Kubernetes Job 设计与实现
2024-01-02 Cloud Native Kubernetes 读代码
概述
Job 会创建一个或者多个 Pod,并在 Pod 执行失败时继续重试,直到指定数量的 Pod 执行成功。
Job 的使用方法和最佳实践在 这篇文章 中已经介绍过了,这里不再赘述,本文着重从源代码的角度分析一下 Job 的实现原理。
示例
# 官方示例 controllers/job.yaml
# 计算圆周率
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
completions: 3
parallelism: 1
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
基于 YAML 文件创建 Job:
$ kubectl apply -f https://kubernetes.io/examples/controllers/job.yaml
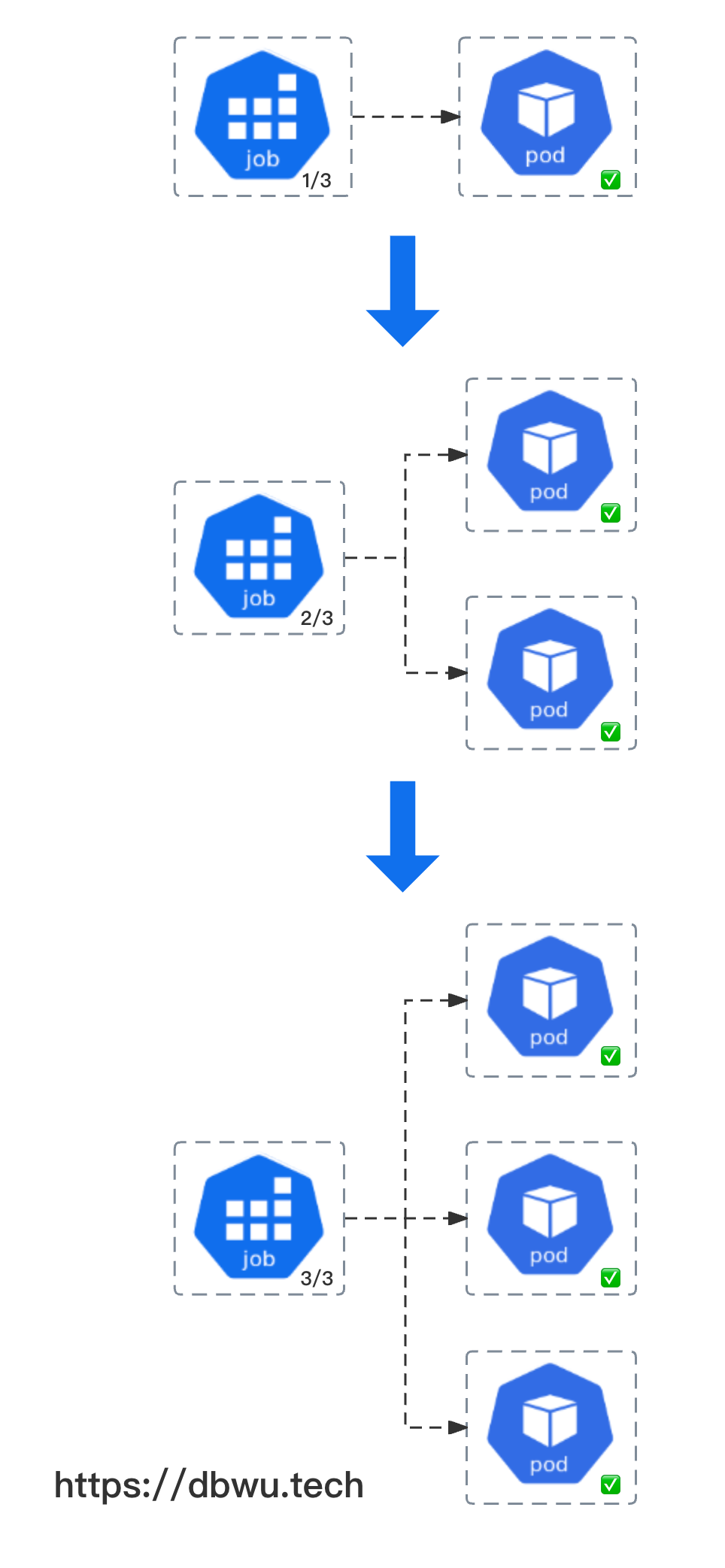
在 Kubernetes 中执行上面的代码后,会创建一个包含容器 pi 的 Pod, 因为声明了配置参数 spec.completions = 3, 所以该 Job 需要等待 3 个 Pod 成功执行,
另外一个配置参数 spec.parallelism = 1 表示并行的 Pod 数量为 1, 也就是 Pod 需要挨个执行,一个 Pod 成功执行后,才可以开始执行下一个 Pod。
源码说明
本文着重从源代码的角度分析一下 Job 的实现原理,Job 功能对应的源代码位于 Kubernetes 项目的 pkg/controller/job/ 目录,本文以 Kubernetes v1.28 版本源代码进行分析。
流程图
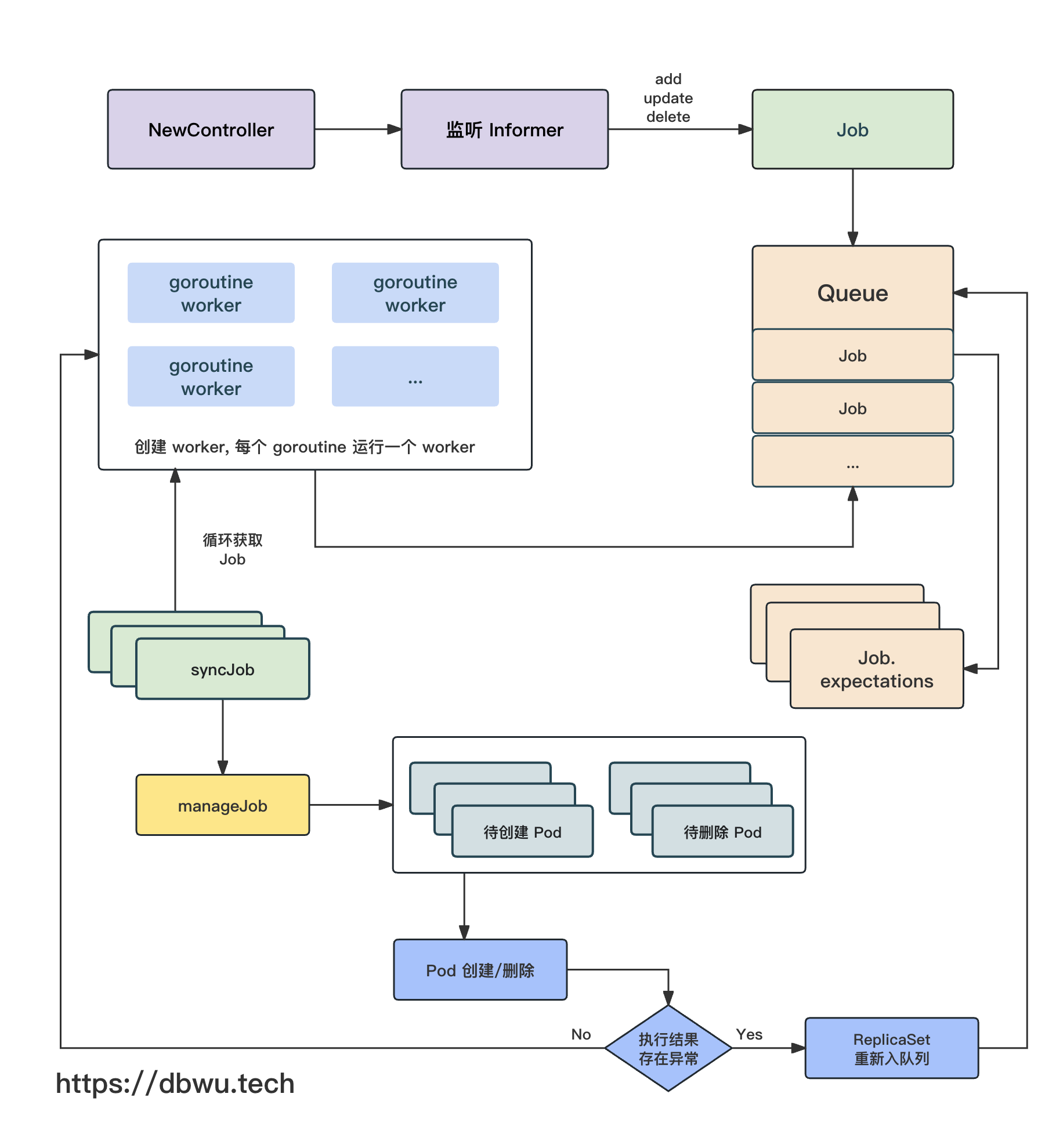
下面我们跟着流程图一起看下源代码的具体实现。
JobController
首先来看看 Controller 控制器对象,该对象是实现 Job 功能的核心对象。
// Controller 保证所有的 Job 对象关联的 Pod 执行满足期望状态
type Controller struct {
// kubelet 客户端对象
// 用于执行各项类似 "kubectl ..." 操作
kubeClient clientset.Interface
// Pod 操作对象
// 用于对 Pod 进行各项操作,例如创建/删除 等
podControl controller.PodControlInterface
// 同步回调方法
// 同时方便在单元测试中注入 Mock
syncHandler func(ctx context.Context, jobKey string) error
// 缓存对象
// 记录每个 Job 需要创建/删除的 Pod
// 每轮同步过程中,对于 创建/删除 操作失败的 Pod 数量,都会记录起来
// 等到下一轮同步时继续执行相关的操作
expectations controller.ControllerExpectationsInterface
// Job 列表
jobLister batchv1listers.JobLister
// Pod 列表
podStore corelisters.PodLister
// 队列中存储发生了变化 (需要同步) 的 Job
queue workqueue.RateLimitingInterface
}
初始化
NewController 方法用于 Job 控制器对象的初始化工作,并返回一个实例化对象,作为一个基础方法,其内部又调用了 newControllerWithClock 方法。
func NewController(ctx context.Context, ...) (*Controller, error) {
return newControllerWithClock(ctx, ...)
}
func newControllerWithClock(ctx context.Context, ...) (*Controller, error) {
...
jm := &Controller{
...
}
// 增加 Job informer 监听回调方法
if _, err := jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
...
})
// 增加 Pod informer 监听回调方法
if _, err := podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
...
})
return jm, nil
}
启动控制器
根据控制器的初始化方法 NewController 的调用链路,可以找到控制器开始启动和执行的地方。
// cmd/kube-controller-manager/app/batch.go
func startJobController(ctx context.Context, ...) (controller.Interface, bool, error) {
jobController, err := job.NewController(
...
)
// 启动一个单独的 goroutine 来完成控制器的 {初始化 && 运行}
go jobController.Run(ctx, int(controllerContext.ComponentConfig.JobController.ConcurrentJobSyncs))
return nil, true, nil
}
Controller.Run 方法执行控制器具体的启动逻辑。
func (jm *Controller) Run(ctx context.Context, workers int) {
...
// (根据参数配置) 启动多个 goroutine 处理逻辑
for i := 0; i < workers; i++ {
go wait.UntilWithContext(ctx, jm.worker, time.Second)
}
<-ctx.Done()
}
Controller.worker 方法本质上就是一个无限循环轮询器,不断从队列中取出 Job 对象,然后进行对应的操作,内部无限循环调用 processNextWorkItem 方法。
func (jm *Controller) worker(ctx context.Context) {
for jm.processNextWorkItem(ctx) {
}
}
Controller.processNextWorkItem 方法的核心操作就是三板斧: 队列取对象 -> 对象同步 -> 对象放回队列。
func (jm *Controller) processNextWorkItem(ctx context.Context) bool {
// 从队列获取 Job 对象
key, quit := jm.queue.Get()
...
// 调用同步回调方法,默认也就是 syncJob 方法
err := jm.syncHandler(ctx, key.(string))
if err == nil {
// 如果同步回调方法执行正常
// 将当前 Job 对象踢出队列
jm.queue.Forget(key)
return true
}
// 如果同步回调方法执行异常
// 将当前 Job 对象重新放入队列
jm.queue.AddRateLimited(key)
return true
}
Job 同步
Controller 的回调处理方法默认就是 syncJob 方法,该方法是所有 Job 对象同步操作的入口方法。
func (jm *Controller) syncJob(ctx context.Context, key string) (rErr error) {
...
// 通过 key 解析出 Job 对象对应的 命名空间和名称
ns, name, err := cache.SplitMetaNamespaceKey(key)
// 获取 Job 对象
sharedJob, err := jm.jobLister.Jobs(ns).Get(name)
job := *sharedJob.DeepCopy()
...
// 检测 Job 对象是否需要同步
satisfiedExpectations := jm.expectations.SatisfiedExpectations(logger, key)
// 获取 Job 关联的 Pod 列表
pods, err := jm.getPodsForJob(ctx, &job)
...
// 获取 Job 执行成功 Pod 数量和执行失败 Pod 数量
newSucceededPods, newFailedPods := getNewFinishedPods(jobCtx)
var manageJobErr error
// 如果 Job 设置了 JobPodFailurePolicy
// Job 控制器不会将正在终止过程中的 Pod 看作失效 Pod,直到该 Pod 完全终止,返回执行成功或执行失败
// 显而易见
// 如果 Pod 执行成功了,根据 Job 的剩余执行次数确定是否启动 Pod 执行
// 如果 Pod 执行失败了,Job 控制器会启动一个新的 Pod 继续执行 Job
if feature.DefaultFeatureGate.Enabled(features.JobPodFailurePolicy) {
...
}
// 接下来会进行一些异常状态检测
// 例如:
// Pod 的失败执行次数是否超过限制
// Pod 的运行时间是否超时
// 限于篇幅,这里不做具体的分析
// 如果 Job 执行失败了
// 删除 Job 关联的正在执行的 Pod
if jobCtx.finishedCondition != nil {
...
} else {
manageJobCalled := false
// 如果 Job 还未被删除
// 并且
// Job 正好需要同步
if satisfiedExpectations && job.DeletionTimestamp == nil {
// 调用 manageJob 方法执行具体吗的操作
active, action, manageJobErr = jm.manageJob(ctx, &job, jobCtx)
manageJobCalled = true
}
// Job 执行结果状态标识位置
complete := false
if job.Spec.Completions == nil {
// 如果 Job 没有设置 Completions 数量
// 那么只要有任意一个 Pod 执行成功
// Job 的状态就算是执行成功
complete = jobCtx.succeeded > 0 && active == 0
} else {
// 如果 Job 设置了 Completions 数量
// 只有执行成功的 Pod 数量大于等于 Completions 数量
// Job 的状态才可以算是执行成功
complete = jobCtx.succeeded >= *job.Spec.Completions && active == 0
}
if complete {
// 如果 Job 执行成功
// 更新 Job 的相关状态
} else if manageJobCalled {
// 如果 Job 执行失败
// 更新 Job 的相关状态
}
}
...
return manageJobErr
}
通过 Controller.syncJob 方法的源代码,我们可以看到: Job 对象每次同步时,都会执行如下的操作:
- 根据参数 key 获取指定的 Job 对象
- 检测 Job 对象是否需要同步
- 获取所有 Pod 列表
- 执行一些 Job 执行前的异常状态检测
- 调用 manageJob 方法执行具体的操作
- 根据 manageJob 方法的执行结果更新对应状态
其中,SatisfiedExpectations 方法在 ReplicaSet 实现原理一文中已经做过分析,本文不再赘述。
执行 Pod 创建/删除
Controller.manageJob 方法根据 Job.spec 中指定的配置管理 Pod 的运行环境和数量,然后执行对应的 Pod 创建/删除 操作,也就是负责具体干活的。
func (jm *Controller) manageJob(ctx context.Context, job *batch.Job, jobCtx *syncJobCtx) (int32, string, error) {
// 获取当前正在运行的 Pod 数量
active := int32(len(jobCtx.activePods))
// 获取 Job 的并行数量配置
parallelism := *job.Spec.Parallelism
// 如果 Job 没有设置 Completions 数量
if job.Spec.Completions == nil {
// 如果已经有 Pod 成功执行
// Pod 的并行数量就以 {正在运行的 Pod 数量} 为准
// 否则 Pod 的并行数量就以 {parallelism 参数数量} 为准
...
} else {
// 如果 Job 设置了 Completions 数量
// Pod 的并行数量就以 {parallelism 参数数量} 为准
...
}
rmAtLeast := active - wantActive
if rmAtLeast < 0 {
rmAtLeast = 0
}
// 计算需要删除的 Pod 列表 (多余的 Pod)
// 有多余的 Pod, 说明当前的 Pod 并行数量满足条件
podsToDelete := activePodsForRemoval(job, jobCtx.activePods, int(rmAtLeast))
if len(podsToDelete) > MaxPodCreateDeletePerSync {
podsToDelete = podsToDelete[:MaxPodCreateDeletePerSync]
}
if len(podsToDelete) > 0 {
// 当前并行的 Pod 数量已经足够了
// 更新 Job 的状态后直接返回
return active, metrics.JobSyncActionPodsDeleted, err
}
// 需要启动新的 Pod 来满足 Job 的并行数量
// 例如
// 当前正在运行的 Pod 数量为 6
// Job 的并行数量配置为 10
// 那么就需要再启动 4 个新的 Pod
if diff := wantActive - terminating - active; diff > 0 {
...
// 获取要创建的 Pod 模板
podTemplate := job.Spec.Template.DeepCopy()
// 初始化 Pod 创建成功数量,Pod 创建失败数量
var creationsSucceeded, creationsFailed int32 = 0, 0
// 开始批量创建 Pod
// 每次创建成功后,下一轮创建的 Pod 数量以指数级进行增长 (1, 2, 4, 8 ...)
// 参考了 TCP 的 “慢启动” 方式
// 还是熟悉的配方,还是熟悉的味道
// 这部分内容在 {DaemonSet, ReplicaSet 实现原理} 两篇文章都讲过
// 为了节省篇幅和时间,这里不再赘述了,仅留出几个关键条件分支代码
for batchSize := ...; diff > 0; batchSize = ... {
wait.Add(int(batchSize))
for i := int32(0); i < batchSize; i++ {
...
go func() {
...
}()
}
wait.Wait()
...
diff -= batchSize
}
...
}
// 返回创建 Pod 操作的执行结果
return active, metrics.JobSyncActionTracking, nil
}
小结
