降本增效之应用优化 (三) 日志存储与检索
背景
本文接着前两篇 “降本增效” 系列文章,复盘一下在业务系统中的日志功能优化。
笔者所在业务线,老的日志查询功能依赖于一套 EFK 集群,该集群除了作为日志查询分析之外,还作为另外一条已经阵亡的产品线的搜索模块,
但是当对应的产品和运维人员都被优化掉之后,这套集群就只是作为日志查询,于是一个降本增效的优化目标又有了 (最主要的问题是负责该集群的运维同事也被优化了,没人维护了)。
如无特殊说明,本文中云服务商均指阿里云 (毕竟刚收到一波代金券)。
优化目标
- 降低集群配置甚至直接去掉集群,降低云服务资源费用
- 从按年付费开通集群,转换到按需付费模式,提升业务 (公司) 的现金流
- 自动化管理,无需运维介入工作 (
主要是也没有运维人员了) - 不同的环境 (开发/灰度/生产) + 不同的服务组合,可以使用单独的日志仓库进行存储和查询,做到应用层无感知
- 日志采集和推送更符合 “云原生” 理念,可以更方便集成到 Kubernetes 中
优化之前
集群费用
涉及到公司的业务体制,优化之前的集群不方便截图,不过这里可以直接给一个阿里云普通 EFK 集群规模价格费用,直观地感受一下 “钞能力”。
这里以一个普通的 ElasticSearch 小集群为例来看看对应的价格:
| 规则 | 值 |
|---|---|
| 业务场景 | 日志存储与检索 |
| 数据节点 | 3 |
| CPU | 8 Core |
| 内存 | 32 GB |
| Kibana 看板 | 4 Core 16 GB |
| 磁盘 | 2 TB SSD |
上述配置一年的价格将近 19 万。
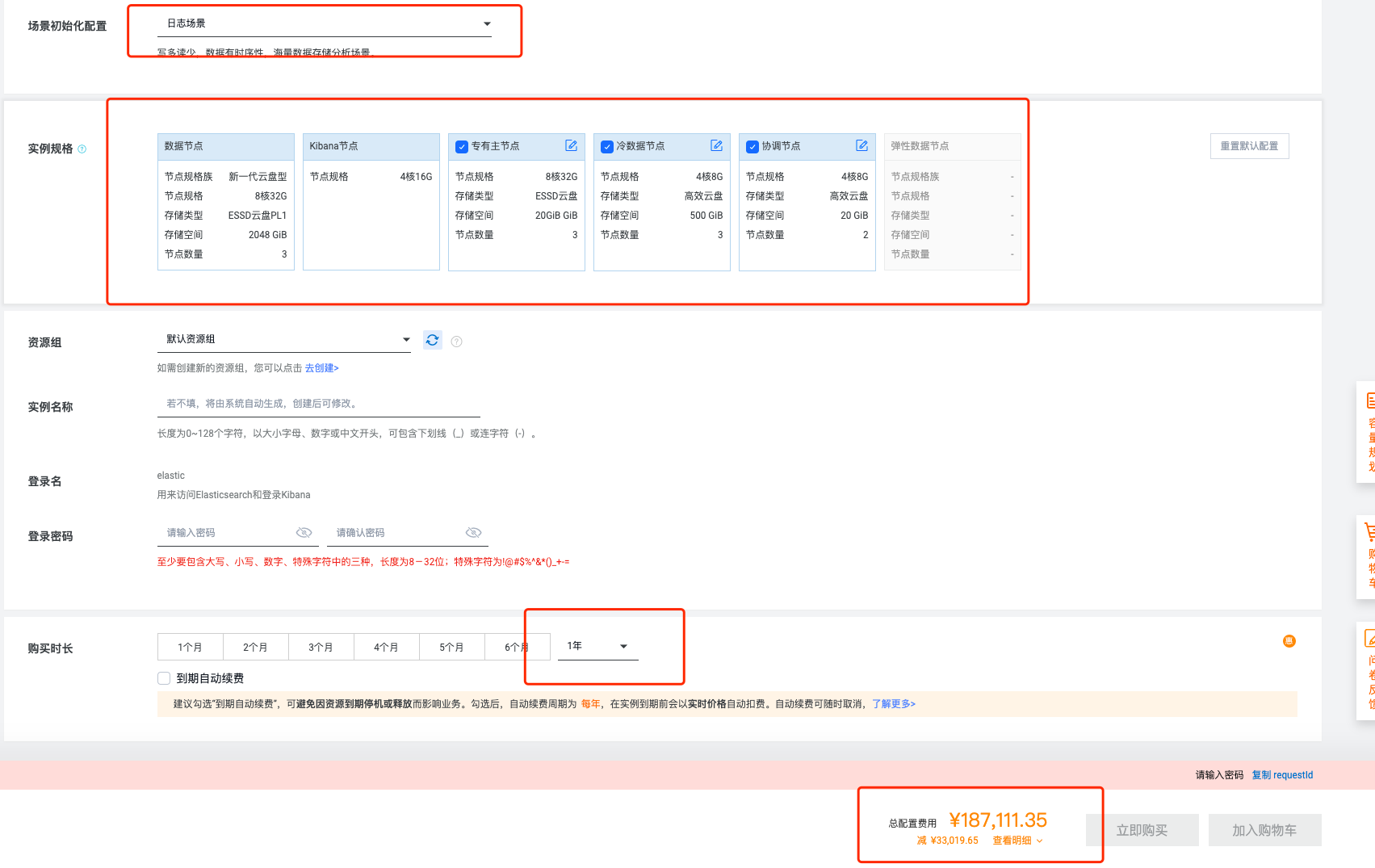
此外,因为 Kubernetes 中的服务 (Pod) 日志要先传送到 Kafka 等 MQ 作为中转, 然后再转到 ElasticSearch,所以这里还需要加几个 Kafka 实例的费用,日志的数据流大概如下图所示。
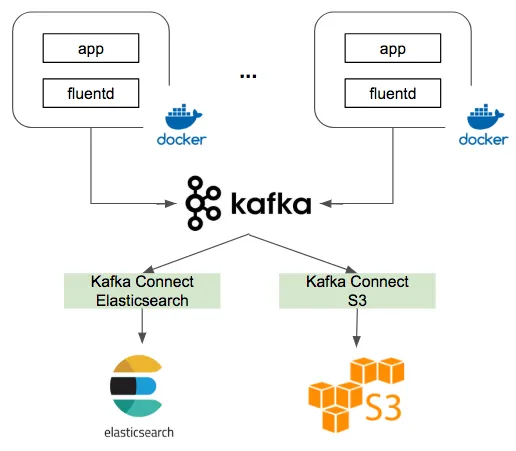
粗略地计算下来,使用 ElasticSearch + Kafka + Kibana 这套技术栈作为日志存储与检测服务,一年的云服务费用大概在 25 万左右,这是单单硬件的费用。
技术维护
除了硬件之外,还需要软件的维护费用,包括从日志收集、转发、检索配置、服务可用、数据归档等开发运维工作量,转换为成本也就是人员工资。
优化方案
仔细分析上面的问题之后,其实核心就是要解决两个问题: 硬件成本 + 运维费用,因为公司所有业务都是微服务 + Kubernetes 架构体系,同时使用阿里云作为服务厂商,
要想短期内取得 “脚本增效” 收益并取得可见的效果,显然最好的方案就是站在巨人的肩膀上,避免自己造轮子 (主要确实也没有足够的人力来造轮子)。
笔者遇到的问题,自然也有很多人都会遇到,大家都会遇到的问题,自然会被云计算服务商的产品经理定位为共性问题,最后对应的产品经过抽象和包装,自然也就应运而生了。
一站式日志服务
最终笔者将目标锁定在阿里云提供的开箱即用日志应用 SLS, 下面是官方对 SLS 的介绍。
日志服务 (Simple Log Service,简称 SLS) 是云原生观测分析平台,为 Log/Metric/Trace 等数据提供大规模、低成本、实时平台化服务。 一站式提供数据采集、加工、分析、告警可视化与投递功能,全面提升研发、运维、运营和安全等场景数字化能力。
优化方案确定之后,迁移的过程还是比较快的,从测试 -> 灰度 -> 生产全面部署,花了 3 周的时间,期间经历了如下工作:
- 开通 SLS 日志服务
- 创建日志项目,并且关联到对应的 Kubernetes 集群
- 创建 测试/灰度/生产 不同环境下的的日志仓库,配置仓库的数据分片、数据存储时长等
- 设置单个服务 (数据源) 对应的具体日志仓库
- 确认服务 (例如 Deployment) 的日志是否正常传输到对应的日志仓库
- 配置日志仓库的数据预处理 (例如 JSON 数据序列展开)
- 配置日志仓库的报警提示
- 开启日志仓库中的全文索引
- 删除日志从收集 -> 中转 -> ElasticSearch 路径中弃用的运维配置
- 释放闲置的 Kafka 实例
- 释放闲置的 ElasticSearch 服务
因为涉及到公司的具体业务,迁移细节本文就不详细描述了,考虑清楚整个日志数据流的变化,整体过程还是非常顺利的。
优化之后
优化之后的日志数据流如下图所示。
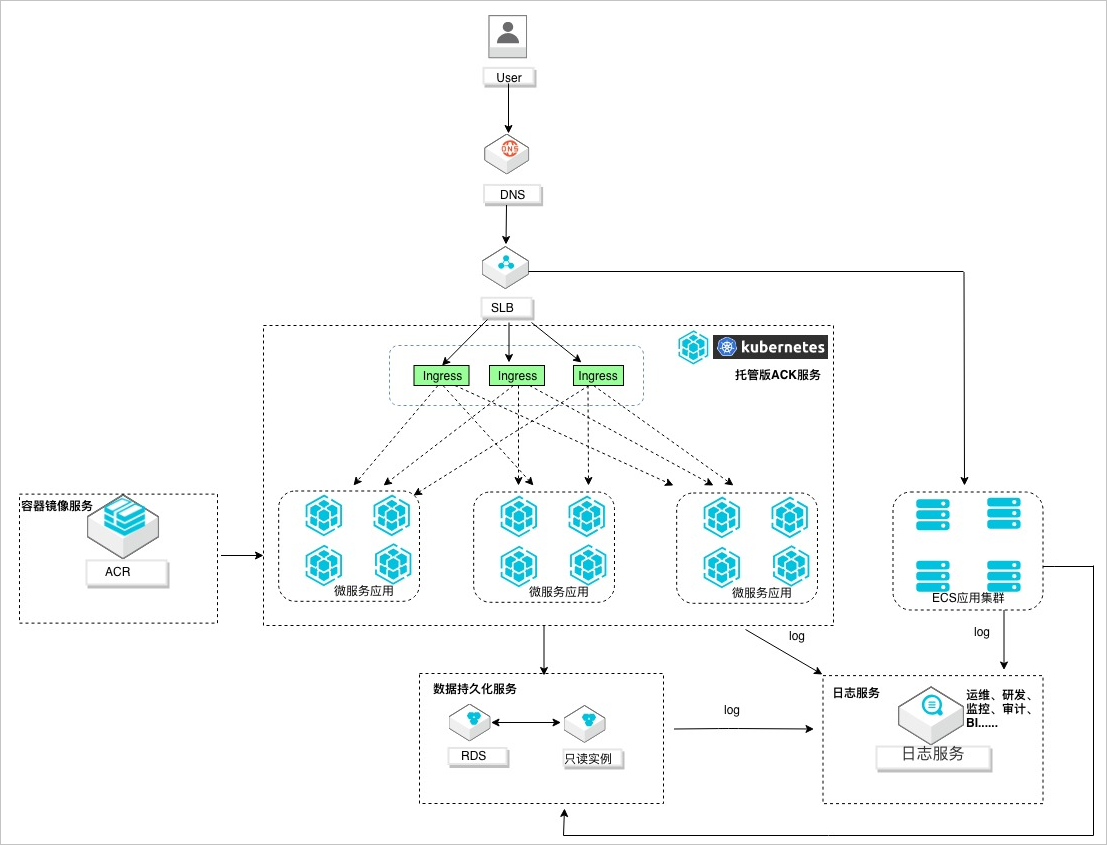
接着对比一下优化前后的费用,看看具体的效果。
服务费用
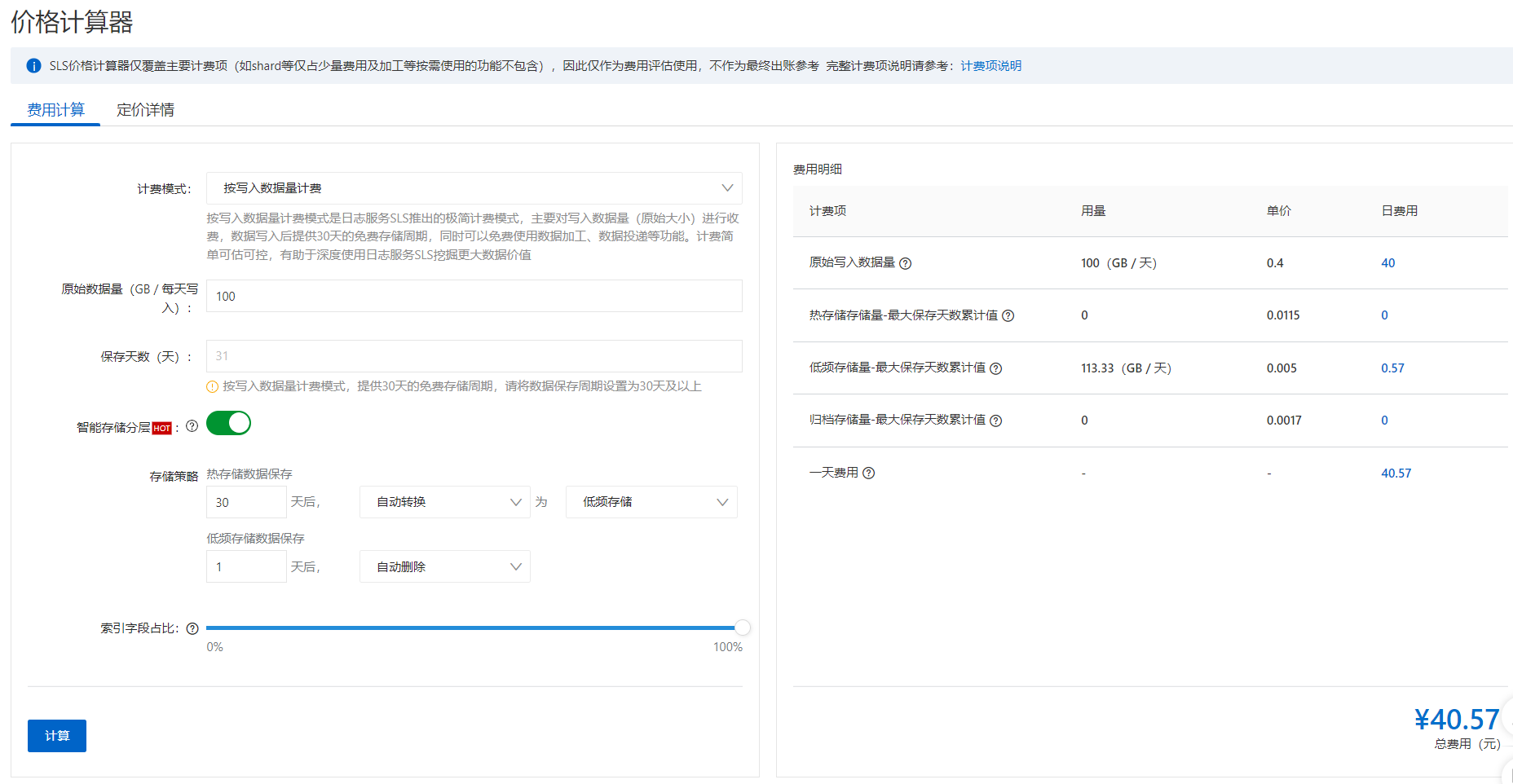
这里以前文中对应的 ElasticSearch 集群规模为样本,计算一下使用 SLS 日志服务的对应的价格,日志服务配置如下:
- 按量计费
- 每日写入日志数据量 100 GB
- 保存数据周期为 31 天
- 开启冷热数据分离
- 开启日志数据结构的全文索引
技术维护
运维成本几乎为 0, 只需要创建仓库并且在 Kubernetes 中的 Deployment 设置日志仓库数据源即可,而且无需担心服务性能、可用性问题,并且还有很多开箱即用的数据处理插件,真正实现 “降本增效”。

小结
采用 SLS 日志服务之后,单纯的日志存储与检索即使按年来计算也就在 2000 左右,乍一看,日志服务的成本似乎节省优化了 100 倍,但是与此同时也付出了必要的代价:
- 去掉了 ElasticSearch 服务,很多搜索功能无法实现了,如果后期再开启新的业务,还是需要重新购置服务的
- 日志功能完成集成到了云服务计算厂商中,深度绑定
但是好在前文中设定的 5 个优化目标全部完成,又是一次软件设计的 trade off 之旅。
优化工作的本质是面向收益编程。
一篇复盘文章,感觉硬生生地写成了一篇软文?话说回来,日志功能改造完成之后,业务技术栈中 Java 的比例越来越低,感觉在不归路上越走越远 :-)

