
}
...
return w
}
运行 worker
worker.run 方法内部会定时调用 worker.doProbe 方法来执行探针检测。
func (w *worker) run() {
...
// 检测定时器
probeTicker := time.NewTicker(probeTickerPeriod)
...
// 无限循环
probeLoop:
for w.doProbe(ctx) {
select {
// 如果接收到终止信号,直接退出
case <-w.stopCh:
break probeLoop
// 等待检测定时器再次触发
case <-probeTicker.C:
case <-w.manualTriggerCh:
// continue
}
}
}
执行检测
worker.doProbe 方法是执行探针检测的核心方法,内部会按照探针类型执行对应的检测并记录结果,最后返回 worker 是否应该继续执行。
func (w *worker) doProbe(ctx context.Context) (keepGoing bool) {
...
startTime := time.Now()
// 如果 Pod 还未创建或者已经被删除
// 直接返回
status, ok := w.probeManager.statusManager.GetPodStatus(w.pod.UID)
if !ok {
...
return true
}
// 如果 worker 关联的 Pod 已经终止,那么 worker 也应该终止
if status.Phase == v1.PodFailed || status.Phase == v1.PodSucceeded {
...
return false
}
// 如果 worker 关联的容器还未创建或者已经被删除
c, ok := podutil.GetContainerStatus(status.ContainerStatuses, w.container.Name)
if !ok || len(c.ContainerID) == 0 {
...
return true
}
// 容器重启之后,继续探针检测
if w.containerID.String() != c.ContainerID {
w.containerID = kubecontainer.ParseContainerID(c.ContainerID)
w.resultsManager.Set(w.containerID, w.initialValue, w.pod)
}
// 容器 正在重启中 不执行探针检测
if w.onHold {
return true
}
// 容器状态不是运行中
if c.State.Running == nil {
...
return c.State.Terminated == nil ||
w.pod.Spec.RestartPolicy != v1.RestartPolicyNever
}
...
// 延迟执行探针检测
if int32(time.Since(c.State.Running.StartedAt.Time).Seconds()) < w.spec.InitialDelaySeconds {
return true
}
...
// 执行探针检测
result, err := w.probeManager.prober.probe(ctx, w.probeType, w.pod, status, w.container, w.containerID)
...
// 如果检测结果和之前的结果一致,增加累计值
if w.lastResult == result {
w.resultRun++
} else {
// 如果检测结果和之前的结果不相同,重置累计值
w.lastResult = result
w.resultRun = 1
}
// 检测失败了,但是失败次数低于阈值次数
// 或者
// 检测成功了,但是成功次数低于阈值次数
// 上述两种情况,不需要更新 Pod 状态,直接返回,进入下一次检测即可
if (result == results.Failure && w.resultRun < int(w.spec.FailureThreshold)) ||
(result == results.Success && w.resultRun < int(w.spec.SuccessThreshold)) {
return true
}
// 更新容器的检测结果状态
w.resultsManager.Set(w.containerID, result, w.pod)
// 如果当前 worker 的探针类型是 [启动探针 或者 存储探针]
// 那么当探针检测失败时,需要重启 worker 关联的容器
// 此时标识容器状态为 {正在重启中}
if (w.probeType == liveness || w.probeType == startup) && result == results.Failure {
w.onHold = true
w.resultRun = 0
}
return true
}
通过上面的源代码分析,我们可以看到,执行探针检测最终是通过调用 prober.probe 方法来完成的。
const maxProbeRetries = 3
func (pb *prober) probe(ctx context.Context, ...) (...) {
var probeSpec *v1.Probe
// 确定探针类型
switch probeType {
case readiness:
probeSpec = container.ReadinessProbe
case liveness:
probeSpec = container.LivenessProbe
case startup:
probeSpec = container.StartupProbe
default:
return results.Failure, fmt.Errorf("unknown probe type: %q", probeType)
}
...
result, output, err := pb.runProbeWithRetries(ctx, ..., maxProbeRetries)
...
}
prober.probe 方法内部又调用了 prober.runProbeWithRetries 方法:
func (pb *prober) runProbeWithRetries(ctx context.Context, ..., retries int) (...) {
...
// 检测最终尝试 3 次
for i := 0; i < retries; i++ {
// 内部调用 runProbe 方法
result, output, err = pb.runProbe(ctx, ...)
if err == nil {
// 只要有一次检测成功,直接返回即可
return result, output, nil
}
}
return ...
}
最后就是 prober.runProbe 方法了,内部通过不同类型的探针执行不同的方法,最后返回本地探针检测结果。
各种类型探针判定检测条件如下:
| 探针类型 | 成功 |
|---|---|
| exec | 执行 code 等于 0 |
| HTTP | StatusCode >= 200 && StatusCode < 400 |
| TCP | 成功建立连接 |
| gRPC | 返回 SERVING 状态 |
func (pb *prober) runProbe(ctx context.Context, ...) (...) {
// 探针检测超时时间
timeout := time.Duration(p.TimeoutSeconds) * time.Second
// exec (shell) 类型探针
if p.Exec != nil {
command := kubecontainer.ExpandContainerCommandOnlyStatic(p.Exec.Command, container.Env)
return pb.exec.Probe(pb.newExecInContainer(ctx, container, containerID, command, timeout))
}
// HTTP 请求类型探针
if p.HTTPGet != nil {
req, err := httpprobe.NewRequestForHTTPGetAction(p.HTTPGet, &container, status.PodIP, "probe")
return pb.http.Probe(req, timeout)
}
// TCP 类型探针
if p.TCPSocket != nil {
port, err := probe.ResolveContainerPort(p.TCPSocket.Port, &container)
return pb.tcp.Probe(host, port, timeout)
}
// gRPC 请求类型探针
if p.GRPC != nil {
host := status.PodIP
return pb.grpc.Probe(host, service, int(p.GRPC.Port), timeout)
}
return ...
}
小结
